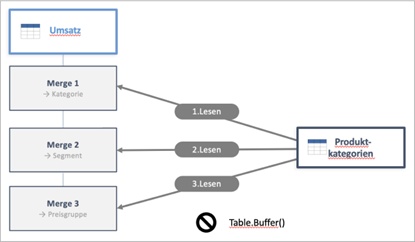
In Power Query ist der Merge die erste Wahl, wenn zwei Tabellen kombiniert werden sollen. Doch bei großen Datenmengen und Datenquellen, die kein Query Folding unterstützen, kann er zum echten Performance-Problem werden. Woran liegt das – und was kann man dagegen tun? 🤔
In dieser Session sehen wir uns praxisnah an, welche cleveren Alternativen zum Standard-Merge es gibt – und wann welche Methode die richtige Wahl ist. Du erfährst, warum Merges in Power Query oft langsamer sind als erwartet, welche Strategien das Problem bereits im Ansatz vermeiden und wie du mit gezieltem M-Code die Performance deutlich verbessern kannst.
An einem konkreten Beispiel beleuchten wir:
👉 Warum Power Query Lookup-Tabellen manchmal mehrfach lädt – und wie du das mit einer einzigen Zeile Code stoppst
👉 Wie du einen Wert aus einer Lookup-Tabelle nachschlägst, ohne überhaupt einen Merge zu brauchen
👉 Wie du aus einer großen Tabelle nur die Zeilen behältst, die auf einer bestimmten Liste stehen – ohne Umwege und ohne dass der Bericht dabei langsamer wird
👉 Wie Power Query zwei große Tabellen effizient zusammenführen kann, ohne dabei den Arbeitsspeicher zu überlasten – und wann diese Technik funktioniert
👉 Eine klare Entscheidungshilfe: Wann welche Methode – und wann doch der klassische Merge?
Ziel dieser Session ist es, dir ein konkretes Werkzeugset an die Hand zu geben: Du verstehst nicht nur, warum Merges langsam werden können, sondern weißt danach genau, welche Alternative in deinem konkreten Anwendungsfall die beste Wahl ist.
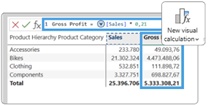
Das ist eine spannende und vor allem tolle Neuerung in Power BI! Visual Calculations ermöglichen einen vereinfachten Zugang zur DAX Formelsprache. Die Eingabe erfolgt excel-ähnlich direkt in einem Visual – also unmittelbar neben den Zahlen – und die Berechnung erfolgt direkt im Visual nach dem Prinzip „What you see is what you get“.
Gleichzeitig lassen sich damit auch sehr anspruchsvolle Berechnungen mit neuen, einfach zu verwendenden DAX Funktionen realisieren. Beispielsweise die ABC Klassifikation oder eine Pareto Visualisierung, die bisher nur mit sehr viel DAX Know-How schaffbar waren.
In Microsoft Power BI entscheidet das Datenmodell über Performance, Verständlichkeit und Wartbarkeit Ihrer Berichte. Doch welches Modell ist das richtige? Star Schema, normalisiertes Schema oder doch alles in eine einzige Tabelle geben?
In dieser Session vergleiche ich mit Euch die drei gängigsten Modellierungsansätze praxisnah und verständlich. Du erfährst, wie sich ein Star Schema auf Performance und Benutzerfreundlichkeit auswirkt, wann ein normalisiertes Modell sinnvoll ist und welche Vor- und Nachteile eine One Big Table in Power BI mit sich bringt.
Anhand konkreter Beispiele beleuchten wir:
👉 Struktur und Prinzipien der jeweiligen Modellansätze
👉 Auswirkungen auf DAX, Filterkontext und Beziehungen
👉 Performance-Unterschiede und Speicherverhalten
👉 Wartbarkeit und Skalierbarkeit im Unternehmenskontext
👉 Typische Fehler und Missverständnisse
Ziel des Vortrags ist es, Ihnen ein klares Entscheidungsframework an die Hand zu geben: Wann eignet sich welcher Ansatz – und warum ist das Star Schema in Power BI die empfohlene Best Practice? Nach dieser Session verstehst Du nicht nur die Unterschiede, sondern kannst fundiert entscheiden, wie Du Deine eigenen Datenmodelle strukturieren sollst.

Welche Herausforderungen stecken hinter einer sauberen P&L-Darstellung in Power BI – und wie löst du sie mit den Mitteln, die du ohnehin schon hast? In dieser Session zeigt Renate praxisnah, wie du eine professionelle P&L direkt mit Core Visuals umsetzt – ganz ohne Spezial-Visual, ganz ohne teure Add-ons.
Du erfährst, wie du asymmetrische Hierarchien, Zwischensummen und komplexe Spaltenstrukturen so modellierst, dass deine P&L betriebswirtschaftlich stimmt – und gleichzeitig gut aussieht. 😊
An einem konkreten Beispiel beleuchten wir:
👉 Wie du eine Matrix für P&L-Berichte Schritt für Schritt zur funktionierenden P&L-Ansicht aufbaust
👉 Wie du mit DAX Measures die drei größten P&L-Hürden löst: asymmetrische Hierarchien, Zwischensummen und %-Berechnungen
👉 Wie du mit einer Matrix eine P&L in Power BI nachbaust
👉 Wie du mit einer Calculation Group eine klassische MTD/YTD-Spaltenstruktur mit Ist, Vergleich und Abweichung (absolut & prozentual) abbildest
👉 Was dabei in der Praxis wirklich funktioniert, wo die Grenzen der Core Visuals liegen und wann sich ein spezialisiertes Visual lohnt
Ziel dieser Session ist es, dir eine solide Grundlage zu geben, mit der du P&L-Reports in Power BI selbst aufbauen und verstehen kannst – nicht irgendwann, sondern direkt ab dem nächsten Tag.
SVGs sind (häufig kleine) Bilder, die Du direkt mit einem Befehl erzeugst und daher sehr dynamisch gestalten kannst. Beispielsweise kannst Du in einem Projektcontrolling den Projektstatus anstelle eines einfachen Textes als optisch ansprechendes Label ausgeben. In Power BI erzeugen wir diese SVGs mit DAX Formeln in einem Measure oder eine Calculated Column – der Input wie der Beschriftungstext kommt aus unserem Datenmodell und das Layout aus der Formel.
Mit UDFs – User defined functions – können wir wiederkehrende DAX Logikbausteine zentral als Funktionen definieren und dann in beliebig vielen Measures oder Calculated Columns aufrufen.
Da die DAX Befehle zur Erzeugung von SVGs häufig sehr lang sind und in vielen Measures ähnliche oder sogar die gleichen DAX Statements wiederholt werden müssten, sind UDFs eine tolle Möglichkeit, die Visualisierungslogik in Eurer Power BI Anwendung zentral zu hinterlegen und möglichst kein DAX wiederholen zu müssen.

Microsoft Power BI ist weit mehr als ein reines Reporting-Tool – in Kombination mit R und Python wird es zur leistungsfähigen Advanced-Analytics-Plattform.
In dieser Session zeige ich, wie sich R- und Python-Visuals gezielt in Power BI einsetzen lassen, um statistische Analysen, Machine-Learning-Modelle und individuelle Visualisierungen direkt in Berichte zu integrieren. Du erfährst, wie Daten aus dem Power-BI-Datenmodell an Skripte übergeben werden, welche Architektur im Hintergrund wirkt und wo die technischen Grenzen liegen.
Themen der Session:
👉 Integration von R- und Python-Skripten in Power BI
👉 Erstellung individueller Visuals und statistischer Auswertungen
👉 Einsatz von Machine-Learning-Modellen im Reporting
👉 Typische Anwendungsfälle aus der Praxis
👉 Performance, Sicherheit und Governance-Aspekte
Ziel ist es, Ihnen ein klares Verständnis zu vermitteln, wann sich der Einsatz von R oder Python lohnt – und wie Du Advanced Analytics nahtlos in Deine bestehenden Power-BI-Reports integrieren kannst. Nach dieser Session weißt Du, wie Du über Standardvisualisierungen hinausgehen und analytischen Mehrwert direkt im Bericht erzeugen kannst.

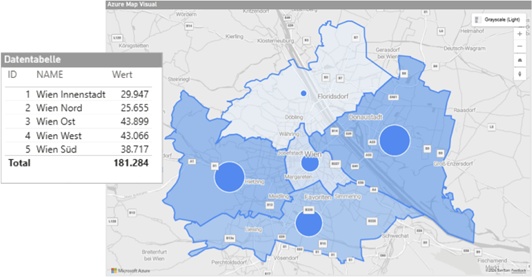
Das „Azure Map“ Visual löst ja die bisherigen beiden Core Visuals „Map“ und „Filled Map“ ab und sicher auch das seit endlosen Zeiten in Preview befindliche „Shape Map“ Visual.
Das Azure Map Visual bietet eine ganze Menge bekannter aber auch neuer Visualisierungsmöglichkeiten in Power BI:
👉 Bubbles, Clustered Bubbles und Donuts
👉 Marker
👉 3D Säulen
👉 Heat Map
👉 Flächen (Choropleth)
👉 Linien / Verbindungen
Dazu bietet das Azure Map Visual recht umfangreiche Einstellungsmöglichkeiten und auch die Möglichkeiten, externe „Tile Services“ – bspw. für Wetterdaten, geologische Beschaffenheit, usw. – in die Kartenvisualisierung einzubinden. Wie bei jeder Software gibt es auch Limitierungen, auch diese werden wir uns in dieser Session natürlich ansehen.
Die Wahl des richtigen Speicher- und Verbindungsmodus ist eine der wichtigsten Architekturentscheidungen in Microsoft Power BI. Performance, Datenaktualität, Modellierungsfreiheit und Governance hängen maßgeblich davon ab, ob Du Import, Live Connection, DirectQuery oder Direct Lake einsetzt.
In dieser Session vergleiche ich gemeinsam Euch die verschiedenen Ansätze systematisch und praxisnah. Du erfährst, wie sich die Modi technisch unterscheiden, welche Einschränkungen jeweils gelten und welche Auswirkungen sie auf DAX, Datenmodellierung, Sicherheit und Skalierbarkeit haben.
Im Fokus stehen:
👉 Architektur und Funktionsweise der einzelnen Modi
👉 Performance-Charakteristika und typische Engpässe
👉 Auswirkungen auf Datenaktualität und Refresh-Strategien
👉 Einsatzszenarien im Self-Service- und Enterprise-Umfeld
👉 Entscheidungsleitlinien für moderne Power-BI-Architekturen
Besonderes Augenmerk legen wir auf Direct Lake im Kontext von Microsoft Fabric und wie sich dieser Ansatz von klassischen DirectQuery- oder Import-Szenarien unterscheidet. Nach dieser Session bist Du in der Lage, fundiert zu entscheiden, welcher Verbindungsmodus für Dein konkretes Projekt die richtige Wahl ist.
Welche AI-Features stecken direkt im Power BI Desktop – und wie setzt du LLMs wie ChatGPT oder Claude so ein, dass sie dir im Alltag mit Power Query wirklich Zeit sparen? In dieser Session zeigt Renate praxisnah, welche AI-Möglichkeiten direkt im Power Query Editor stecken – ganz ohne Copilot, ganz ohne Fabric, mit dem Power BI Desktop, das du ohnehin schon verwendest.
Du erfährst, wie du mit cleveren Techniken unstrukturierte Daten schnell klassifizierst, bereinigst und anreicherst – und wie dir Large Language Models dabei helfen, M-Code schneller zu schreiben, zu verstehen und zu debuggen als je zuvor.
An konkreten Beispielen beleuchten wir:
👉 Wie ein verstecktes AI-Feature in Power Query aus wenigen Beispielwerten automatisch den richtigen M-Code ableitet und die meisten es noch nie bewusst genutzt haben
👉 Wie du ChatGPT, Claude & Co. als persönlichen M-Code-Assistenten einsetzt: Formeln generieren, Fehler erklären, komplexe Logik auf Knopfdruck und wie du damit deine Abfragen sauber dokumentierst
👉 Wie du API Services direkt in Power Query einbindest und damit Spalten mit Kundenfeedback, Kommentaren oder Freitext automatisch kategorisierst, analysierst und bereinigst – Zeile für Zeile, vollautomatisch
👉 Was dabei in der Praxis wirklich funktioniert, wo die Grenzen liegen und worauf du bei Datenschutz und Performance achten musst
Ziel dieser Session ist es, dir konkrete Werkzeuge an die Hand zu geben, mit denen du deine tägliche Arbeit in Power Query mit AI gezielt optimierst – nicht irgendwann, sondern direkt ab dem nächsten Tag.
Mit den „Field Parameters“ steht ein extrem leistungsfähiges und unglaublich einfach nutzbares Instrument zur Verfügung, mit dem die Benutzer in einem Bericht die verwendeten Kennzahlen (= Measures) und/oder die verwendeten Dimensionsfelder (= Columns) mittels Slicer auswählen können.
Eingangs sehen wir uns die Alternativen zu den Field Parameters – nämlich der Measure Tabelle und den Bookmarks – an, um den Mehrwert der Field Parameters dann besser einschätzen zu können.
Mit den Field Parameters können jedenfalls folgende Aufgaben gelöst werden:
👉 Selektion des verwendeten Measures in einem Visual / Report
👉 Selektion der verwendeten Columns im Achsen-/Legendenbereich eines Visuals
👉 Selektion von Hierarchien im Achsenbereich eines Visuals
👉 Selektion der gezeigten Spalten in einem Tabellen Visual (= Measures und Columns)
Abschließend sehen wir uns natürlich auch die Grenzen und Limitierungen dieses Features an.
Du hast eine Tabelle mit Start- und Enddatum – aber du brauchst eine Zeile pro Tag? Genau dieses Pattern lösen wir in dieser Session. In dieser Session zeigt Renate, wie Du aus einem Datensatz mit Zeiträumen automatisch eine vollständige Liste einzelner Tagesdaten erzeugst – direkt in Power Query, ohne Umwege, ohne externe Tools.
Du erfährst, wie du mit ein paar gezielten Transformationsschritten aus einer kompakten Quelltabelle eine saubere, expandierte Tagesliste machst – die du direkt für Berichte und Analysen weiternutzen kannst.
An einem konkreten Beispiel beleuchten wir:
👉 Wie du aus einem einfachen Start- und Enddatum automatisch alle Tage dazwischen erzeugst
👉 Wie du das Ergebnis filtern kannst zum Beispiel nur Wochentage
👉 Wie du deine bestehende Tabelle so erweiterst, dass jeder Tag als eigene Zeile erscheint
👉 Wie du das Ergebnis in deinem Report einsetzt
Ziel dieser Session ist es, dir ein Lösungspattern an die Hand zu geben, dass du sofort in deiner eigenen Arbeit einsetzen kannst – egal ob Projektplanung, Urlaubslisten, Vertragsperioden oder Produktionsdaten.
Historisierte Stammdaten gehören zu den größten Herausforderungen in BI-Projekten: Wie lassen sich sich ändernde Kunden-, Produkt- oder Organisationsdaten korrekt und nachvollziehbar auswerten? In Microsoft Power BI erfordert der Umgang mit Slowly Changing Dimensions (SCD) ein durchdachtes Zusammenspiel aus Datenmodellierung, ETL-Logik und DAX.
In dieser Session lernst Du, wie unterschiedliche SCD-Typen (Typ 0, Typ 1 und Typ 2) funktionieren und wie sie sich in Power BI technisch sauber umsetzen lassen. Wir betrachten sowohl die Modellierung im Star Schema als auch die Auswirkungen auf Beziehungen, Filterkontext und Measures.
Im Fokus stehen:
👉 Grundlagen und Unterschiede der SCD-Typen
👉 Technische Umsetzung in Power BI (inkl. Datumslogik und Gültigkeitszeiträumen)
👉 Performance- und Speicheraspekte
👉 Typische Fehlerquellen bei historisierten Dimensionen
👉 Best Practices für Enterprise-Modelle
Anhand praxisnaher Beispiele erhältst Du ein klares Verständnis dafür, wann welcher SCD-Ansatz sinnvoll ist – und wie Sie historische Analysen korrekt, performant und wartbar in Power BI realisieren. Nach dieser Session bist Du in der Lage, Slowly Changing Dimensions strukturiert zu planen und sauber in Dein Datenmodell zu integrieren.

CoPilot ist die KI Unterstützung von Microsoft direkt in Power BI. Das interessante daran gegenüber anderen LLMs (ChatGPT, Claude, usw.) ist die starke Ausrichtung an der Zielgruppe „End User“ und natürlich die vollständige Integration ins Programm.
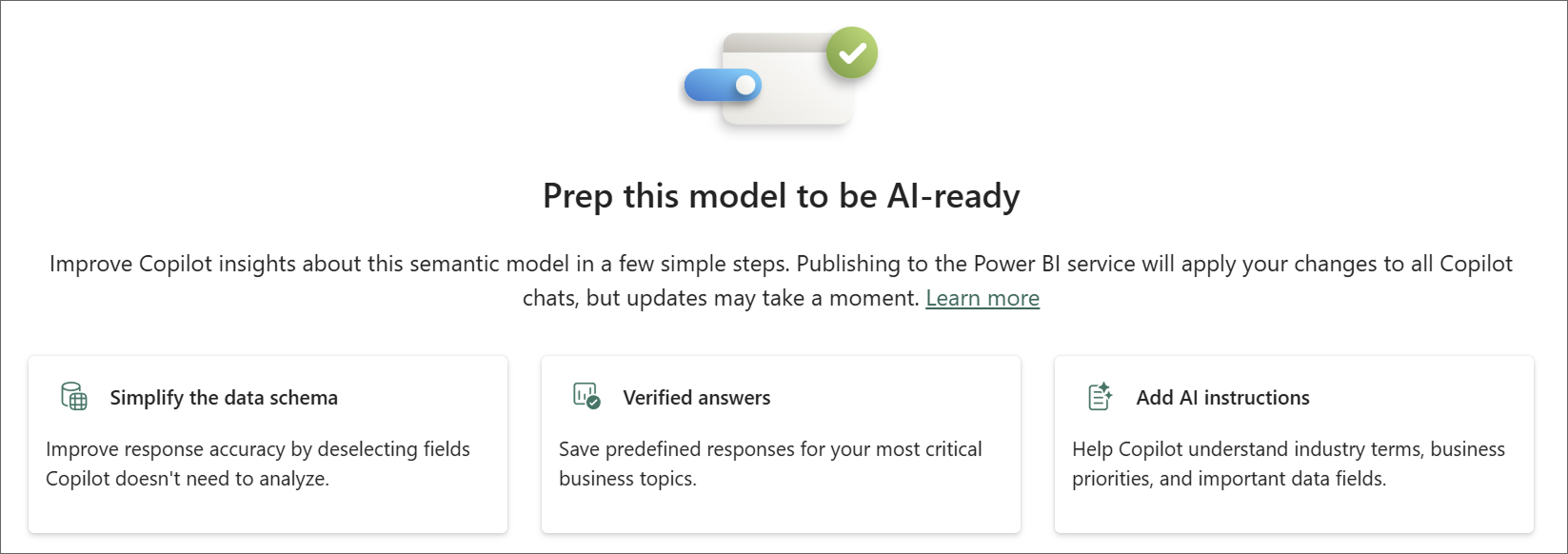
Damit CoPilot unseren End Usern – also den Managern und Informationskonsumenten in unseren Unternehmen – möglichst gute Antworten auf ihre Fragen liefern kann, braucht es zu allererst ein gutes und vor allem intuitives Datenmodell ohne komplizierte Ecken. Und im zweiten Schritt können wir unser Datenmodell mit der Funktion „PrepData for AI“ für die Abfrage mittels CoPilot optimieren.
PrepData for AI optimiert das Datenmodell in 3 Bereichen:
👉 Data Schema – sehr simpel und sehr effektiv, einfach für End User irrelevante Tabellen, Spalten und Measures für den CoPilot deaktivieren
👉 Verified Answers – vordefinierte Fragen auf Ebene des einzelnen Visuals, d.h. stellen Eure User diese Frage, dann bringt sie CoPilot zum definierten Visual
👉 AI instructions – der wahrscheinlich interessanteste Teil, hier kannst Du Glossare, Informationen zu Eurem Business, Saisonalität, geänderte Strukturen, usw. hinterlegen, damit CoPilot diese bei der Fragebeantwortung einbeziehen kann
Ziel dieser Session ist es, einen Eindruck von den Möglichkeiten zu bekommen, die CoPilot bietet, um adhoc Fragen Eurer Anwender möglichst gut zu beantworten.
Externe Tools erweitern die Möglichkeiten von Power BI erheblich – von effizienterer Modellierung über Performance-Optimierung bis hin zu DevOps- und Deployment-Szenarien.
Den Abschluss der beiden Tage bildet das Thema „Externe Tools in Power BI“. In dieser Session geben Renate, Robert und ich einen strukturierten Überblick über die wichtigsten externen Werkzeuge im Power-BI-Ökosystem und deren praktischen Mehrwert. Anhand konkreter Beispiele zeigen wir, wie Tools wie Tabular Editor, DAX Studio oder der ALM Toolkit Entwicklungsprozesse beschleunigen, Transparenz schaffen und die Qualität von Datenmodellen erhöhen.
Im Fokus stehen:
👉 Erweiterte Modellierung und Best-Practice-Checks
👉 Analyse und Optimierung von DAX-Abfragen
👉 Versionsvergleich und Deployment von Datenmodellen
👉 Automatisierung und professionelle Entwicklungsprozesse
👉 Governance- und Team-Szenarien im Enterprise-Umfeld
Ziel der Session ist es, zu zeigen, wie Du mit externen Tools von einem reinen Report-Ersteller zu einem strukturierten Power-BI-Entwickler wirst. Nach dieser Session kennst Du die wichtigsten Werkzeuge, deren Einsatzszenarien – und weißt, wie Du Deine Power-BI-Projekte effizienter, transparenter und professioneller gestalten kannst.