Das Lakehouse ist in MS Fabric der zentrale Datenspeicher für analytische Zwecke, die Anlage des (leeren) Lakehouse ist wirklich sehr einfach und haben wir zuletzt hier beschrieben. In diesem Blogbeitrag zeige ich jetzt, wie das Lakehouse mit Power Query Know-How aus Power BI Desktop (oder auch aus Excel) recht intuitiv befüllt werden kann. In diesem Blogbeitrag geht es nicht um Architekturüberlegungen, der Fokus liegt auf der praktischen Umsetzung.
1. Konzeptioneller Background in MS Fabric
Das Lakehouse ist der zentrale Datenspeicher für analytische Aufgaben in in OneLake und damit in MS Fabric – hier werden alle Daten für BI, KI und Datenanalyse als single-point-of-truth gesammelt. Data Factory ist das ETL / ELT Tool zum Befüllen des Lakehouse mit Daten.
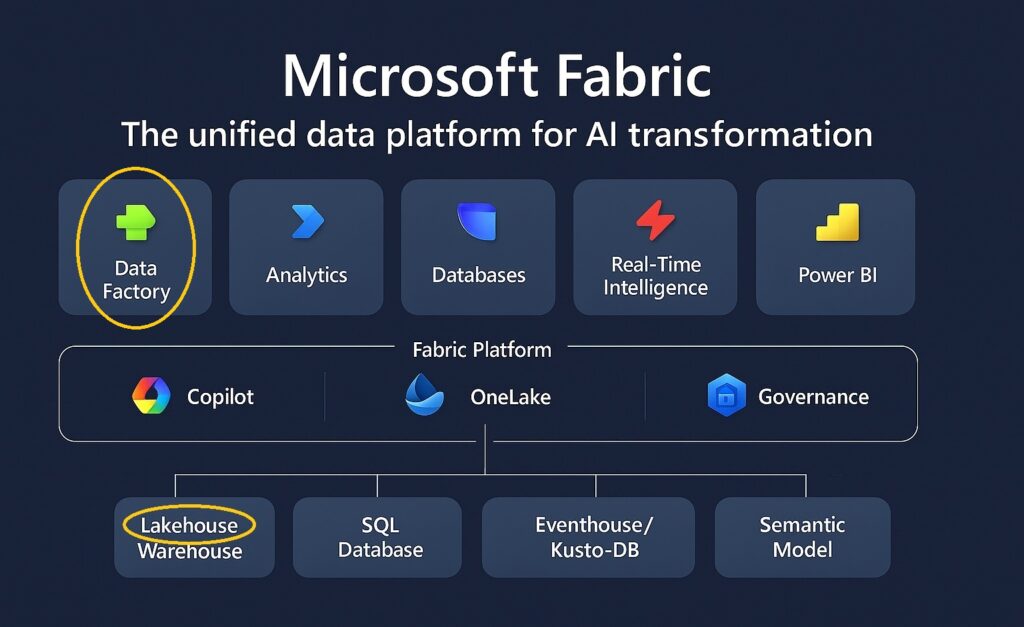
Data Factory ist kein konkretes Tool, sondern ein Sammelbegriff für eine Toolfamilie zum Bewegen, Orchestrieren und Transformieren von Daten in MS Fabric:
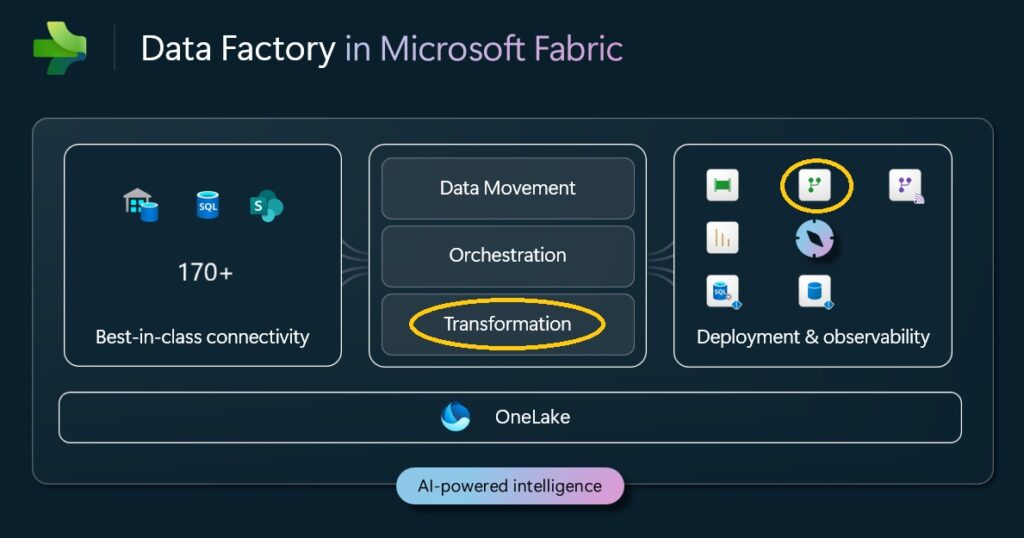
Nach aktueller Einschätzung spielen für uns im Controlling (Persona „Business Analyst“) diese 5 Data Factory Tools eine besonders wichtige Rolle:
- Copy Job = (Inkrementelles) Kopieren von Quelldaten nach MS Fabric
- Database Mirroring = (Inkrementelles) Spiegeln ganzer (operativer) Datenbanken nach MS Fabric (SQL, Oracle, SAP HANA, usw.)
- Shortcuts = virtueller Link zu externen Datenquellen
- Dataflow Gen2 = Transformation und Datenlogik mittels M-basierter Power Query Engine -> für Fachanwender sehr gut geeignet
- Pipeline = Workflow und Steuerlogik mittels JSON-basierter Data Movement & Orchestration Engine
Nach dem Upload der Rohdaten werden wir den Dataflow Gen2 verwenden – das Power Query basierte Tool für Fachanwender. Übrigens: Dataflow Gen1 sind nicht Bestandteil von MS Fabric sondern „nur“ von Power BI, die Daten werden in einem Azure Datalake abgelegt und können nur von Power BI importiert werden (mehr dazu hier).
2. Upload der Rohdaten in das Lakehouse
Wir haben uns entschieden, auch die Rohdaten im Lakehouse abzulegen, um (1) den Daten durch den Speicherort besondere Wichtigkeit zu verleihen und (2) die Rohdaten auch für weitere alternative Verarbeietungsprozesse zur Verfügung zu haben.
2.1 Rohdaten
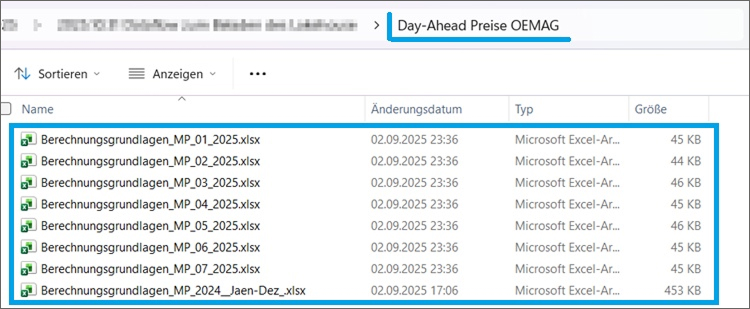
Wir verarbeiten die Rohdaten, die bereits aus diesem Blogbeitrag bekannt sind:
2.2 Upload direkt in das Lakehouse
Die Anlage des Lakehouse haben wir hier beschrieben, einfach das Lakehouse öffnen …
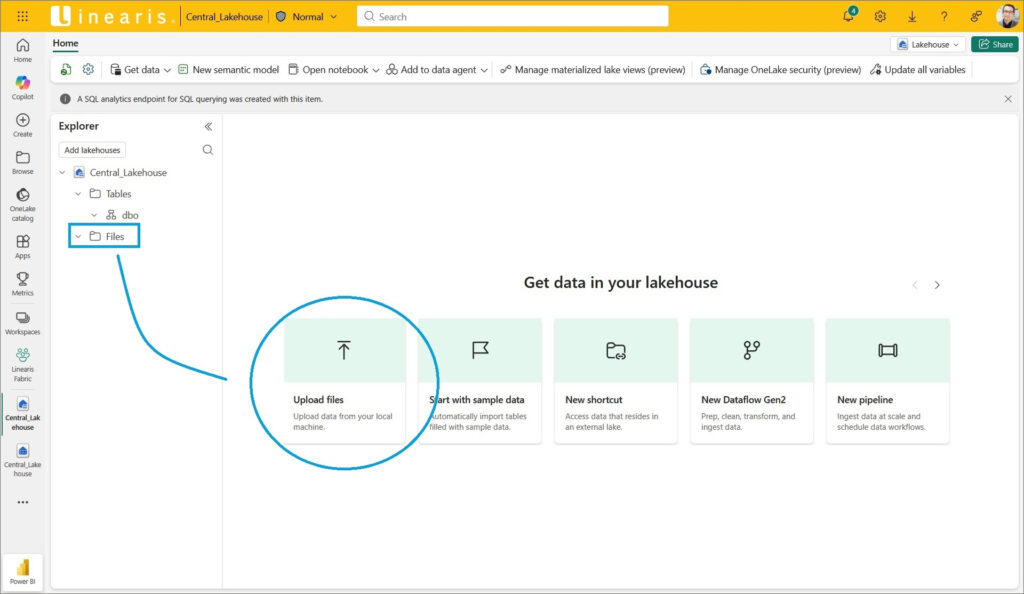
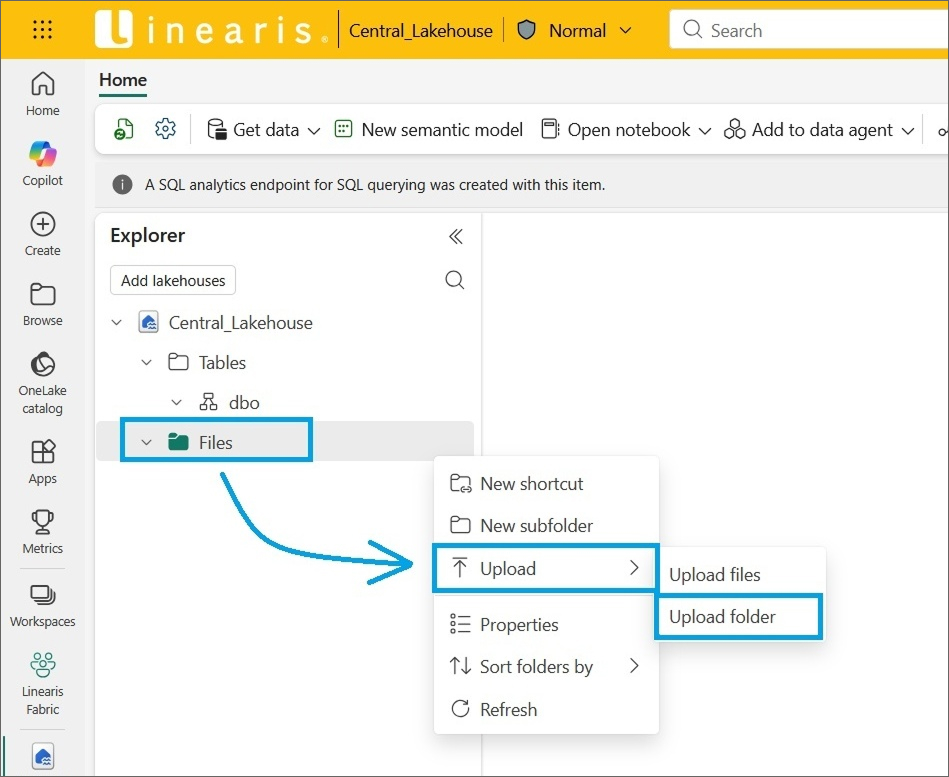
… und den Befehl Upload subfolders aus dem Kontextmenü des Files Verzeichnisses auswählen …
… und den Pfad zum Folder mit den gewünschten Files auswählen:
Der Upload wird innerhalb weniger Sekunden ausgeführt (es sind ja kleine Files) …
… und die Files liegen jetzt im Files Abschnitt unseres Lakehouse:
2.3 Upload über die OneLake App
Alternativ kann auch die OneLake App – ein kleines Plugin für Windows – heruntergeladen werden …

… und die Files über den lokalen Windows Explorer transferiert werden:
3. Transformation der Rohdaten mittels Dataflow Gen2
Die Rohdaten liegen jetzt im Lakehouse, im Sinne eines ELT (nicht ETL) Prozesses möchten wir jetzt die Daten für die spätere Verwendung in Power BI innerhalb des Lakehouse aufbereiten. Wir verwenden das Tool Dataflow Gen2, um unsere bereits bestehende Aufbereitung dieser Daten mit möglichst wenig Aufwand aus Power BI Desktop übernehmen zu können. Die Aufbereitung dieser Daten ist bereits aus diesem Blogbeitrag bekannt.
3.1 Anlegen des Dataflow Gen2
Der Dataflow kann an verschiedenen Stellen angelegt werden – am einfachsten geht es aber direkt im Lakehouse selbst:
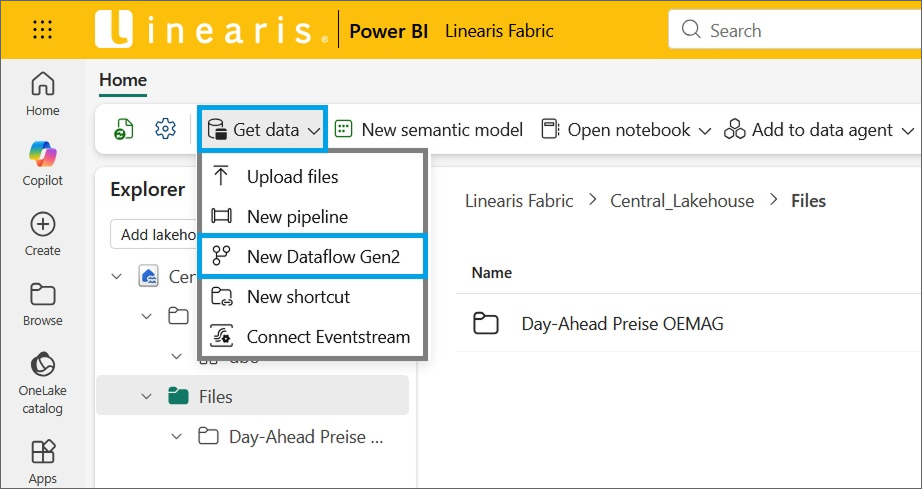
Einfach Namen für den Dataflow vergeben …
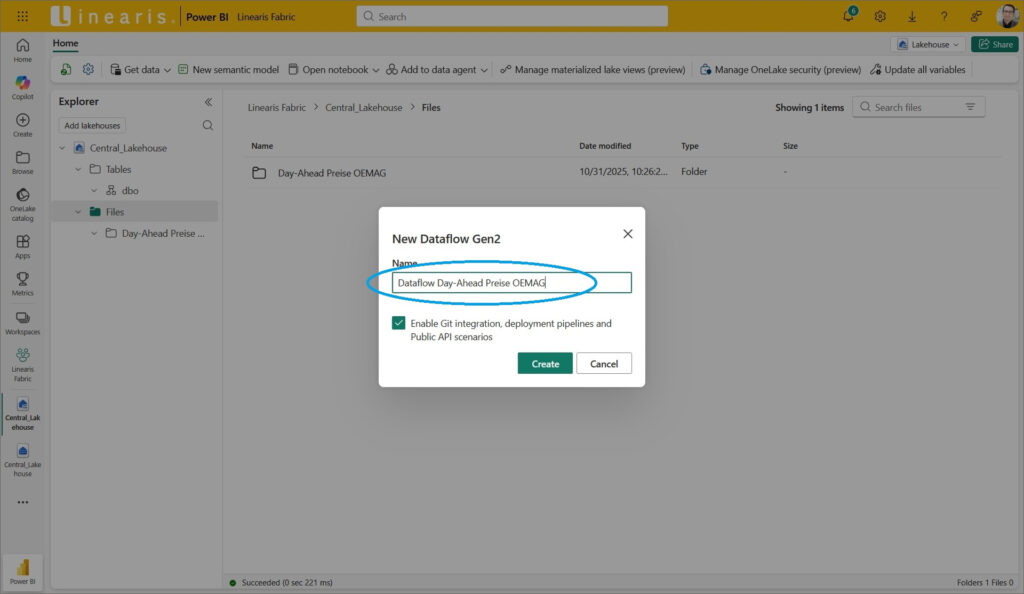
… und schon landen wir im Power Query Editor für den neuen Dataflow – als Power Query User fühlt man sich hier gleich mal „zu Hause“:
3.2 Anbinden der Files aus dem Lakehouse
Im ersten Schritt erstellen wir eine Query mit der Verbindung zu den Files im Lakehouse, um diesen M-Code dann mit dem M-Code aus unserer Vorlagelösung in Power BI Desktop zu kombinieren. Dazu einfach den Button Get Data -> More anklicken und bei den Datasources für MS Fabric das Lakehouse auswählen:
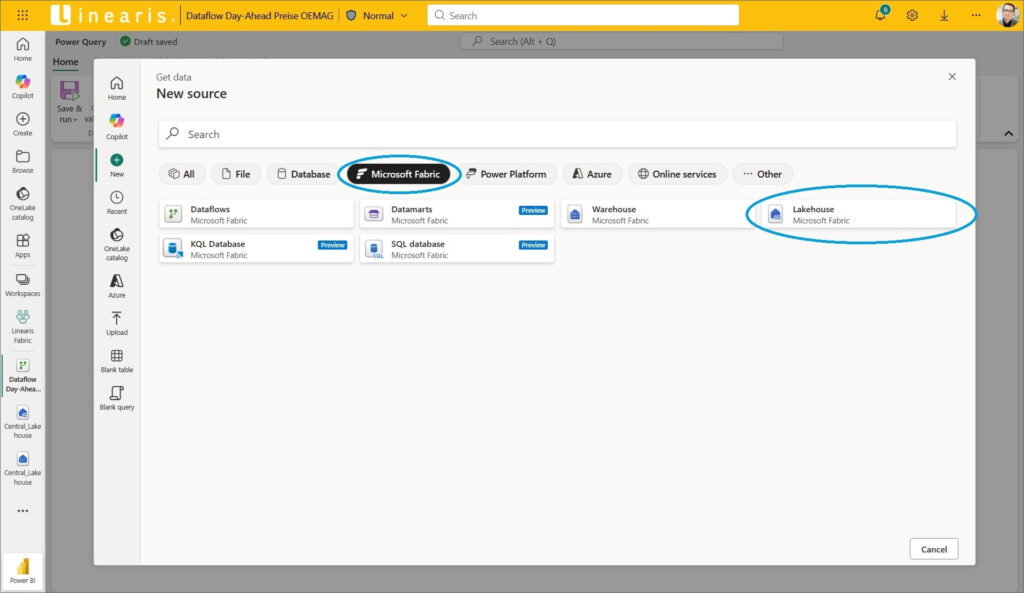
Jetzt einfach die Credentials bestätigen …
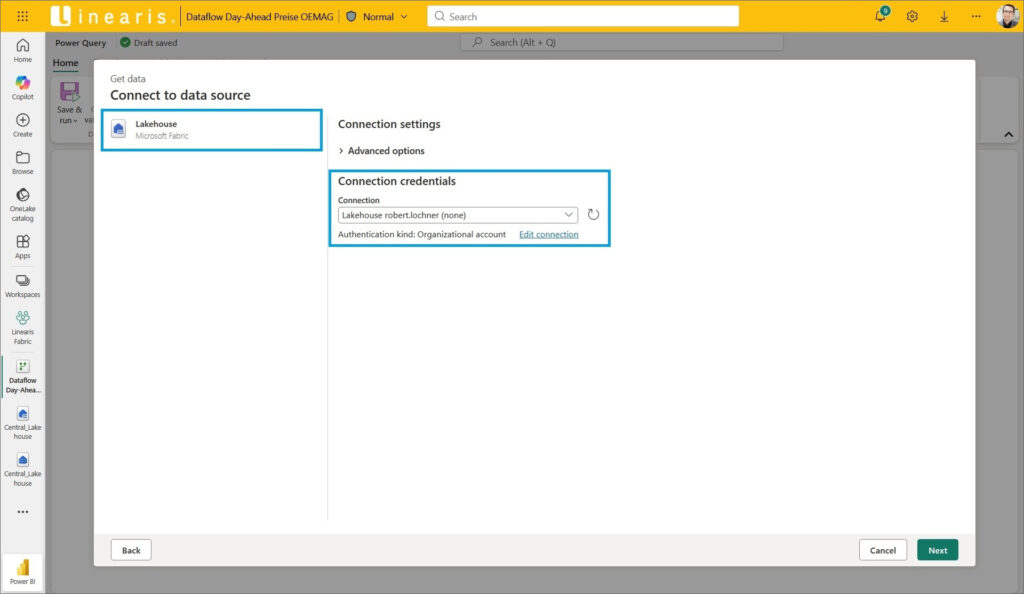
… und im Navigator nicht die Files sondern den Folder mit den hochgeladenen Files auswählen und mit dem Button Create abschließen:
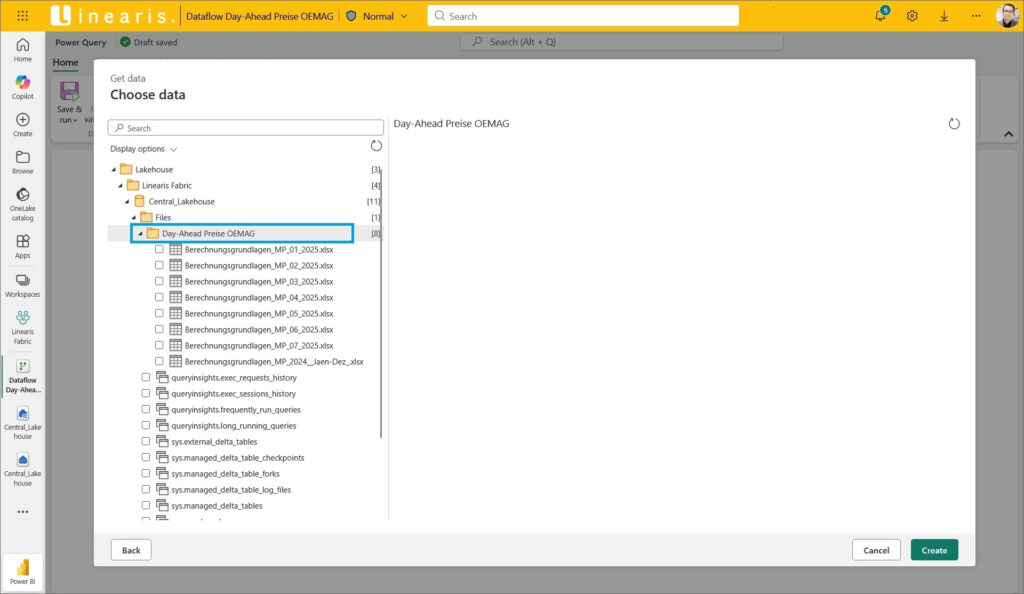
Wir landen – wie wir das auch aus Power Query kennen – wieder im Query Editor und sehen die Steps, die in unserer neuen Query Day-Ahead Preise OEMAG angelegt wurden:
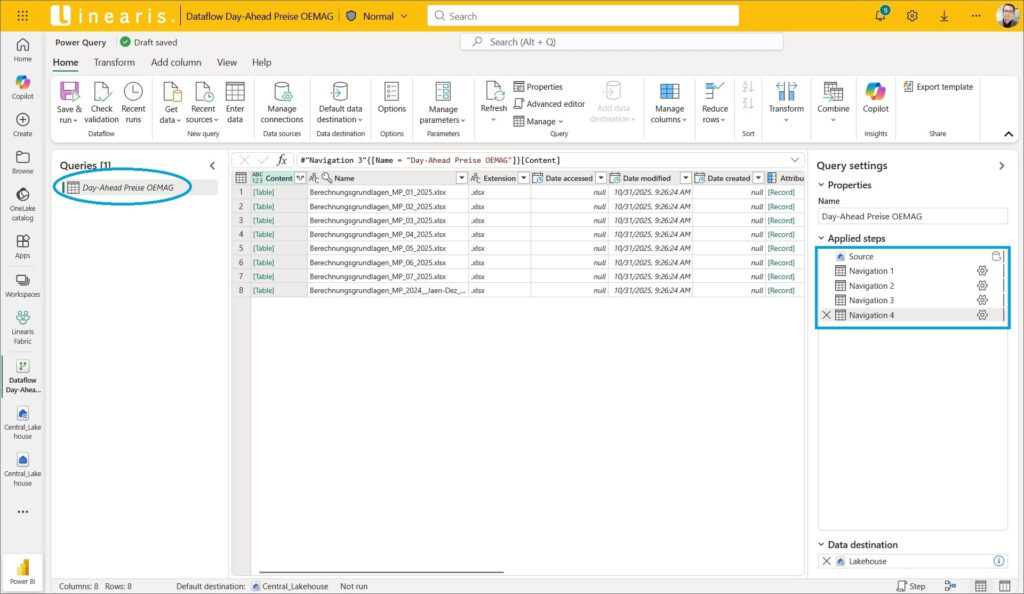
3.3 Einkopieren der beiden M-Statements aus Power BI Desktop
Wir haben bereits die fertige Lösung für die Aufbereitung dieser Rohdaten in PBI Desktop, diese ist bereits ausführlich in diesem Blogbeitrag beschrieben. Wir kopieren die beiden M-Statements für die Query und die Function aus dem Advanced Editor in eine Textdatei, um sie dann im Dataflow einsetzen zu können.
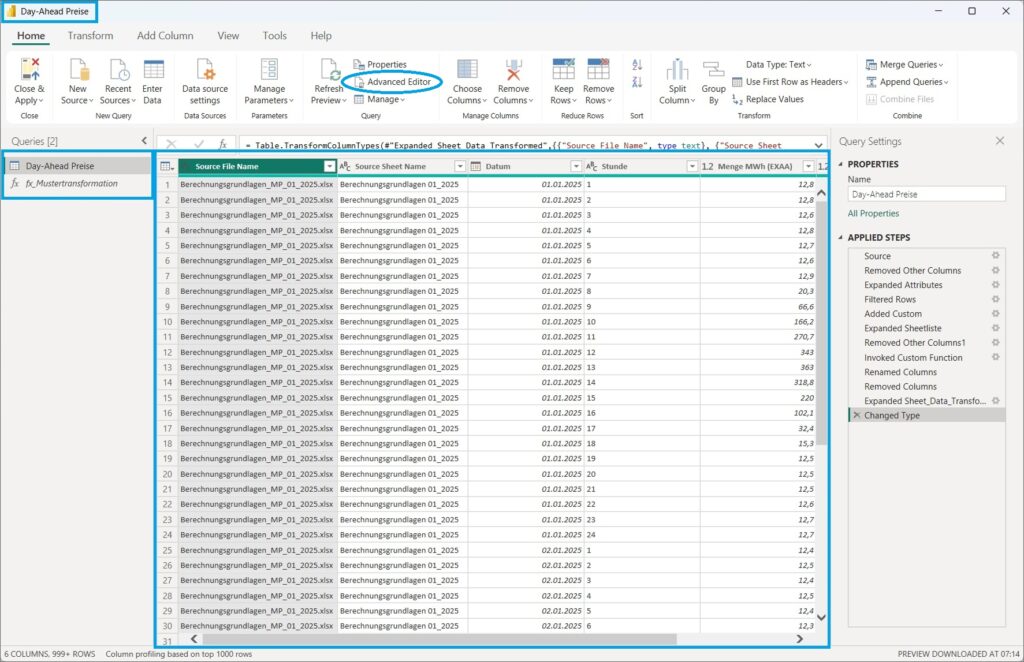
Im ersten Schritt legen wir für die Aufnahme der M-Function eine neue Blank Query an …
… und fügen einfach 1:1 das M-Statement aus der PBI Desktop Lösung ein und bestätigen mit dem Button Next:
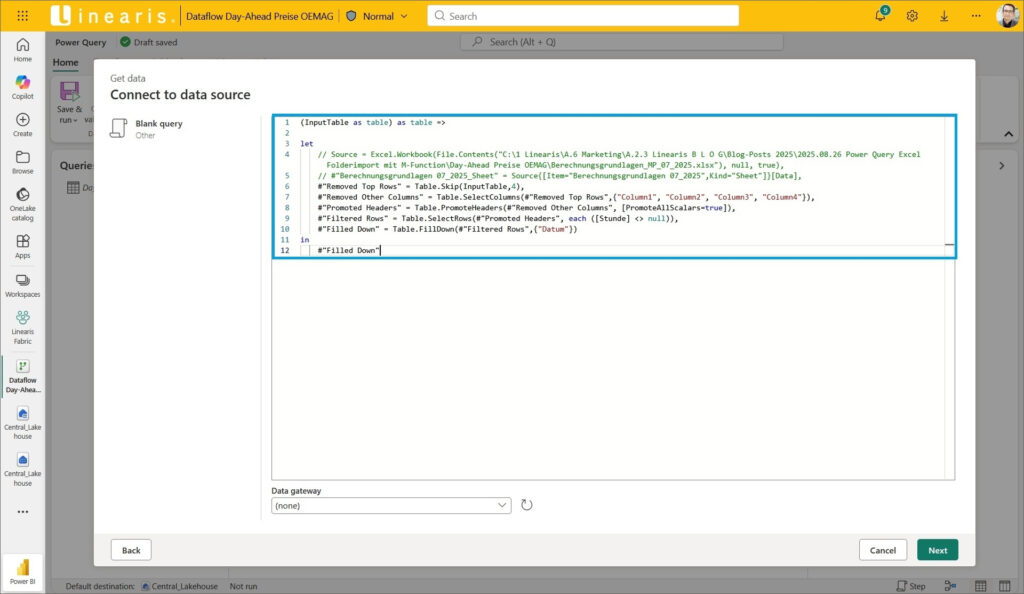
Jetzt brauchen wir die neue Funktion lediglich als fx_Mustertransformation zu benennen:
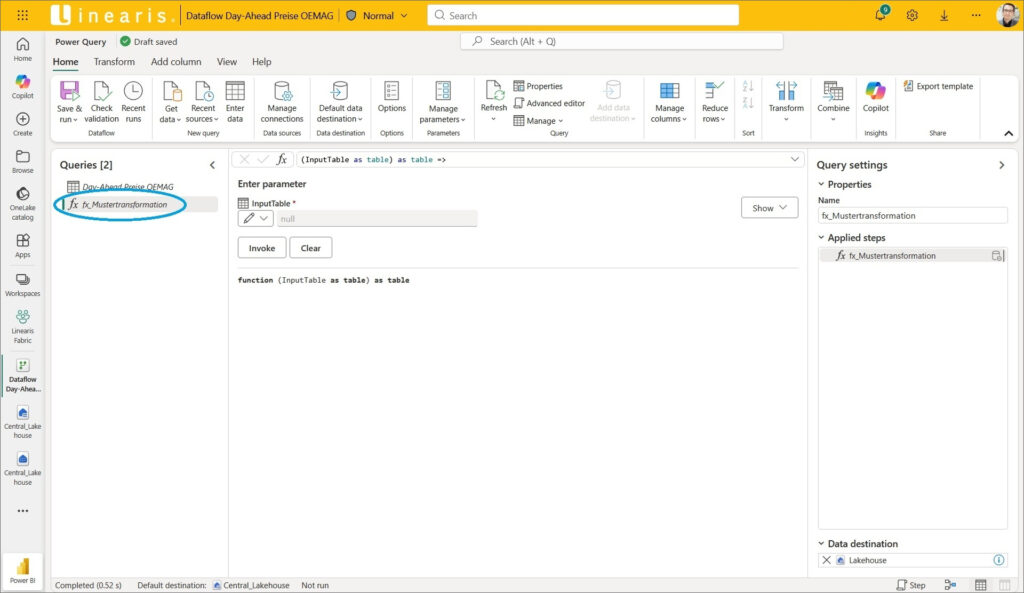
Im zweiten Schritt öffnen wir den Advanced Editor der Query Day-Ahead Preise OEMAG …
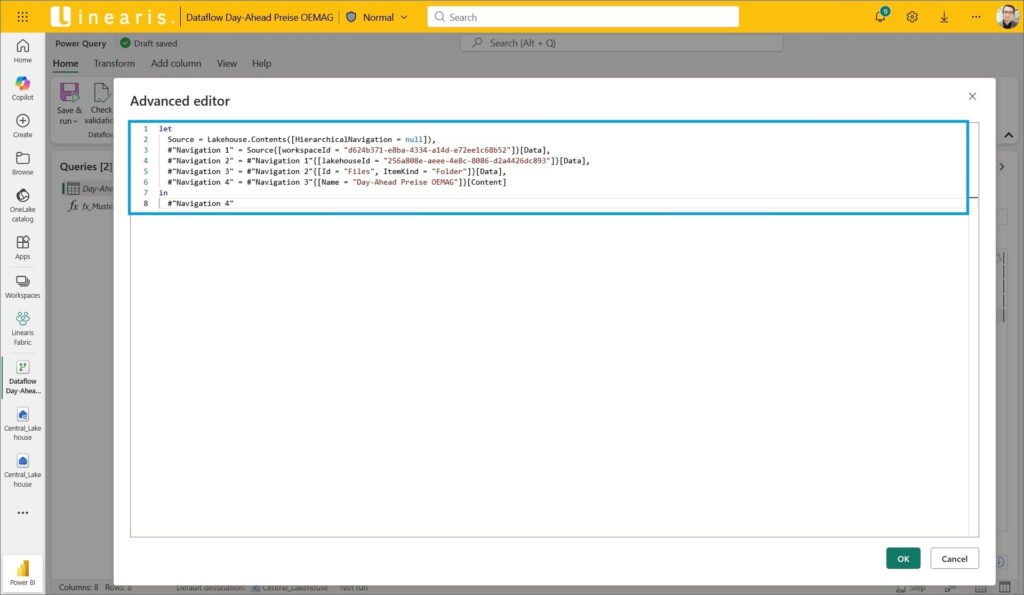
… und fügen unterhalb das M-Statement aus der PBI Desktop Lösung ein:
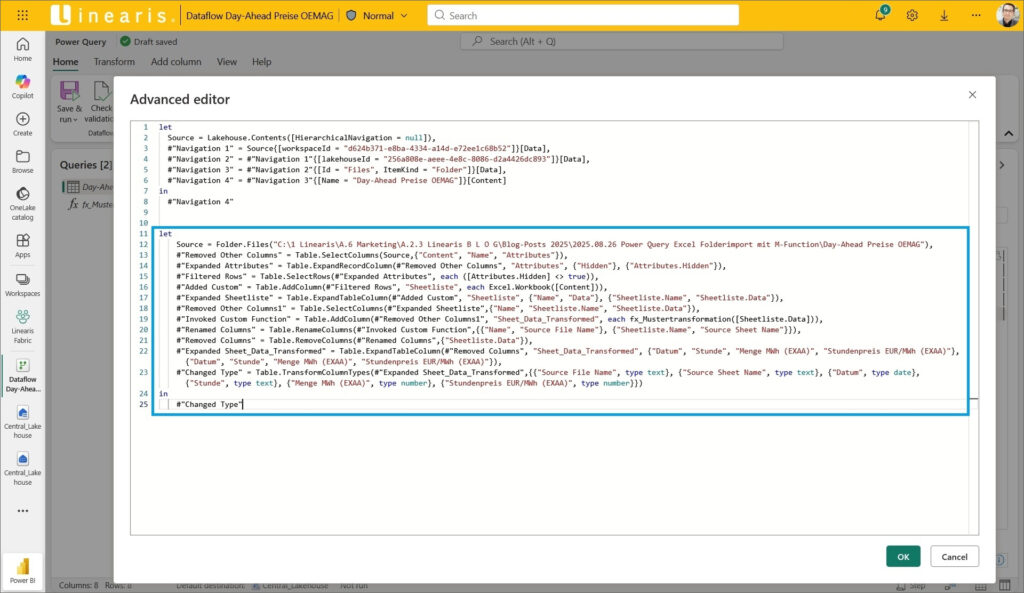
Jetzt brauchen wir nur noch den M-Code zusammenführen:
- Löschen der Zeilen 7 bis 9 sowie der Zeile 11
- Einfügen eines Kommas am Ende von Zeile 6
- Auskommentieren der Zeile 8 (alte Source)
- Anpassen der Step-Referenz in Zeile 9 an den Step in Zeile 6
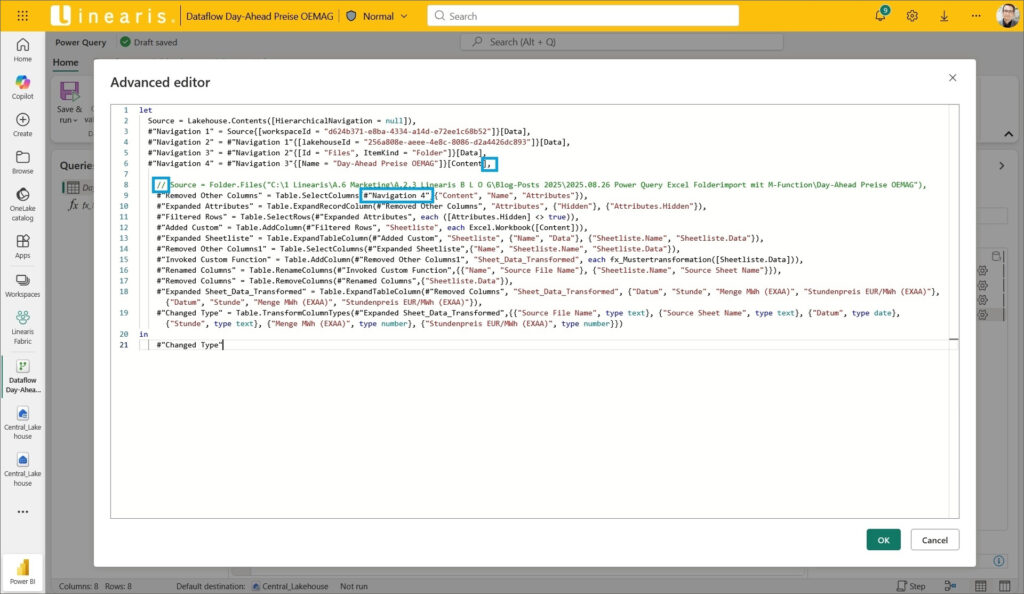
Voilà – fertig ist die Transformation der Rohdaten Files.
3.4 Ausgabe der transformierten Daten in das Lakehouse
Anders als in Power BI Desktop kann im Dataflow Gen2 das Ziel für die Ausgabe der Daten gewählt werden – in unserem Fall möchten wir die Daten ebenfalls in das Central_Lakehouse ausgeben.
Mit dem Button Save & run wird die Verarbeitung gestartet und – ebenfalls anders als in Power BI Desktop – wird der Editor nicht geschlossen …
… sondern die Verarbeitung direkt im Editor ausgeführt:
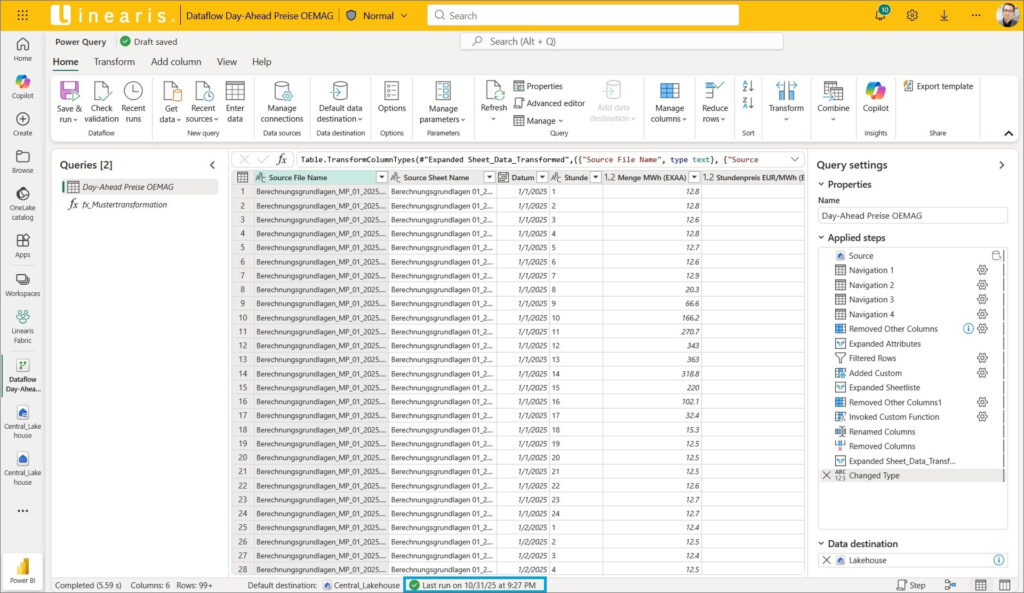
Den Power Query Editor des Dataflows können wir jetzt schließen und unsere erste fertige Output Tabelle im Lakehouse bestaunen :)
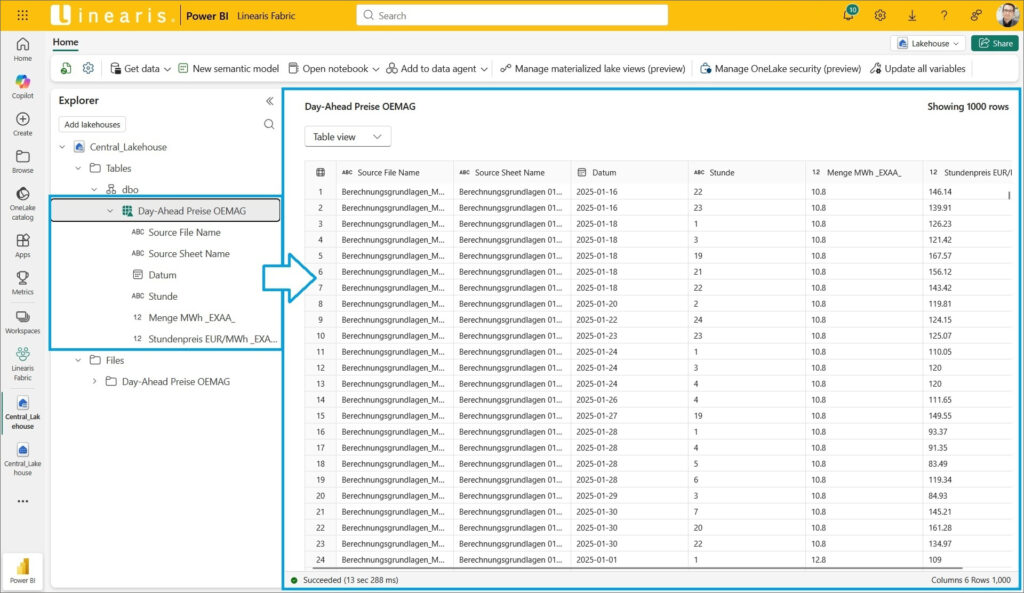
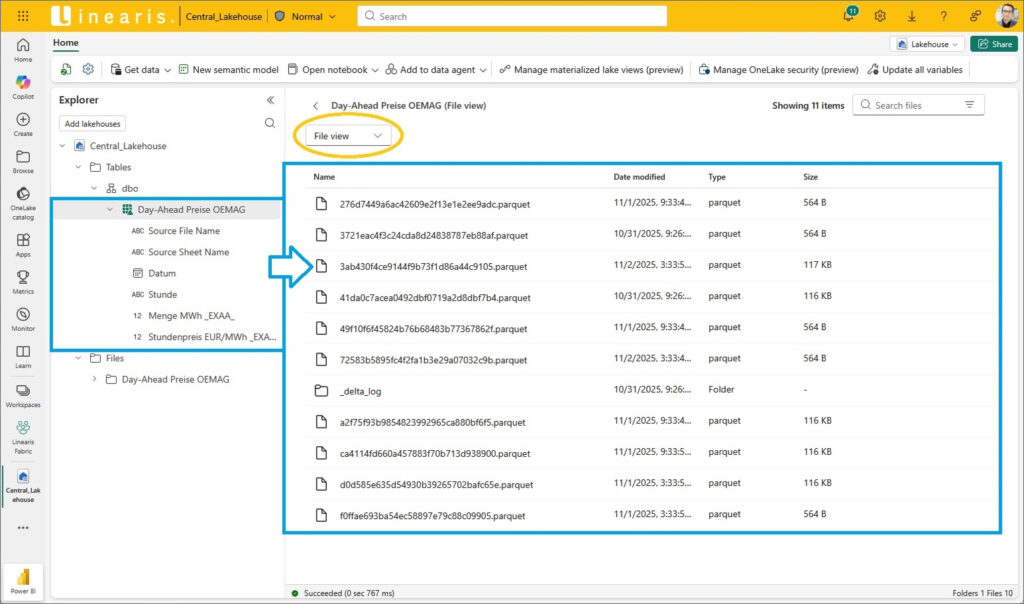
Der File View ist auch mal interessant anzusehen – hier sind die einzelnen Files im Parquet Format hinter der Tabelle zu sehen:
4. Laufender Betrieb
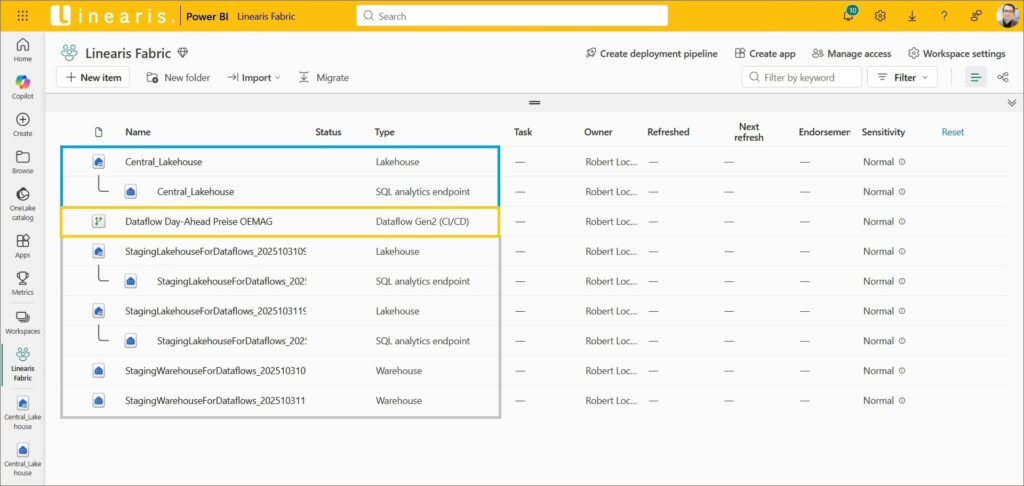
Am Workspace fällt jetzt auf, daß nicht nur der Dataflow hinzugekommen ist sondern auch eine ganze Menge Staging Objekte. Diese werden für die Ausführung des Dataflows temporär angelegt und sollten eigentlich automatisch wieder gelöscht werden. Aber das funktioniert offenbar noch nicht ganz richtig, daher löschen wir diese Objekte manuell.
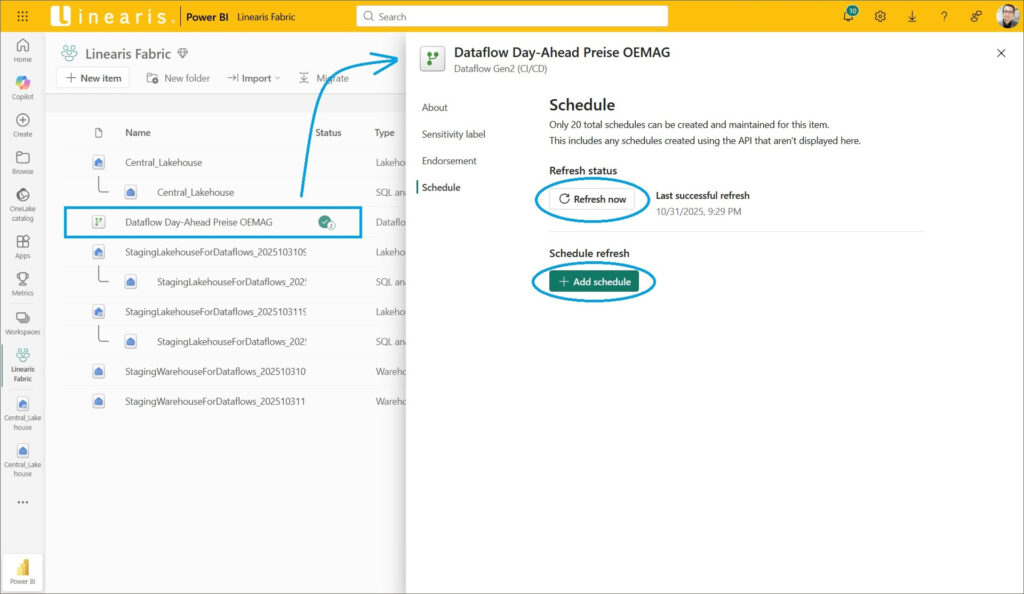
Der Dataflow kann – natürlich – entweder manuell aktualisiert werden und/oder mit einem Schedule zur zeitgesteuerten Aktualisierung ausgestattet werden:
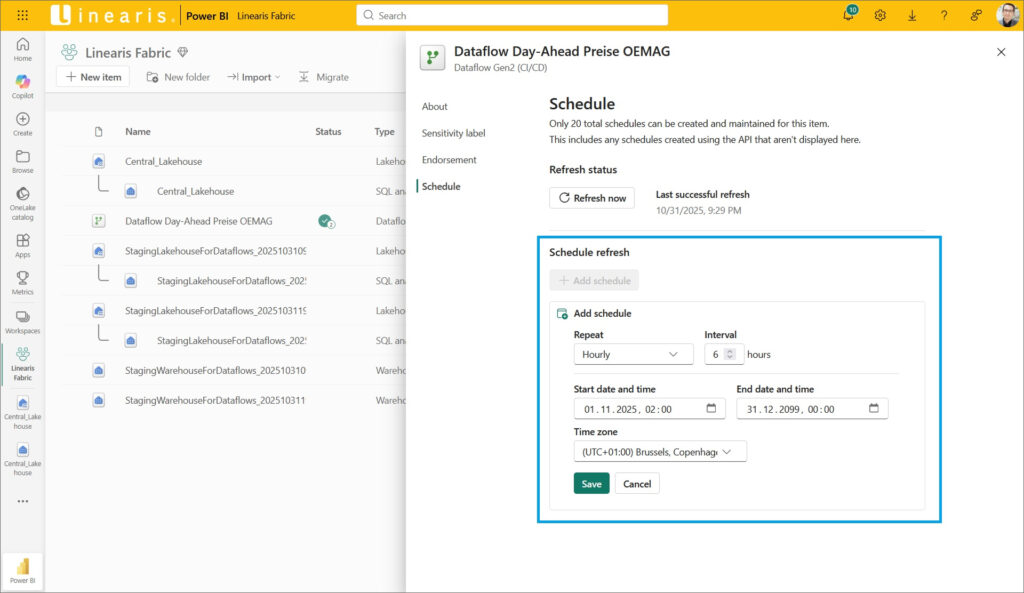
Dabei ist sehr erfreulich, daß – anders als im Power BI Semantischen Modell – die Settings viel feingliedriger und damit effektiver sind:
Fazit
Das Lakehouse kann mittels File Uploads und Dataflows Gen2 rasch mit Daten besiedelt werden. Power Query Know-How aus Power BI Desktop und/oder Excel ist die ideale Voraussetzung, um mit den Dataflows die Rohdaten aufzubereiten und sauber in Tabellen des Lakehouse abzulegen. Auch die Übertragung bestehender Queries aus Power BI funktioniert sehr gut.
Ein kleines Manko, daß die temporären Staging Objekte im Lakehouse nicht zuverlässig gelöscht werden, hier muß derzeit noch manuell nachgeräumt werden.
Alles in allem ist es aber sensationell, wie Self-Service tauglich das Lakehouse mit den Dataflows verwendet werden kann!
Quellen
https://learn.microsoft.com/en-us/fabric/data-factory/data-factory-overview