


Slicer filtern in Power BI (Desktop) sämtliche Charts, Tabellen und Cards, die sich auf der gleichen Berichtsseite befinden – das ist bekanntes und sehr erwünschtes Verhalten.
Ob sich jedoch die Slicer auch gegenseitig filtern und ob unbebuchte Dimensionselemente angezeigt werden, hängt vom verwendeten Datenmodell ab. In diesem Blogbeitrag werden die beiden weit verbreiteten Datenmodelle Flattable und Star Schema verglichen und untersucht, wie in beiden Fällen die gegenseitige Filterung der Slicer erreicht werden kann. Dieses gegenseitige Filtern ist in vielen – wenn auch auch nicht allen – Einsatzszenarien erwünscht.
1. Filterverhalten der Slicer im „Flattable“ Datenmodell
Wir betrachten das Slicer-Filterverhalten zuerst im Datenmodell, das nur aus 1 Tabelle – einem sogenannten Flattable aus Fakten- und Dimensionsdaten – besteht:
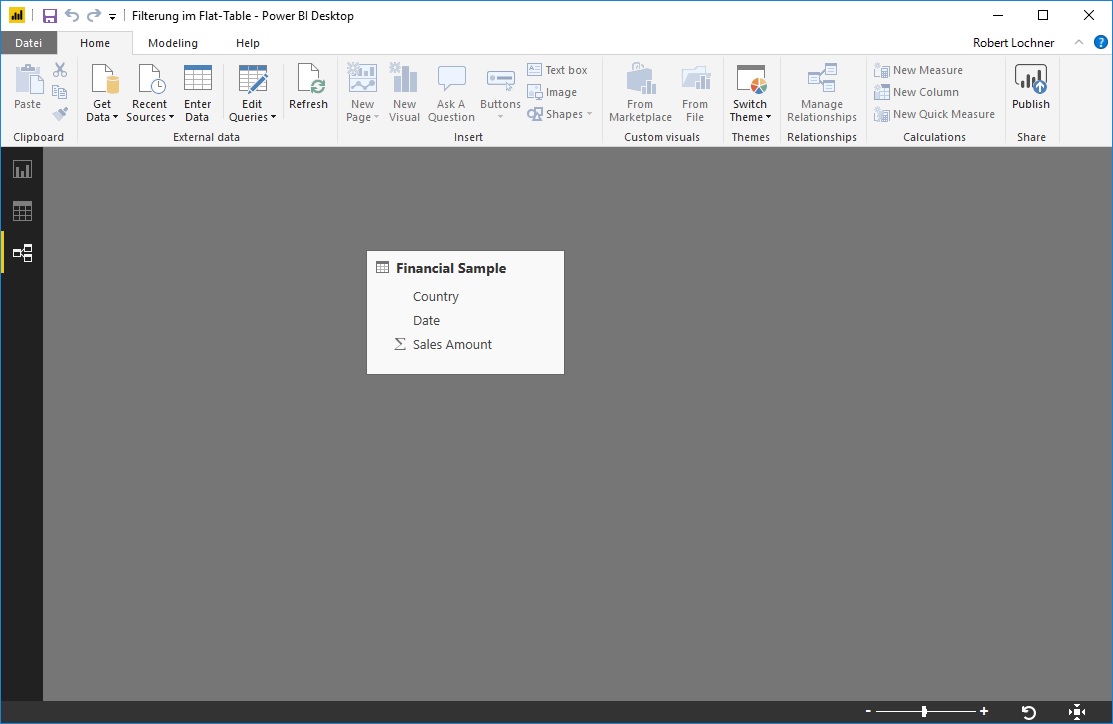
Der Flattable für diese Demo ist sehr simpel aus 2 Dimensionsfeldern und 1 Wertspalte aufgebaut:
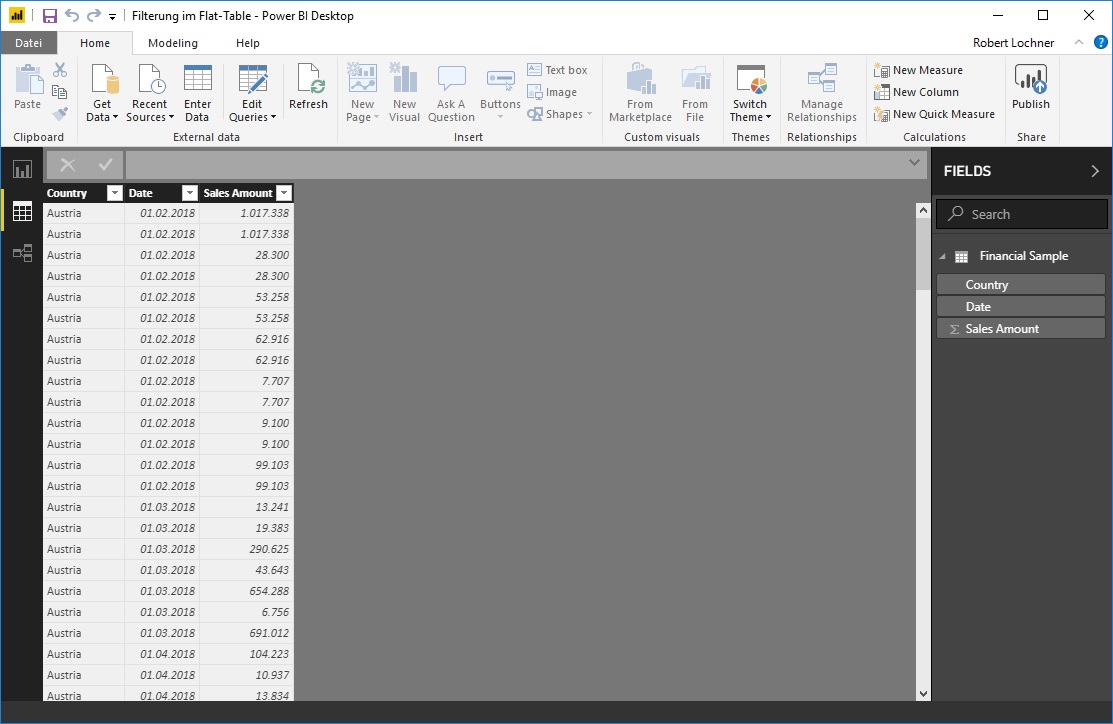
Die Slicer zeigen ausschließlich die Dimensionselemente an, die bebucht sind. Aufgrund des Datenmodells kann das gar nicht anders sein, da ein Flattable keine unbebuchten Dimensionselemente aufnehmen kann:
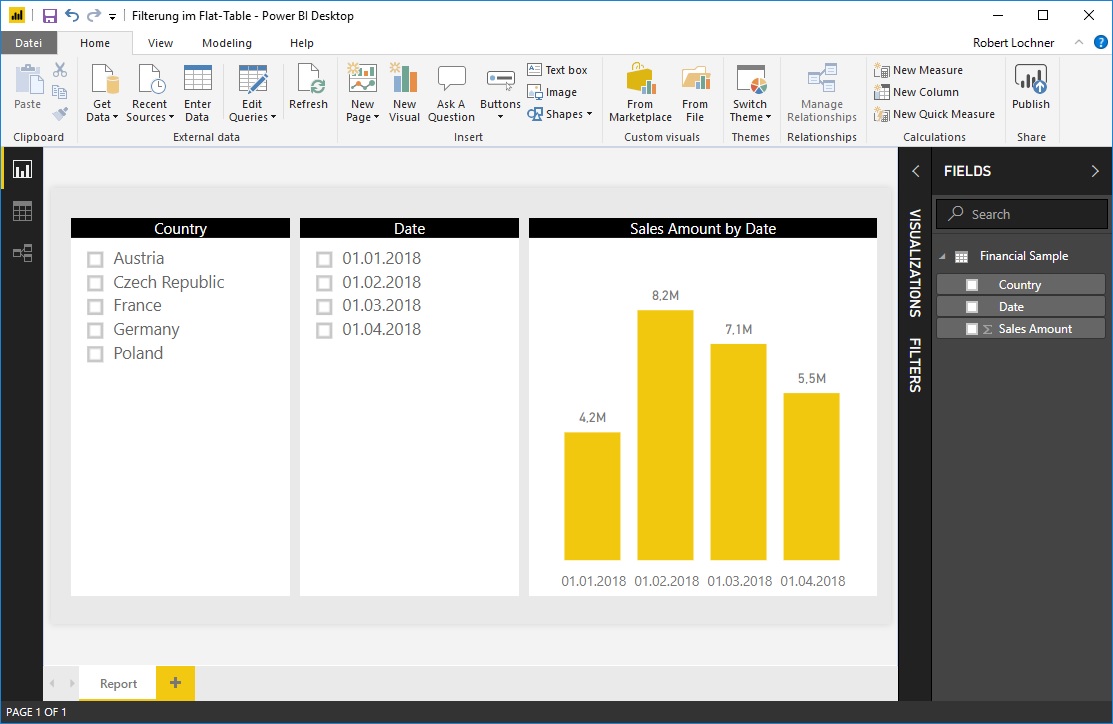
Für das Land Austria sind im Jänner 2018 keine Buchungen vorhanden, bei der Selektion im linken Slicer wird automatisch die Auswahl der verbleibenden Elemente im rechten Slicer auf die dort bebuchten Elemente reduziert:

Das gleiche funktioniert auch andersrum bei der Auswahl eines 01.01.2018, die Länderliste im linken Slicer reduziert sich entsprechend auf die für diese Periode bebuchten Elemente:
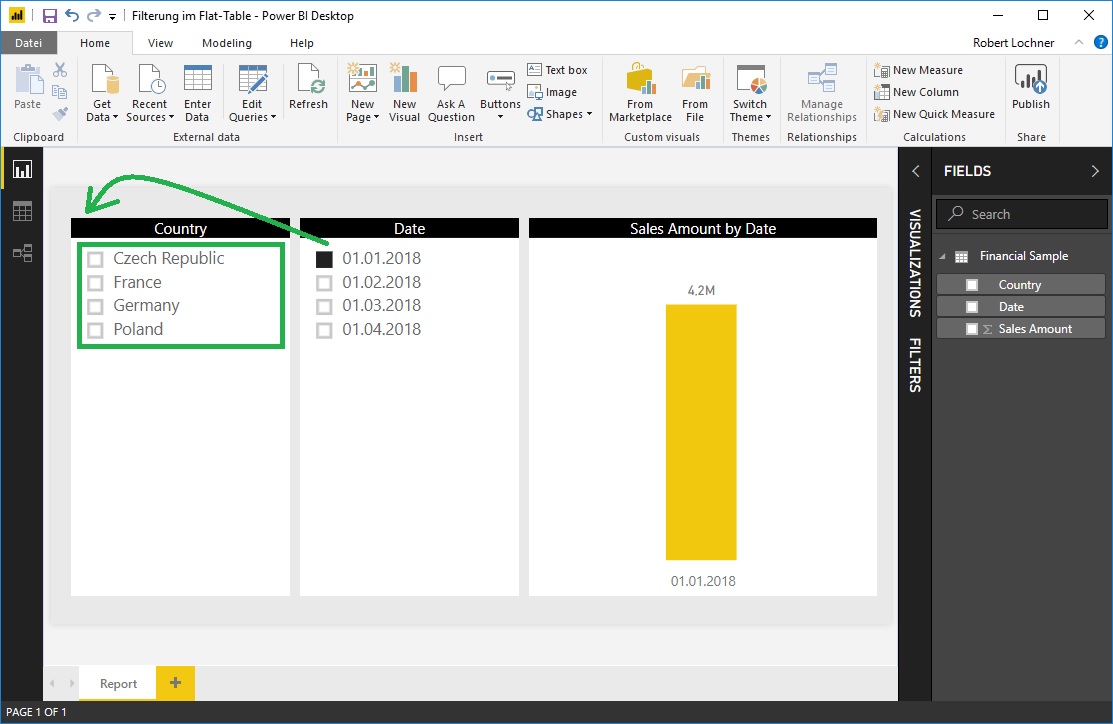
Die Slicer im Flattable-Datenmodell filtern sich also immer gegenseitig, eine Nicht-Filterung kann unseres Wissens nach in diesem Datenmodell nicht realisiert werden.
Exkurs: Verwendung der Auto-Date Dimension
Bei Verwendung eines Feldes aus einer Auto-Date Dimension in einem Slicer werden (1) alle (also auch die unbebuchten) Elemente des Jahres angezeigt und (2) ist die gegenseitige Filterung insofern eingeschränkt, als zwar der Date-Slicer zwar die anderen Slicer filtert, nicht aber die anderen Slicer den Date-Slicer:
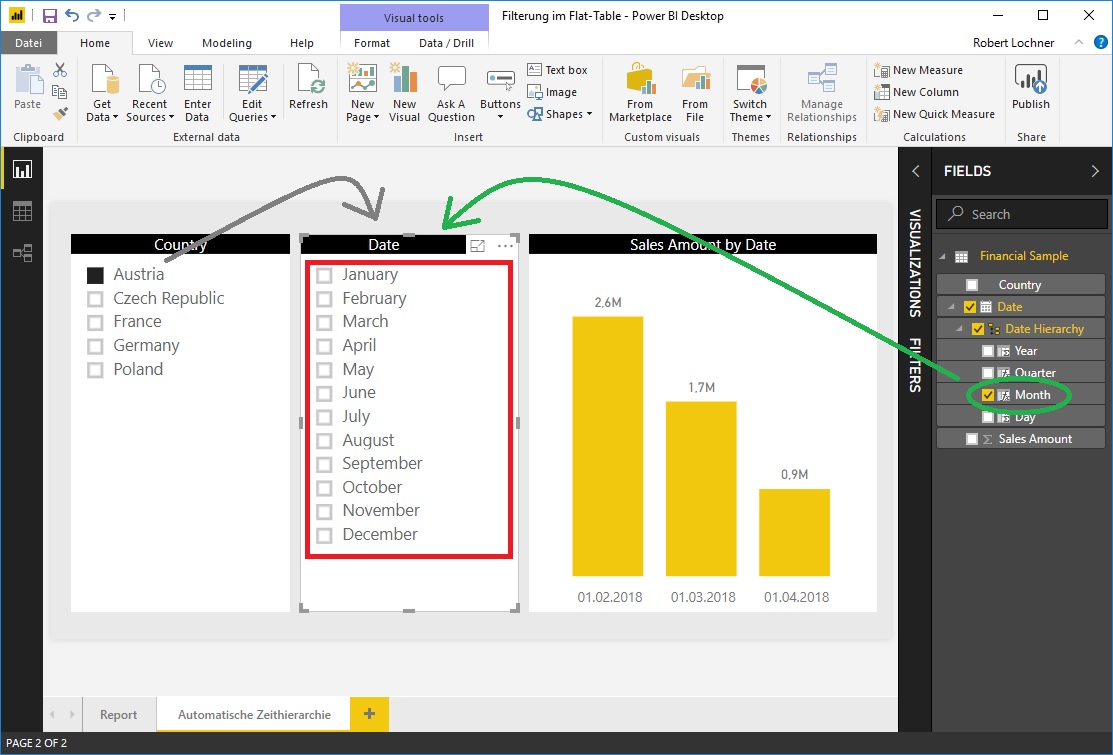
Eine Beeinflußung dieses Verhaltens ist uns nicht bekannt. Bei Bedarf könnte allerdings die Auto-Date Dimension durch Calculated Columns (für Jahr, Quartal, Monat) ersetzt werden.
2. Filterverhalten der Slicer im „Star-Schema“ Datenmodell
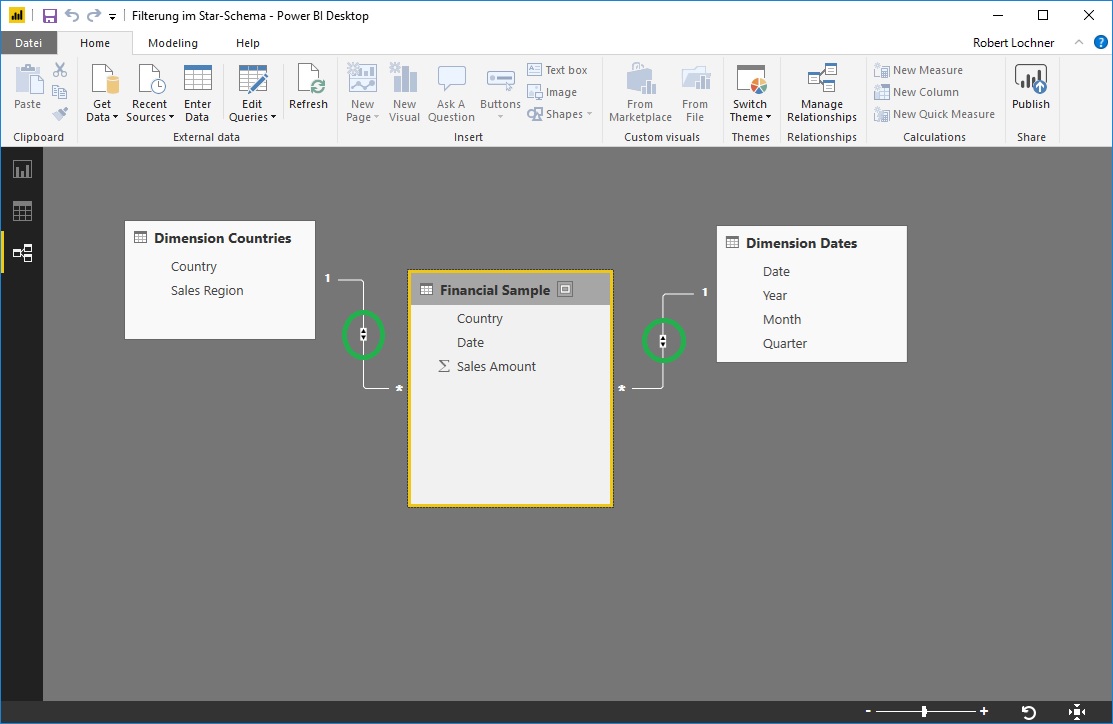
Werden zusätzlich zum Flattable zwei Dimensionstabellen für die Countries und die Dates eingelesen und in Beziehung gesetzt, ergibt sich ein einfaches Star Schema:

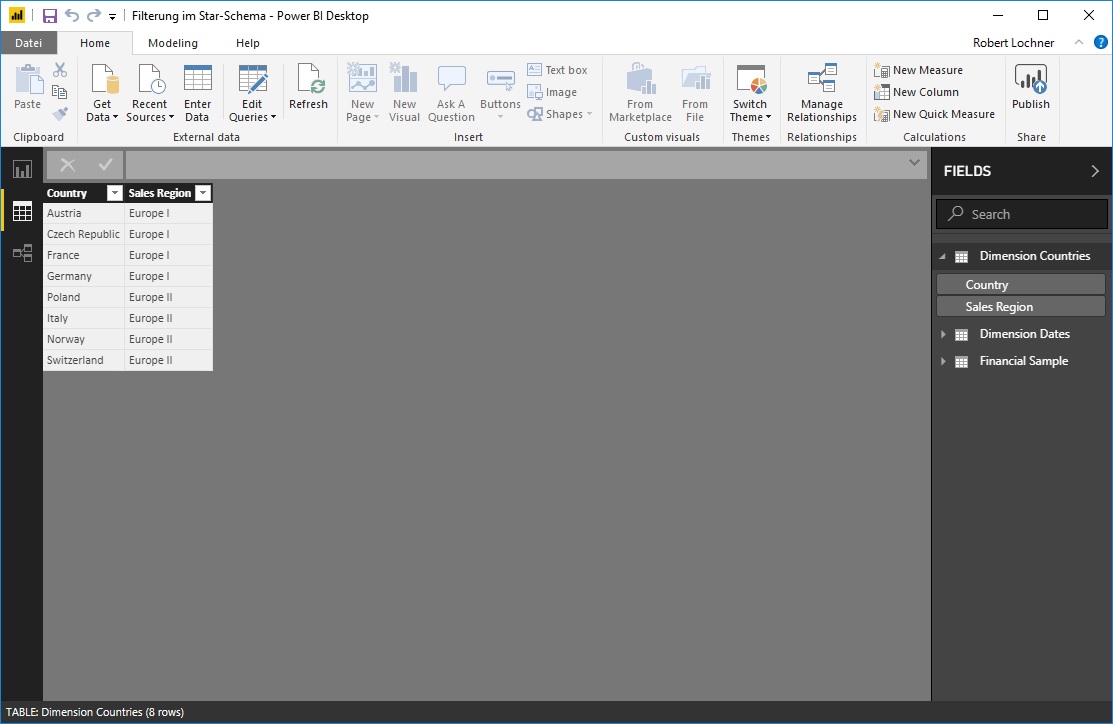
Zur Orientierung hier der Aufbau der sehr einfachen Tabelle Dimension Countries. Wesentlich ist hier, daß die Tabelle auch Länder enthält, die in der Faktentabelle (aktuell) keine Buchungen haben:
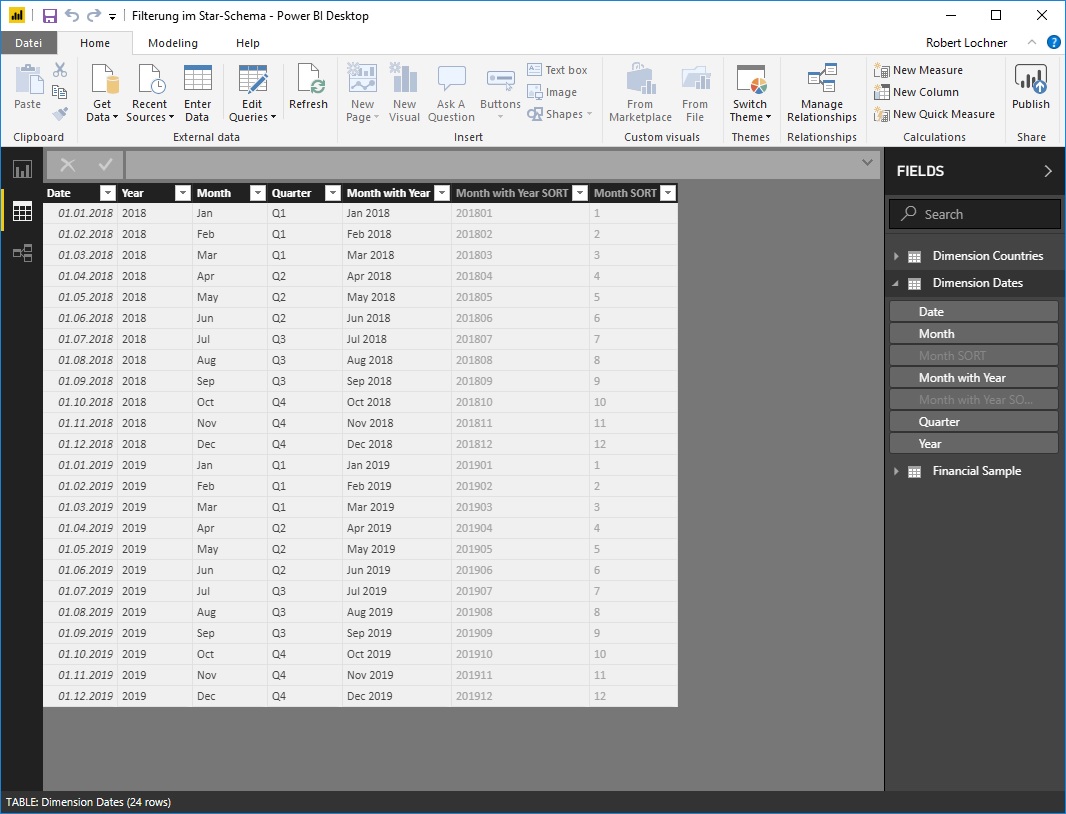
Analog dazu wurde die Dimension Dates nicht nur für die 4 aktuell bebuchten Monate sondern für das ganze Jahr definiert, die Tabelle enthält also auch unbebuchte Elemente:
Die Slicer haben im Star Schema folgendes Standardverhalten bezüglich der gegenseitigen Filterung:
- Slicer auf Felder der Faktentabelle filtern sich immer gegenseitig
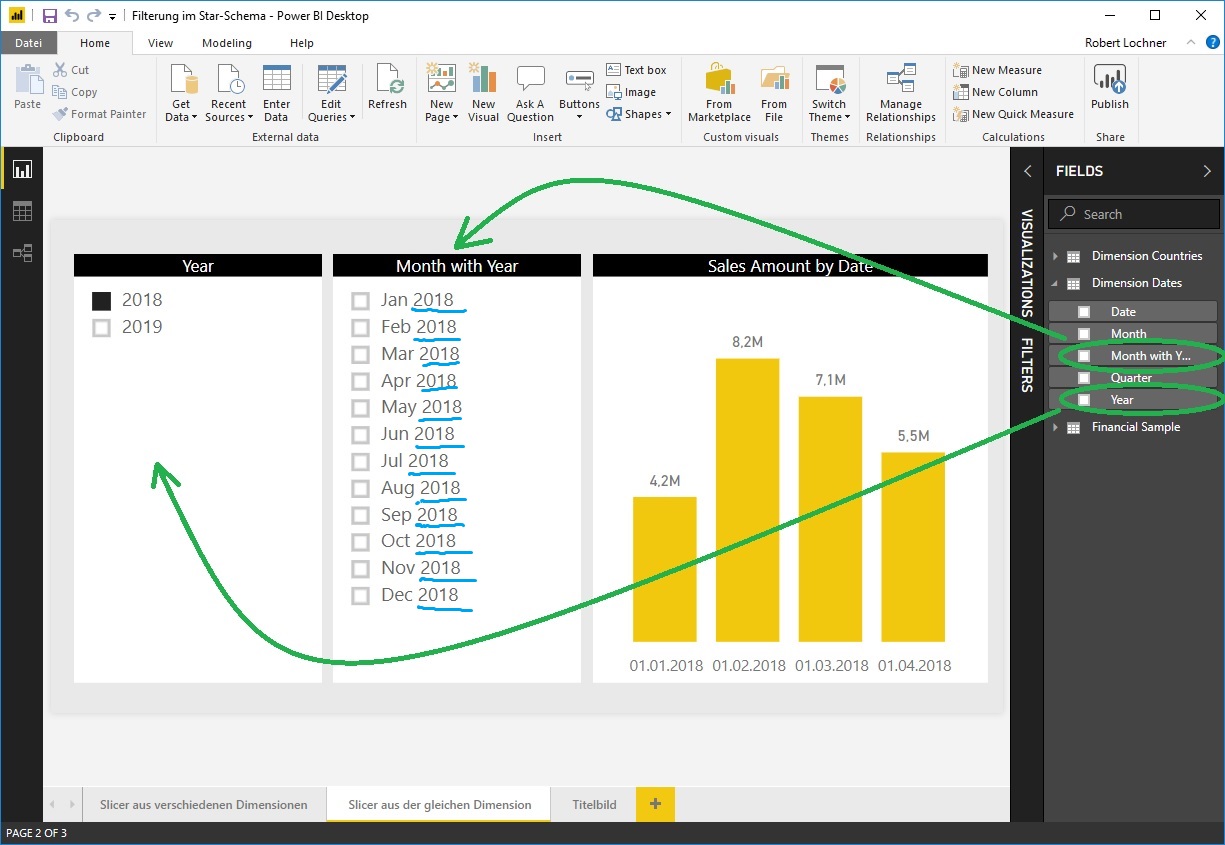
- Slicer auf Felder der gleichen Dimensionstabelle (bspw. Jahr und Monat), filtern sich zwar gegenseitig, aber nicht wie man das erwartet. Die Filterung findet nämlich nur auf Ebene der Dimenionstabelle statt ohne Berücksichtigung der Bebuchung in der Faktentabelle und daher nicht „intelligent“. Ein Jahres-Slicer filtert einen Monats-Slicer auf die 12 Monate des selektierten Jahres, aber nicht auf die bebuchten Monate:
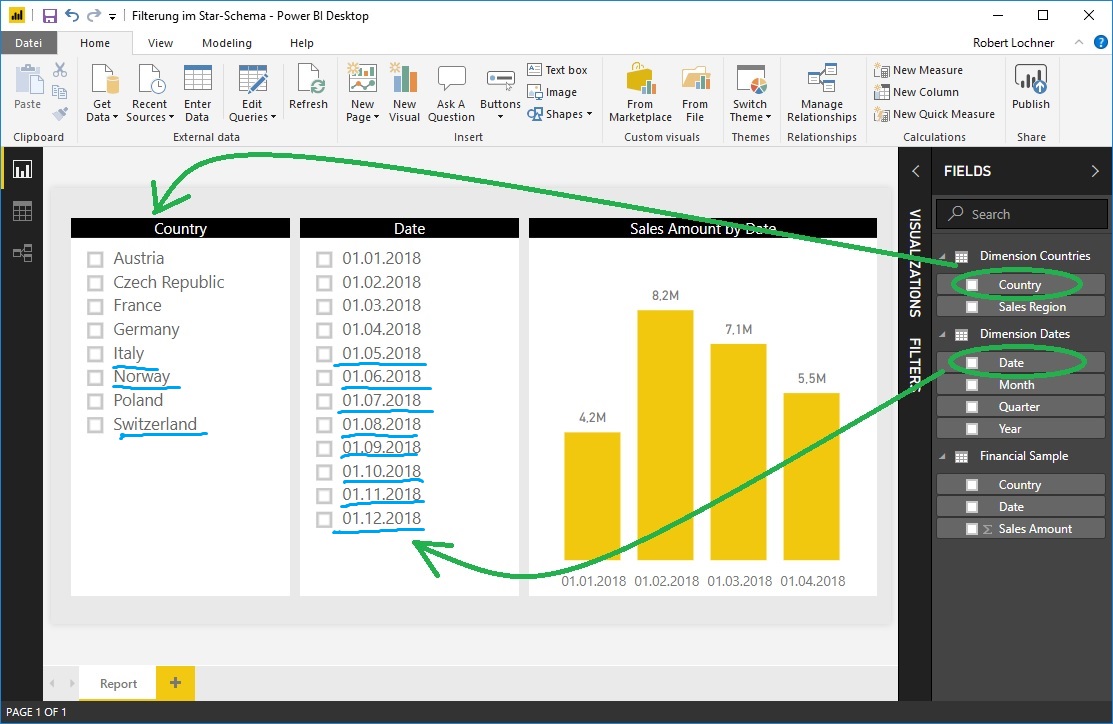
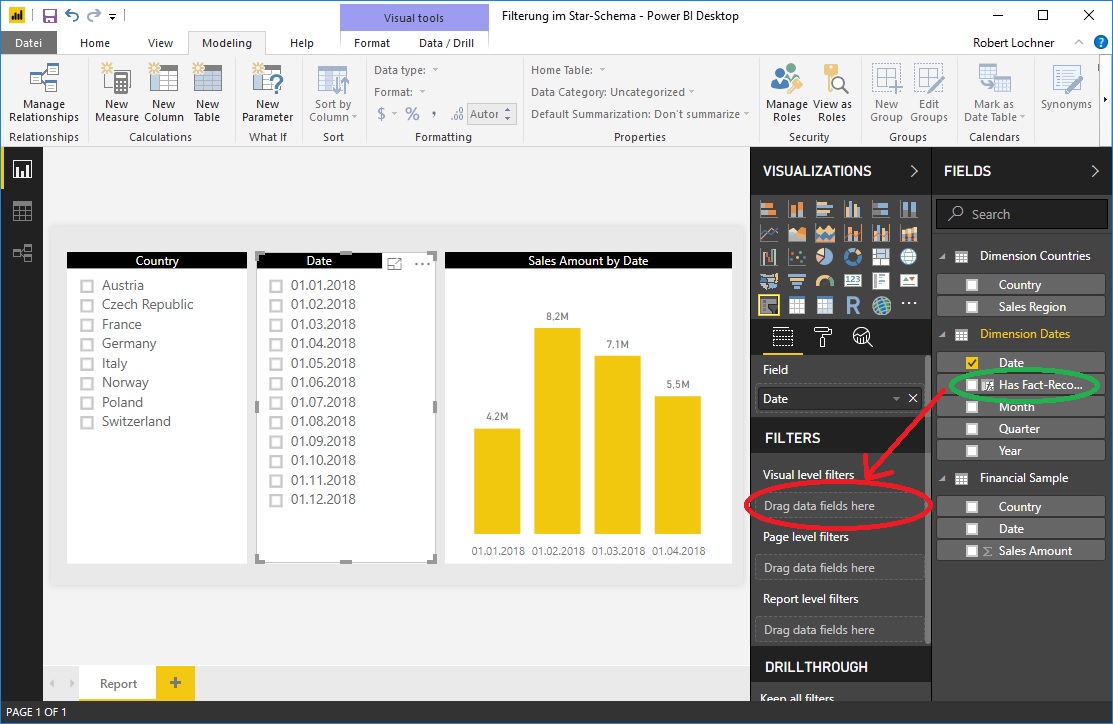
- Slicer auf Felder verschiedener Dimensionstabellen (bspw. Land und Produktgruppe) filtern sich in der Standardkonfiguration des Star Schemas gar nicht. Die Slicer zeigen also die dort definierten Einträge unabhängig davon, ob diese aktuell in der Faktentabelle Datensätze haben oder nicht:
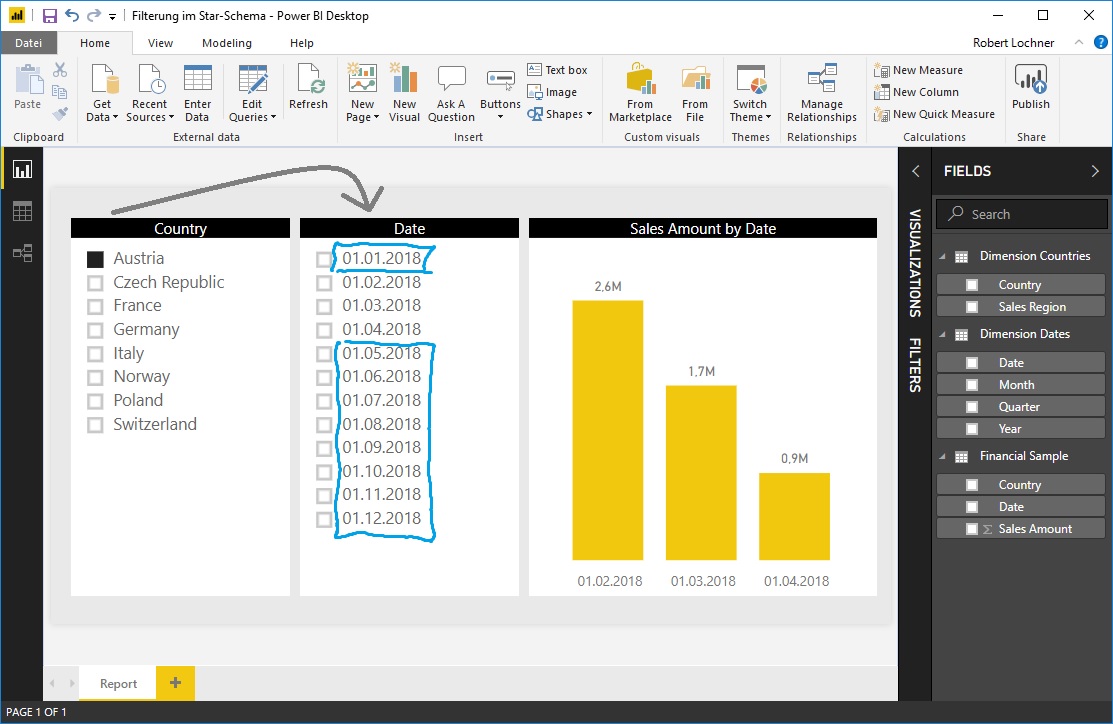
Bei der Selektion des Landes Austria paßt sich natürlich das Chart rechts an, nicht aber der zweite Slicer für die Datumswerte:
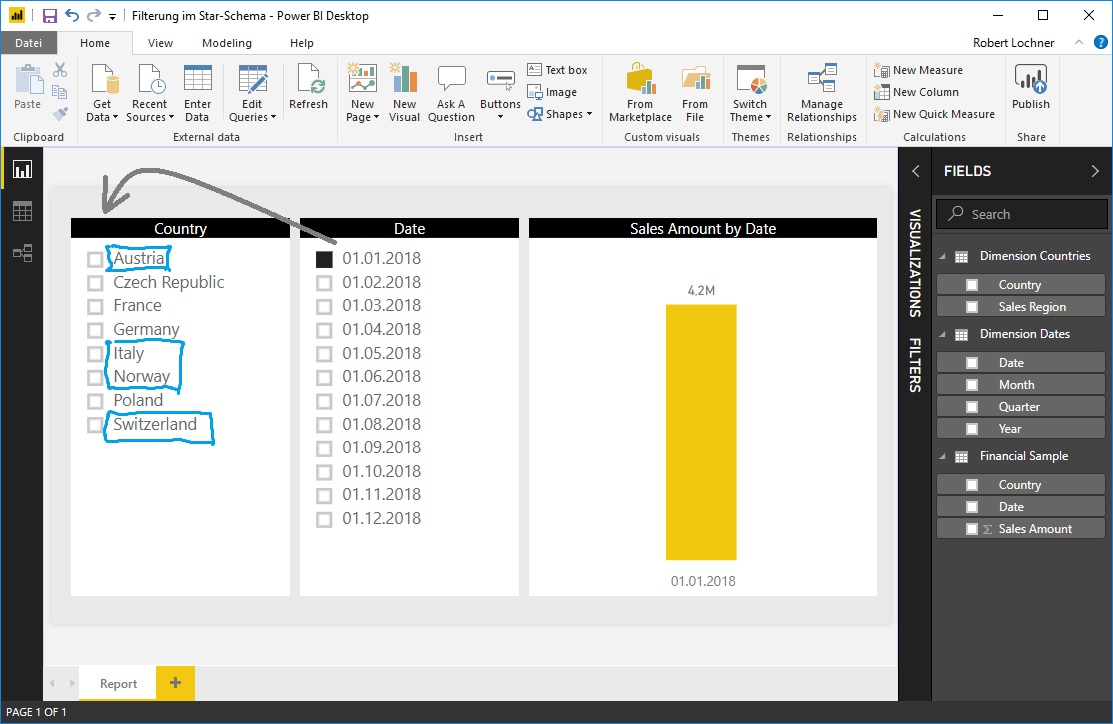
Und auch andersrum kommt es zu keiner Filterung des Länder-Slicers:
Die Slicer auf Attribute verschiedener Dimensionstabellen filtern sich also im Star Schema per default nicht gegenseitig.
Lösungsansatz „Wegfiltern der nicht bebuchten Dimensionselemente“
Um zumindest die generell unbebuchten Dimensionselemente zu exkludieren, könnte in jeder Dimensionstabelle eine Calculated Column mit einer Abfrage auf die Anzahl der korrespondierenden Datensätze in der Faktentabelle erstellt werden ….
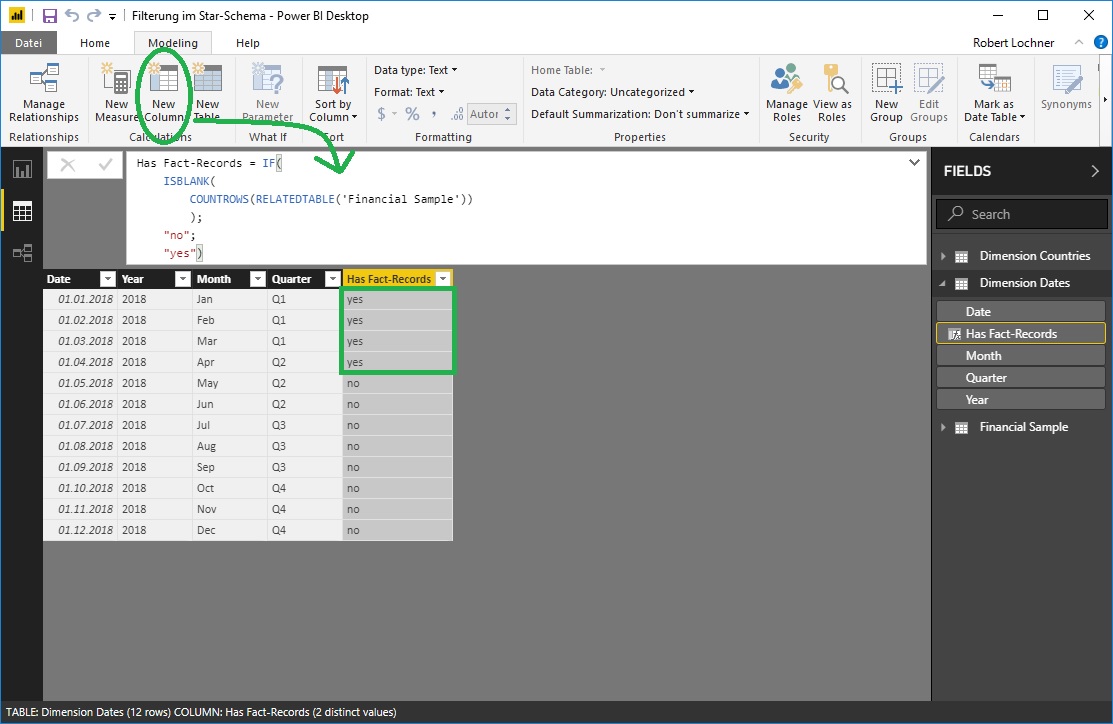
… um diese anschließend als Filterkriterium im Slicer-Visual zu verwenden. Leider unterstützt aber das Slicer-Visual – anders als alle anderen Visuals – keine Filter, sodaß diese Variante leider nicht zur erhofften Lösung führt:
Lösungsansatz „Löschen der nicht bebuchten Dimensionselemente“
Sofern die nicht bebuchten Dimensionselemente auch nicht für andere Zwecke benötigt werden, ist die einfachste Lösung natürlich, diese Elemente beim Einlesen dynamisch (mittels Bedingung im Query Editior) auszufiltern.
Insbesondere die Datumsdimension kann in der Regel aber nicht auf die bebuchten Datumswerte reduziert werden, da dann die Anforderung an die Definition als Date Table nicht mehr erfüllt wird („Lückenlosigkeit“) und die Nutzung der zahlreichen Time Intelligence DAX-Funktionen nicht mehr möglich ist.
Lösungsansatz „Bidirektionale Filterung“
Ein vielversprechender Lösungsansatz sowohl für die Ausfilterung der unbebuchten (und nicht löschbaren) Dimensionselemente als auch die gegenseitige Filterung der Slicer über die Dimensionstabellen hinweg, ist die Aktivierung der sogenannten bidirektionalen Filterung. Im Star-Schema ist diese Vorgehensweise grundsätzlich unproblematisch möglich (zu einer „Model Ambiguity“ kann es im Star Schema nicht kommen, lediglich sollte die Performance bei großen Anwendungen in einem Vorher/Nachher-Test genau abgeglichen werden):
Ein Filter auf das Land Austria filtert jetzt auch den Slicer für die Datumswerte …
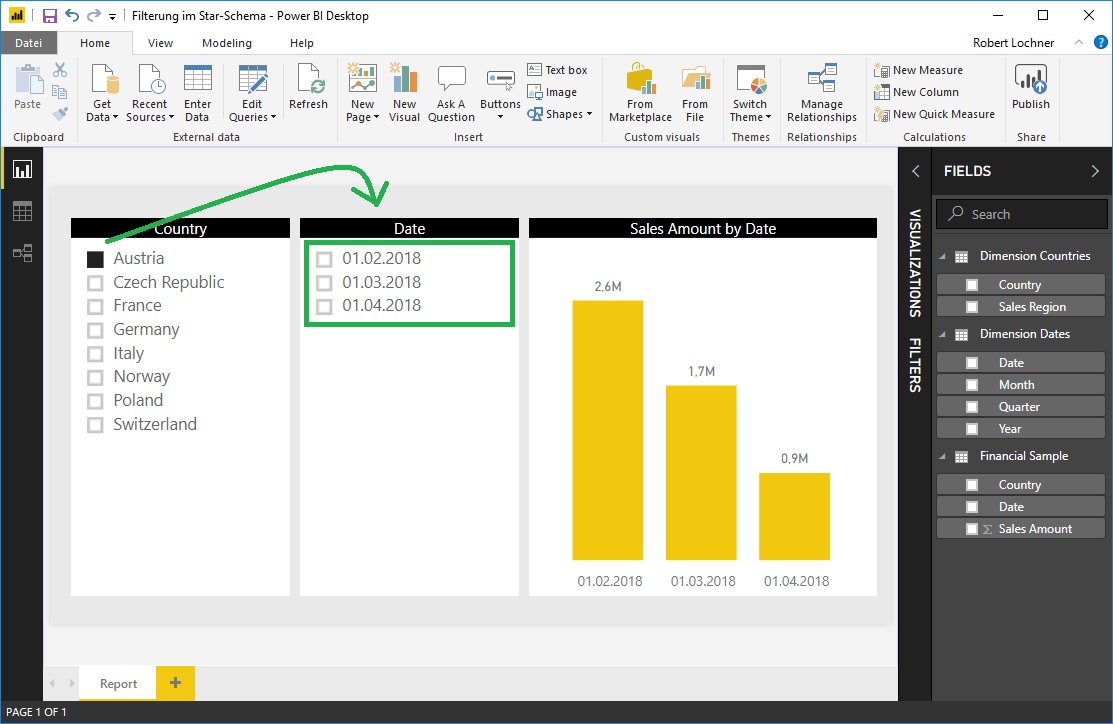
… jedoch führt die Selektion im Slicer Country zu keiner gefilterten Liste im Country Slicer selbst. Weiters werden, solange noch gar kein Filter gesetzt ist, alle Slicer ungefiltert mit allen (auch unbebuchten) Dimensionselementen dargestellt:
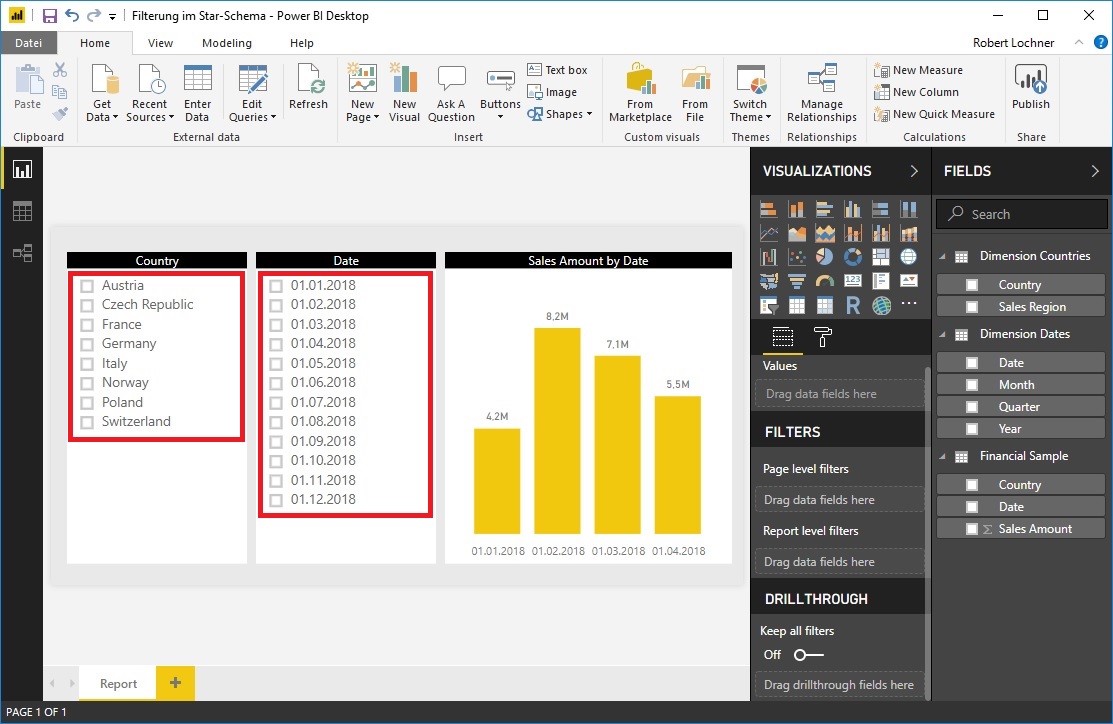
Hintergrund: die bidirektionale Filterung beginnt erst beim ersten aktiven Filter zu wirken und filtert nicht die Dimensionstabelle, in der dieser erste Filter gesetzt wird.
Lösungsansatz „Bidirektionale Filterung mit aktivem Dummy-Filter“
Ein Dummy-Filter könnte helfen, um die bidirektionale Filterung zu aktivieren. Wird in einer Dimensionstabelle ein Dummy-Element eingefügt, um dieses anschließend im Sinne eines Dummy-Filters – am effektivsten als Report Level Filter – auszufiltern, dann funktioniert das wiederum aus oben genanntem Grund nicht für die Slicer aus der Dimensionstabelle selbst:

Wird jedoch der Faktentabelle ein Dummy-Element hinzugefügt und dieses wieder weggefiltert, dann funktioniert diese Lösung schon sehr gut:
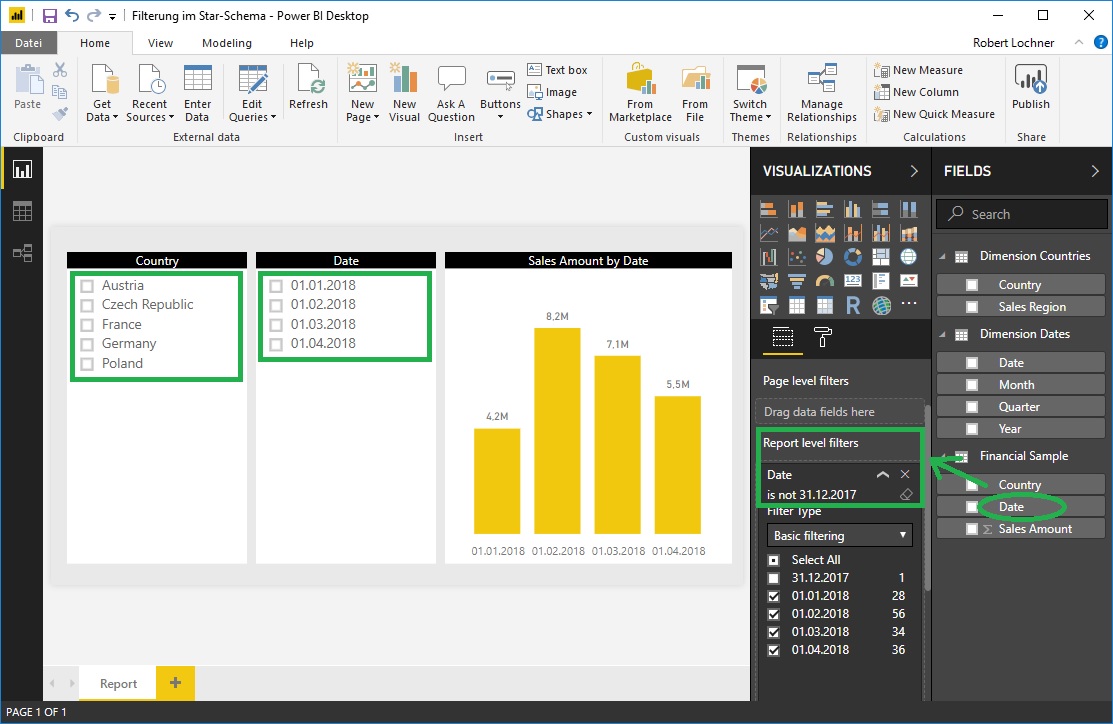
Der Import des tendenziell störenden Dummy-Elements ist bei näherer Betrachtung gar nicht notwendig, es kann einfach ein Advanced Filter auf ein Feld der Faktentabelle mit einer niemals eintretenden Bedingung definiert werden, um den gewünschten allgemeinen Filtereffekt zu erzielen:
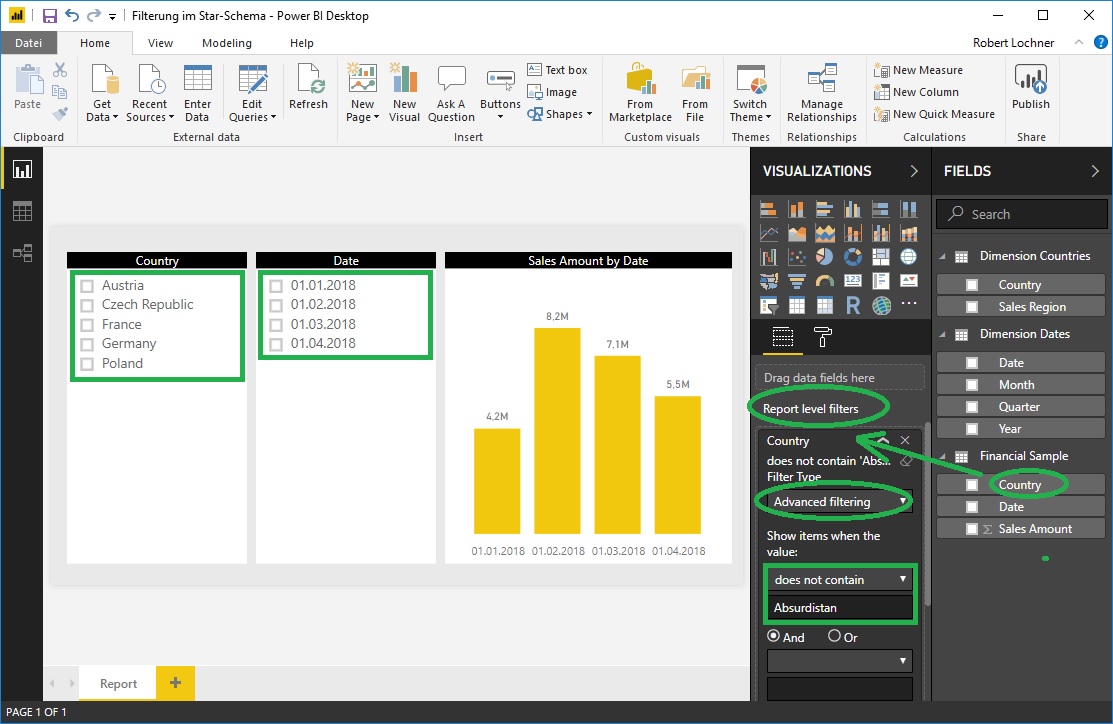
Lösungsansatz „Custom Visual Chiclet Slicer“
Nicht unerwähnt bleiben soll auch die Lösungsvariante, daß anstelle des Standard Slicers auch ein Custom Visual Slicer aus dem Marketplace verwendet werden könnte. So unterstützt der Chiclet Slicer von Microsoft die Aufnahme eines Measures zur datenbasierten Filterung der Slicer:
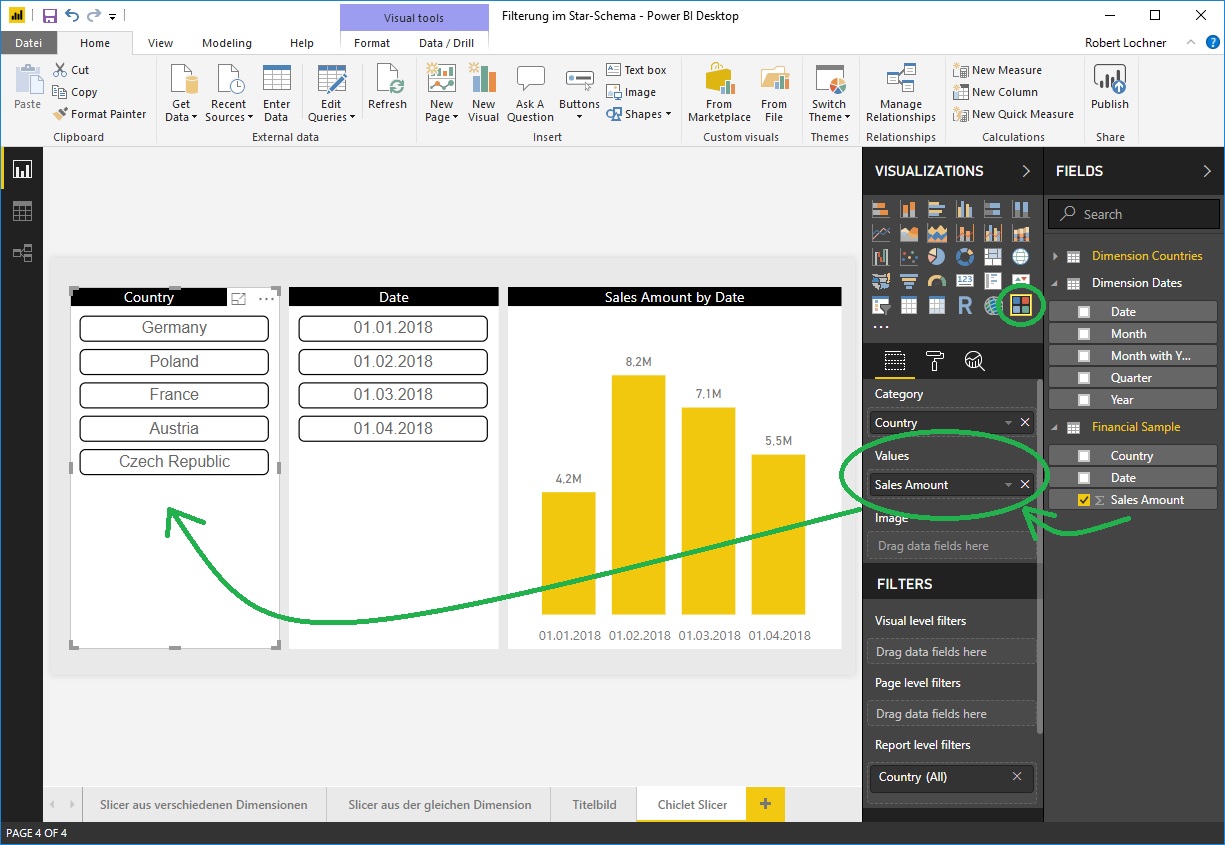
Für Einzelfälle ist das ein gangbarer Weg, wir raten aber davon ab, Custom Visual Slicer flächendeckend einzusetzen, da die Wartung nicht garantiert ist.
Fazit
Das „Star Schema“ ist aus vielerlei Hinsicht ein ideales Datenmodell in Power BI. Für Einsteiger erscheint dennoch ein „Flattable“ Datenmodell als sehr verlockende Alternative, dazu trägt auch das sehr intuitive gegenseitige Filterverhalten aller Slicer bei. Wie im Beitrag gezeigt, kann auch das Star Schema mit der bidirektionalen Filterung zum gleichen Filterverhalten gebracht werden und gleichzeitig alle Vorteile des Star Schemas genutzt werden. Existieren nicht bebuchte Elemente in einer (oder allen) Dimensionen, so kann mit einem Trick („Dummy-Filter“) die gefilterte Darstellung der Slicer auf die tatsächlich bebuchten Elemente erreicht werden.


3 Gedanken zu „Gegenseitiges Filtern von Slicer in Power BI“
Hallo,
könnte man das nicht auch durch eine Brückentabelle lösen?
VG
klingt interessant, funktioniert das auch bei einem Visual mit zwei Faktentabellen?
Ja grundsätzlich schon, die selbe Dimensionstabelle kann mit mehreren Faktentabellen verbunden sein. Klar, die Anzahl an bidirektionalen Beziehungen ist im Multi-Faktenmodell häufig eingeschränkt, nämlich dann wenn es (aufgrund der Art des Beziehungsgeflechts) zur sog. Model Ambiguity (= Mehrdeutigkeit von Beziehungen) kommen würde … hängt also vom konkreten Datenmodell ab. Viele Grüße, Robert Lochner