Power BI Desktop ist ein hervorragendes Tool, um die Datenmodelle für Dashboards, Reports und Analysen zu entwickeln. Für den Betrieb des Datenmodells ist der Power BI Service dann geeignet, wenn die aktuelle Größenbeschränkung nicht überschritten wird und die verfügbaren Aktualisierungsintervalle ausreichen. Seit 2019 sind auch die sogenannten Dataflows verfügbar, dabei handelt es sich technisch gesehen um eine Data Lake Lösung, die mittels Power Query Jobs befüllt wird.


Tabular Model – verfügbar als Serverlösung als auch als Azure Cloudservice – ist die bewährte Technologie, um skalierbare analytische Datenmodelle im Unternehmen umzusetzen. Tabular Model wird in der Regel für die Datenmodelle von Enterprise BI (und weniger für Self-Service-BI) Anwendungen eingesetzt, die Auswertung erfolgt mit den Frontends Power BI, Excel und Paginated Reports. Gegenüber dem Datamodel in Power BI ist eine Tabular Model Datenbank beliebig skalierbar, kann optional on-premise oder in der Cloud betrieben werden, kann in beliebigen Zeitintervallen aktualisiert werden und punktet mit weiteren wichtigen Enterprise Features.
Braucht es überhaupt noch ein Datawarehouse im Big Data und Analytics Zeitalter? Können nicht einfach auch die internen, gut strukturierten Daten in einen Data Lake “geworfen” werden?
 Unserer Einschätzung nach: nein. Auch wenn Big Data bedeutet, daß große unstrukturierte Datenmengen ausgewertet werden können, ist die Auswertung einer gut strukturierten Datenbasis der einer völlig unstrukturierten Datenbasis natürlich immer überlegen. Datawarehousing ist der gut durchdachte Einsatz einer standardisierten Datenstruktur, die dazu dient, heterogene Datenbestände möglichst strukturiert und relevanz-orientiert zu speichern sowie Stammdaten und Berechtigungen zentral zu organisieren. Inmon (1996) folgend ist ein Datawarehouse managementorientiert, zeitvariant, vereinheitlicht und für den Dauerbetrieb ausgelegt.
Unserer Einschätzung nach: nein. Auch wenn Big Data bedeutet, daß große unstrukturierte Datenmengen ausgewertet werden können, ist die Auswertung einer gut strukturierten Datenbasis der einer völlig unstrukturierten Datenbasis natürlich immer überlegen. Datawarehousing ist der gut durchdachte Einsatz einer standardisierten Datenstruktur, die dazu dient, heterogene Datenbestände möglichst strukturiert und relevanz-orientiert zu speichern sowie Stammdaten und Berechtigungen zentral zu organisieren. Inmon (1996) folgend ist ein Datawarehouse managementorientiert, zeitvariant, vereinheitlicht und für den Dauerbetrieb ausgelegt.
Daher werden die gut strukturierten und management-relevanten Daten aus den hauseigenen Quellsystemen auch in Zukunft in eine analytisch und betriebswirtschaftlich saubere Form gebracht – den Single-Point-of-Truth. Ein Datawarehouse kann zentral oder auch dezentral mit einzelnen Fachabteilungs-Datawarehouses umgesetzt werden, die dann zusammen den Single-Point-of-Truth bilden.
Unstrukturierte Daten hingegen werden in Data Lakes gesammelt, um diese insbesondere für Advanced Analytics Auswertungen nutzen zu können.
Das firmenspezifische Datenkonzept wird von den entsprechenden Fachbereichen im Unternehmen ausgearbeitet – wir begleiten Sie hier gerne mit moderierten Workshops. Das Datenkonzept beleuchtet einerseits den Kontext, in dem im Unternehmen analytische Daten gespeichert, verwendet und analysiert werden. Andererseits definiert das Datenkonzept die firmenspezifischen Rahmenbedingungen für die wesentlichen Gestaltungsthemen von relationalen und analytischen Datenmodellen. In BI Projekten wird häufig – belegt durch zahlreiche Studien – zu viel Aufmerksamkeit auf das Business Intelligence Tool („Features“) gelegt und zu wenig auf die Datenqualität und den eigentlichen Sinn der BI Prozesse für das Unternehmen („Management“).
Die Grundstruktur des Datenkonzepts resultiert primär aus den Themen, die in der Fachliteratur ausgiebig definiert und diskutiert wurden. Diese werden dann im Kontext der firmenspezifischen Anforderungen, der sogenannten Praxiskonzepte und der aktuellen Trends und Studien zum verbindlichen Datenkonzept ausformuliert. Als Richtwert sollte ein Datenkonzept für die kommenden 5 Jahre gültig sein, die Praxiserfahrungen und neuen Entwicklungen werden durch jährliche Reviews eingearbeitet.

Fachliteratur: Inmon (1996) folgend ist ein Datawarehouse managementorientiert, zeitvariant, vereinheitlicht und für den Dauerbetrieb ausgelegt. Kimball (2001) folgend ist ein Datawarehouse normalisiert in den Faktentabellen und denormalisiert in den Dimensionstabellen. Das Standardwerk von Ralph Kimball zur Definition des Star Schemas ist unser Leitfaden bei der Gestaltung von Datenstrukturen. Hier ein Artikel zum Thema Dimensional Models in the Big Data Era. Neuere Konzepte wie Lean Analytics sind insbesondere im Kontext des Dashboarding zu sehen und stellen einen sehr wertvollen Kontrast zur sicherlich etwas antiquierten (aber trotzdem wertvollen) Datawarehouse Literatur dar.
Studien und Trends: Passend zur Ihrer Branche und Ihrem Geschäftsmodell ist das Datenkonzept im Kontext aktueller Trends und Studien zu prüfen. Damit wird sichergestellt, daß der Fokus des Datenkonzepts aufgrund aktueller operativer Schwerpunkte nicht zu eng gesetzt wird und viel Raum für zukünftige Innovationen läßt.
Zentrale Themen beim Aufbau des analytischen Datenmodells sind:
 Verknüpfen von Fakten- und Dimensionstabellen :: Flat Table vs. Star-Schema vs. Snowflake-Schema vs. Advanced Datenmodelle
Verknüpfen von Fakten- und Dimensionstabellen :: Flat Table vs. Star-Schema vs. Snowflake-Schema vs. Advanced Datenmodelle- Anreicherung um semantische Information :: sprechende Namen :: Kategorisierung :: Q&A Synonyme
- Anreicherung mit Business Logik :: Berechnete Spalten :: Berechnete Measures :: Sort-by-Column
- DAX-Formelsprache :: Row- und Filter-Context :: DAX Patterns für verschiedene betriebswirtschaftliche Fragestellungen
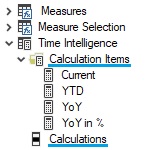
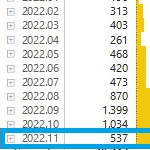
- Zeitintelligenz :: Year-to-Date, Year-over-Year, Running Total, Moving-12-month-average, usw.
- Role Playing Dimensions :: Mehrfachverwendung von Dimensionen im Datenmodell
- m:n Beziehungen :: praktische Anwendungsfälle
- Bidirektionale Filterung :: praktische Anwendungsfälle
- Semi-additive Measures :: Sum, Average und Balance :: Iteratoren :: Vorzeichen und Aggregationsregeln
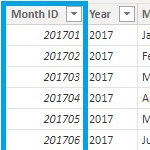
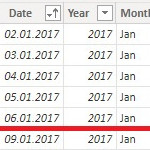
- Hierarchien :: symmetrische und asymmetrische Hierarchien :: natural Hierarchies :: Parent-Child vs. Regular Dimensions :: Zeitdimensionen
- Berechtigungen :: statische und dynamische Berechtigungen

Zentrale Themen beim Aufbau eines (relationalen) Datawarehouse sind:
- Vereinheitlichung der Datenbestände aus den heterogenen Datenquellen zum Kennzahlenkatalog (Schnittstellen mit „Management Unification“ mit dem Fokus auf „Relevanz“)
- Systematische Verspeicherung der Faktendaten aus den heterogenen Datenquellen (am besten auf granularster Buchungssatzebene)
- Systematische Verspeicherung der Dimensionsdaten aus den heterogenen Datenquellen (Mapping, Bereinigung)
- Systematische Handhabung der Versionierung und Historisierung („Slowly-Changing-Dimensions“)
- Systematische Verspeicherung von Textinformationen (Buchungstexte, Planungskommentare, monatliche Berichtskommentare)
- Leistungsfähiger Aktualisierungsmechanismus (Deltaload, Replace-Mechanismus, Job-Steuerung)
- Einfache Ergänzungs- und Korrekturmöglichkeit bei voller Datenherkunftstransparenz (offene Excel-Schnittstelle)
- Berechtigungen und Metadaten für nachfolgende BI Systeme (soweit dies praktisch nutzbar ist)