Im ersten Teil dieser Blogserie wurden anhand eines einfachen Beispiel die analytischen Grundlagen zur Warenkorbanalyse vorgestellt. Es ging dabei nur um 6 Produkte, nun soll gezeigt werden, wie man wesentlich größere Datenmengen handhaben kann. Auch hier ist Excel ein nützliches Tool, um die ersten Schritte zu bewältigen. Mit R und Power BI ist mit dem Apriori-Algorithmus eine tiefergehende und vor allem automatisierte Analyse möglich, die alle Produkte und Produktgruppen zueinander in Beziehung setzt.
Große Korrelationsmatrizen in Excel
Bei der Warenkorbanalyse bedeuten große Datenmengen nicht, dass es sehr viele Warenkörbe bzw. Rechnungen gibt, sondern dass es viele Produkte und damit eine große Anzahl möglicher Kombinationen gibt. In Excel kann über die statistischen Analyse-Funktionen eine Korrelationsmatrix erstellt werden, wie im Teil 1 der Blogserie gezeigt. Output ist eine Tabelle, in der die Korrelationen aller Produkte mit allen anderen berechnet werden. Das bedeutet bei 6 Produkten also eine Tabelle mit 6 Zeilen und 6 Spalten, eine überschaubare Menge an Korrelationen. Je höher die Anzahl an Produkten ist, desto größer ist allerdings auch die Korrelationsmatrix. Damit man dann immer noch den Überblick behält nun ein kleiner Trick: die Zellen der Korrelationsmatrix mit der bedingten Formatierung einfärben.
Im folgenden Beispiel wird eine Warenkorbanalyse mit 169 Produkten durchgeführt, das ergibt eine Korrelationsmatrix mit 169 Zeilen und 169 Spalten. Die uninteressanten Korrelationskoeffizienten sind die „nahe 0“, denn das bedeutet kein Zusammenhang. Die interessanten Werte sind dagegen die „hohen“ Korrelationen, also Werte in Richtung +1 (positiver Zusammenhang) oder in Richtung -1 (negativer Zusammenhang). Daher ist eine farbliche Markierung der Korrelationsmatrix hilfreich:
- Markieren der gesamten Korrelationsmatrix
- Start -> Bedingte Formatierung -> Farbskalen -> Weitere Regeln
- 3-Farben-Skala wählen und für Minimum, Mittelpunkt und Maximum Zahlen angeben (-1, 0, +1) sowie Farben auswählen (orange, weiss, grün)

Man erreicht damit, dass nur die interessanten Werte in Richtung -1 und +1 farblich markiert werden. Durch herauszoomen (starkes Verkleinern) kann damit auch eine große Korrelationsmatrix mit einem Blick erfasst werden: wo sind die orangen und grünen Korrelationenen?

Im angeführten Beispiel sind die Korrelationen insgesamt sehr niedrig, daher war unsere Farb-Skalierung von -1 bis +1 etwas zu hoch gewählt. Um die Farbskala zu verbessern, kann man die Werte herabsetzen, z.B. von -0,1 bis +0,1:

Damit werden Korrelationskoeffizienten schon ab -0,1 grün und schon ab +0,1 orange eingefärbt, was die Differenzierung der Zusammenhänge erleichtert:

Beispielsweise im ganz oberen linken Bereich gibt es einige grüne Zellen, also positive Zusammenhänge von Produkten. Lassen Sie uns hier kurz hineinzoomen, damit man besser erkennen kann, welche Produkte das betrifft. Es scheint also z.B. zwischen whole milk, pip fruit, cream cheese einerseits und tropical fruits und yogurt andererseits verhältnismäßig hohe positive Zusammenhänge zu geben. Hier stösst man aber eben an die Grenzen der Korrelationsanalyse: die Werte in der Korrelationsmatrix können nicht direkt interpretiert werden. Sie zeigen nur auf, dass es offenbar stärkere und schwächere Zusammenhänge gibt und wo sie liegen, nicht aber wie oft die Produkte gemeinsam gekauft wurden.

Der Apriori Algorithmus
Die weiterführende Analyse hat nun zum Ziel, für alle Produktpaare bzw. Produktgruppen die drei Kennzahlen Support, Konfidenz und Lift zu berechnen. Damit können dann erste Regeln formuliert werden wie etwa:
Wenn whole milk und pip fruit gekauft werden, dann wird zu x % auch tropical fruit und yogurt gekauft.
Was ist ein Algorithmus?
Ein Algorithmus ist eine Reihe von Anweisungen, die immer wieder hintereinander ausgeführt werden, um möglichst schnell zum gewünschten Ergebnis zu kommen. Warum brauchen wir hier einen Algorithmus? Ganz einfach weil das „händische“ Berechnen der Kennzahlen bei vielen Produkten zu lange dauern würde. Bei den vorliegenden 169 Produkten müssten über 15.000 einzelne Berechnungen durchführen, diese Aufgabe kann nur automatisiert bewältigt werden.
Was macht der Apriori Algorithmus?
Der Apriori Algorithmus erledigt genau den Job, alle relevanten Regeln zu finden. Für unsere Zwecke ist es dabei gar nicht so wichtig zu verstehen, wie er exakt funktioniert. Viel wichtiger ist zu verstehen, was sein input und was sein output ist.
- Input: Mindest-Support und Mindest-Konfidenz
- Output: alle Regeln die dem Input entsprechen
Über die Input-Angaben wird also schon a priori gefiltert, was man nicht haben möchte, nämlich Regeln zu Produkten mit geringem Support (wenig einzeln gekauft) und mit geringer Konfidenz (wenig zusammen gekauft). Gehen wir mal davon aus, dass uns Produkte nur interessieren, wenn sie zumindest in 1% der Warenkörbe vorkommen. Außerdem interessieren uns auch nur Regeln, wenn der Kauf von A mindestens zu 20% den Kauf von B impliziert. Dann ist der Input für den Algorithmus: Min-Support = 1% und Min-Konfidenz = 10%.
Nun berechnet der Algorithmus alle Kennzahlen, bei denen ein Produkt mindestens zu 1% gekauft wurde und die Konfidenz über 10% liegt. Die wichtigsten drei (die mit dem höchsten Lift) sind in folgenden Abbildung dargestellt:

Nochmal zu Erinnerung: der Support sagt uns, wie oft ein Produkt überhaupt gekauft wird. Er ist bei den drei Regeln immer gleich hoch, d.h. die Produkte finden sich jeweils nur in 1% der Warenkörbe. Die Konfidenz sagt uns dann, wie oft Produkt B gekauft wird, wenn Produkt A im Warenkorb ist. Und der Lift sagt uns schließlich, um welchen Faktor die Wahrscheinlichkeit für B steigt, wenn A gekauft wurde. Nun ausformuliert:
- Wenn whole milk und yogurt im Warenkorb landen, dann wird zu 18,0% auch curd dazu gekauft (Konfidenz). Klingt wenig, aber die Wahrscheinlichkeit für curd steigt durch whole milk und yogurt auf das 3,37-fache an (Lift).
- Sind hingegen citrus fruits und other vegetables im Warenkorb, dann zu 35,9% auch root vegetables (Konfidenz). Die Wahrscheinlichkeit für root vegetables wird von citrus fruits und other vegetables auf das 3,30-fache angehoben (Lift).
- Bei der Kombination other vegetables und yogurt wird zu 35,9% auch whipped/sour cream dazugekauft (Konfidenz). Die Wahrscheinlichkeit für whipped/sour cream wird von other vegetables und yogurt damit auf das 3,27-fache angehoben (Lift).
Anwendungsbeispiel für die Regeln
Ein klassisches Beispiel dafür, wie man die gefundenen Regeln gewinnbringen nutzen kann liegt in der Preisgestaltung. Nehmen sie z.B. die erste Regel: eine Rabattaktion auf whole milk und yogurt wird Ihnen zusätzliche Kunden bringen, die dann auch curd kaufen. Die Zuverlässigkeit der Regel ist nicht zu bestreiten, da der Lift hoch ist. Es geht nur mehr darum zu berechnen, ob sich die Aktion auszahlt, was im Wesentlichen von den Deckungsbeiträgen und der Wirkung des Aktionspreises abhängt. Hier ein einfaches Muster dazu:
- Der DB von whole milk und yogurt liegt bei 0,20 EUR, beim Aktionspreis aber nur mehr bei 0,10 EUR. Der DB von curd liegt bei 0,50 EUR und wird nicht gesenkt.
- Nehmen wir an, dass durch den Aktionspreis um 50% mehr whole milk und yogurt gekauft werden als sonst. Bei normalerweise 1.000 Warenkörben wöchentlich mit whole milk und yogurt wird es im Aktionszeitraum also rund 1.500 solche Warenkörbe geben.
- Bei den zusätzlichen 200 Warenkörben verdienen Sie zu 18% nun auch den DB auf curd, also 18% * 500 * 0,50 = 45,00 EUR zusätzlich. Durch die Aktion verlieren Sie aber 1.500 mal die 0,10 EUR auf whole milk und yoghurt, das sind 1.500 * 0,10 = -15,00 EUR. In dem Fall zahlt sich die Aktion aus, da Sie mehr gewinnen als verlieren!
Natürlich gibt es auch andere Situationen, in denen sich eine Aktion nicht auszahlt, z.B. wenn der DB von curd geringer wäre, oder wenn der Aktionspreis Sie mehr kostet als der DB von curd bringt, oder eben auch wenn nicht +50% sondern nur +10% Einkäufe durch die Aktion zustande kommen. In obiger Rechnung trägt aber noch ein wesentlicher Parameter zum Gewinn bei: die Konfidenz! Das Plus ergibt sich aus den 18% in denen curd gekauft wird, wenn whole milk und yogurt im Warenkorb sind. Die Konfidenz ist also der Parameter, der hier eine große Rolle spielt: bei Regel 2 liegt die Konfidenz schon bei rund 36%, da geht die Rechnung auch eher auf!
Neben diesem quantitivem Beispiel ist aber auch die qualitative Aussage der Regeln wichtig, beispielsweise für die Regalplatzierung oder in der Prospektgestaltung: Produkte mit hohem Lift (= zuverlässige Regel) und hoher Konfidenz (= häufig beobachtet) sollten gemeinsam angeboten werden.
Die technische Umsetzung der Analyse
Wir haben bisher nur über die Ergebnisse der Analyse gesprochen, nicht aber wie und in welcher technischen Umgebung der Apriori Algorithmus angewendet werden kann. Seit 2014 ist in der frei verfügbaren statistical software R das package arules verfügbar, mit dem der Apriori Algorithmus einfach umzusetzen ist. R ist ursprünglich eine prozedurale Programmiersprache, d.h. es werden hintereinander Befehslzeilen ausgeführt, die man z.B. in einem einfachen Textfile speichern kann und in der sogenannten R-Konsole ausführt. Da Programmieren und das Erstellen von Scripts nicht jedermanns Sache ist, gibt es mittlerweile eine Reihe an Anbindungen von R in benutzerfreundlichere Umgebungen, insbesondere jene an Power BI. Damit ist es möglich, alle Analysefunktionen aus R in der gewohnten Umgebung von Power BI zu nutzen. Also: wie kommt man von den Daten über R und Power BI zum Set der Regeln wie oben beschrieben?
Die Ausgangsdaten
Die Basisdaten für die Analyse in R und Power BI sind Transaktionen (Warenkörbe) in Form eines einfachen Textfiles, in dem eine Zeile immer einen Warenkorb darstellt und die einzelnen Produkte einfach durch Kommas getrennt angeführt werden. Hier z.B. die ersten drei Warenkörbe:
![]()
Ebenso können CSV- und Excel-Files in einer „vertikalen Form“ verwendet werden, dabei wird in einer Spalte die Transaktionsnummer und in der anderen Spalte das Produkt angegeben, alle Zeilen mit der gleichen Transaktionsnummer bilden dann einen Warenkorb. In folgender Abbildung dieselben drei Warenkörbe nochmals in „vertikaler Form“:

Diese Datenstruktur benötigt am wenigsten Speicherbedarf, denn es werden nur diejenigen Produkte angeführt, die auch tatsächlich vorkommen. In Excel war die Datenbasis etwas anders: auch dort bedeutet jede Zeile eine Transaktion, jedoch waren in den Spalten alle 169 Produkte angeführt und mit 1/0 kodiert. In den 4 Zellen zu citrus fruit, semi finished bread, margarine, ready soups stand dann eine 1, in den restlichen 165 Zellen eine 0. Diese Darstellung benötigt wesentlich mehr Speicherbedarf, wobei die Nullen überflüssig sind. Egal in welcher Form die Daten vorliegen, sie können einfach von einer in die andere Struktur übergeführt werden.
Einlesen der Daten in R
Die Ausgangsdaten können als CSV mit dem Befehl read.transactions in R eingelesen werden. Dazu ist das R-package arules erforderlich, das mit dem Befehl install.packages installiert wird und mit dem Befehl library aktiviert wird. Insgesamt sind also drei Befehlszeilen in der R-Konsole auszuführen:
install.packages(„arules“)
library(arules)
read.transactions(file = „C:\\Transaktionen.csv“, format = „single“, sep = „;“, cols = 1:2)
Im letzten Befehl read.transactions werden neben dem Dateinamen einige weitere Parameter gesetzt: format = „single“ gibt an, dass die Transaktionen in der oben gezeigten „vertikalen Form“ angeführt sind (eine Spalte mit der Transaktionsnummer und zweite Spalte mit dem Produktnamem), sep = „;“ gibt an, dass die Werte mit „;“ getrennt sind (im amerikanischen CSV-Format sind sie nämlich mit „,“ getrennt) und cols = 1:2 gibt an, dass die Werte in den Spalten 1-2 stehen. Unmittelbar mit dem Einlesen wird in der R-Konsole eine erste Zusammenfassung ausgegeben:

Erste Deskriptive Analyse in R
Nun kann die Analyse schon beginnen: zuerst werden die eingelesenen Daten nochmal mit dem Befehl read.transactions dem frei definierbarem Objekt daten mit dem Operator „<-“ zugewiesen, dann wird mit dem Befehl summary(daten) in der R-Konsole eine erste Zusammenfassung ausgegeben:
daten <- read.transactions(file = „C:\\Transaktionen.csv“, format = „single“, sep = „;“, cols = 1:2)
summary(daten)

Hier sind z.B. die häufigsten Produkte angeführt (whole milk, other vegetables, usw.) und die Größe der Warenkörbe (size): es gibt 2.159 Warenkörbe mit nur einem Produkt, 1.643 Warenkörbe mit 2 Produkten, usw. Grafisch lässt sich diese Verteilung der Warenkörbe am besten mit einem Histogramm mit dem Befehl hist und size darstellen:
hist(size(daten), col = „lightblue“)

Die meisten Warenkörbe befinden sich im linken Bereich, sind also eher klein (1-5 Produkte), wogegen Warenkörbe mit mehr als 10-15 Produkten vernachlässigbar selten vorkommen. Dieselbe Information lässt sich mit dem Befehl boxplot auch als Boxplot darstellen . Übrigens, beide Befehle („hist“ und „boxplot“ sind bereits im base package von R enthalten, das package „arules“ ist dazu also nicht notwendig):
boxplot(size(daten), col = „lightblue“)

Hier werden die Ausreißer noch besser erkennbar: Warenkörbe mit mehr als 12 verschiedenen Produkten sind als Ausnahme zu bewerten (Punkte ganz oben mit geringer Häufigkeit), die große Menge liegt bei 2-6 Produkten (Box unten).
Der Apriori Algorithmus in R
Nach der ersten deskriptiven Analyse nun zum Kern des Vorhabens, der Ermittlung der Regeln mit dem Apriori Algorithmus. Dazu wird der Befehl apriori benutzt und das Ergebnis dem frei definiertem Objekt regeln zugewiesen. Mit den Parametern minimum Support = 1% und minimum Konfidenz = 10% liefert der Befehl „apriori“ eine entsprechend angepaßte Trefferliste:
regeln <- apriori(daten, parameter = list(support = 0.01, confidence = 0.10))

Die Ausgabe in der R-Konsole zeigt zuerst die Parameter des Algorithmus, die wichtigsten sind Support und Konfidenz, der Rest ist technischer Natur. Auch der „Algorithmic control“ ist für die Interpretation relativ uninteressant, schon leichter verständlich dagegen der „Absolute minimum support count„: es gibt mindestens 98 Transaktionen die dem min Support = 1% entsprechen. Das ist nicht unwesentlich, denn es sagt aus, auf welche Datenmenge sich die gefundenen Regeln stützen. Wird der min Support auf 0.001 (also 0,1%) gesetzt, dann sind nur noch 9 Transaktionen in der Trefferliste. Damit wären allerdings die Mindestanforderungen an eine gültige Datengrundlage nicht mehr gegeben.
Eine einfache Zusammenfassung der Regeln kann wieder mit dem Befehl summary gegeben werden:
summary(regeln)

Es wurden insgesamt 435 Regeln gefunden. Sehr interessant ist die „rule length distribution„: es gibt 8 Regeln mit nur 1 Produkt (diese sind nutzlos), die meisten Regeln (331) betreffen 2 Produkte, daneben gibt es aber auch 96 Regeln mit 3 Produkten. Interessant ist auch der Block „summary of quality measures„: hier sind Minimum, Maximum, Mittelwert, Median, usw. zu Support, Konfidenz und Lift angegeben. Die maximale Konfidenz beträgt sogar 0.5862, das heisst es gibt zumindest eine Regel mit 58,6% Konfidenz!
Mit dem Befehl inspect können die Regeln angeführt werden, dabei empfiehlt es sich, über den Befehl sort und dem Parameter by die Regeln gleich nach einer Kennzahl zu sortieren, etwa nach Konfidenz:
inspect(sort(regeln, by = „confidence“))

Im angeführten Ausschnitt wurden aus Platzgründen nur die ersten 10 Regeln dargestellt, ausgegeben werden natürlich alle 435 Regeln. Das sind also die Top-10 nach Konfidenz, ganz oben die stärkste Regel:
Wenn citrus fruit und root vegetables gekauft werden, dann werden zu 58,6% auch other vegetables gekauft. Der Lift liegt über 3, d.h. der Kauf von fruit und root vegetables verdreifacht die Wahrscheinlichkeit für other vegetables.
Ähnliches gilt für root vegetables und tropical fruits, auch die Regel bzgl. curd und yogurt haben eine hohe Konfidenz, wenn auch der Lift dann „nur“ mehr bei rund 2,3 liegt. Nun geht es aber darum, den Überblick zu bekommen. Es gibt schließlich über 400 Regeln, die man sich nicht alle einzeln ansehen kann. Dazu sind grafische Darstellungen hilfreich, wie sie etwa im package arulesViz bereitgestellt werden:
install.packages(„arulesViz“)
library(arulesViz)
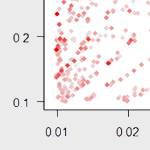
plot(regeln)

Hier sind alle Regeln als Punkte dargestellt, die y-Achse bezeichnet die Konfidenz, die x-Achse den Support, und der Farbton den Lift. Gesucht sind die Regeln weit oben (hohe Konfidenz) und weit rechts (hoher Support) in tief rot (hoher Lift). Hier wird v.a. klar, dass es meistens nicht die eine Super-Regel gibt, die alle drei Kriterien gleichzeitig maximal erfüllt. Es liegt also im Ermessen des Betrachters, die für die spezifische Situation wichtigsten Regeln zu selektieren.
Mit demselben Befehl plot, aber dem zusätzlichen Parameter method = „grouped“ können die Regeln gruppiert dargestellt werden, damit sie auch inhaltlich interpretiert werden können:
plot(regeln, method = „grouped“)

Interessant sind wiederum die großen Punkte (hoher Support) in tiefem rot (hoher Lift), wie etwa zu other vegetables, whole milk und root vegetables. Es gibt insgesamt zehn verschiedene Darstellungsvarianten, die mit dem Parameter method gesteuert werden können (auf die wir hier aber nicht weiter eingehen werden).
Integration von R in Power BI
Das beste haben wir uns in diesem Beitrag für den Schluss aufbehalten. Die R Integration in Power BI bietet eine sehr leistungsfähige Möglichkeit, um die Ergebnisse des Apriori Algorithmus zu visualisieren. In Power BI (Desktop) ist unter „Visualizations“ das R script visual („R“-Icon) zu finden, mit einem Klick darauf wird das R Visual geöffnet, in das der R Code (bspw. aus der R-Console) eingefügt werden kann (davor kommt noch eine popup bezüglich der Aktivierung von R scripts, die Sie ruhig bestätigen können):
![]()

Es gibt eine Reihe von vorgefertigten Showcase Beispielen, mit denen man die ersten Schritte in Power BI und R machen kann. Technisch gesehen steckt hinter der Visualisierung ein R script. Das ist nichts anderes als ein einfaches Textfile (.txt) mit einer Reihe an Befehlen, wie etwa im vorangehenden Abschnitt angeführt. Power BI führt nun alle Befehle aus und bildet die R-Grafiken in Power BI ab. Erfahrene Nutzer können somit R-scripts erstellen, um sie dann in Power BI direkt per Mausklick abzurufen. Beispielsweise können Transaktionsdaten in Power BI geladen werden, auf denen dann der Apriori Algorithmus ausgeführt wird und die Regeln „on the fly“ ermittelt und visualisiert werden.
Nachdem die Transaktionsdaten in der vertikalen Form in Power BI geladen wurden (hier „Groceries.csv“) sind folgende Schritte auszuführen:
- Klick auf das R-Icon unter Visualizations, damit entsteht rechts eine noch leere Visualization (und unten öffnet sich automatisch der R script editor)
- Klicken Sie die beiden Spalten aus „Groceries“ an, damit sie unter „Values“ aufgelistet sind
- Schreiben Sie unten im R script editor die R-Befehle und klicken am Ende auf den Button „Ausführen“
Im Script wird der Apriori Algorithmus ausgeführt und die Regeln dargestellt, dadurch entsteht oben die Grafik für die wichtigsten 100 Regeln:

Daneben können aus R heraus auch die Regeln selbst als CSV abgespeichert werden, und dann wiederum als Daten in Power BI verwendet werden. Der Befehl zum Speichern der Regeln als lautet:
write.csv2(inspect(rules), file = ‚rules.csv‘)
Damit wird das file „rules.csv“ angelegt, das die Regeln in folgender Form beinhaltet (lhs = left hand side, rhs = right hand side):

Dieses CSV wird wiederum in Power BI geladen, um weitere Visualisierungen zu erstellen. Sehr empfehlenswert ist beispielsweise der force directed graph. Das ist kein R-visual, sondern ein custom visual, das als pbiviz-Datei heruntergeladen werden kann. Das ist nun ein wunderbares Beispiel dafür, wie Power BI und R zusammenspielen können: die Regeln stammen aus R (rules.csv) und die Visualisierung aus Power BI. Es bleiben wieder 3 Schritte um zum Ergebnis zu kommen:
- Force directed graph importieren (pbiviz-Datei)
- Klick auf den neuen custom visual button rechts
- lhs, rhs und lift aus rules.csv angeben wie im screenshot dargestellt

Hier wurde zusätzlich der Filter für Lift > 3 gesetzt, es werden also nur die Regeln mit entsprechend hohem Lift dargestellt. Somit kann schnell auf einen Blick erkannt werden, wo interessante Zusammenhänge liegen. Beispielsweise die Vernetzung von whole milk und curd ist die stärkste Verbindung, wie ja auch schon in den Regeln zuvor festgestellt. Daneben sind aber auch weitere Produkte interessant. Wenn man mit dem Mauszeiger über eine der Verbindungen streift, werden die Werte dazu angezeigt.
Ausblick
Im dritten Teil dieser Blogserie zur Warenkorbanalyse wird das letzte wichtige Verfahren vorgestellt, das Clustering. Mit Clusterverfahren werden Produkte zu Gruppen (Clustern) zusammengeführt, die in sich homogen und untereinander heterogen sind. Damit gelangt man zu Produktgruppen, die oft miteinander gekauft werden. Statt den Fokus auf einzelne Produkte und Assoziationsregeln zu setzen geht es also darum, typische Warenkörbe und Verbünde zu finden. Das macht Sinn, um sogenannte Zielwarenkörbe oder Muster-Warenkörbe zu identifizieren oder um eine sehr große Anzahl an Produkten in eine überschaubare Anzahl von Produktgruppen zu verdichten.
Links
Warenkorbanalyse Teil 1: Analytische Grundlagen und Korrelationsanalyse in Excel
Warenkorbanalyse Teil 2: Apriori Algorithmus in R und Power BI
Warenkorbanalyse Teil 3: Clusteranalyse und Kundensegmentierung