Mit dem R-Script Visual können auf sehr einfache Weise R-basierte Lösungen dynamisch in Power BI eingebunden werden. Das R-Package bupaR wiederum ermöglicht die Auswertung eines Datenbestandes mit Process Mining Algorithmen, damit steht Process Mining auch in Power BI zur Verfügung. Der folgende Beitrag gibt einen Überblick zum Thema und demonstriert anhand eines einfachen Beispiels, was erreicht werden kann.
1. Kurze Einführung in das Process Mining
Process Mining ist eine Data Mining Anwendung für das Prozessmanagement. Data Mining Verfahren im Allgemeinen sind Algorithmen, die hoch automatisiert und möglichst intelligent in großen Datenmengen nach Auffälligkeiten, Regeln und Mustern suchen (automatische Mustererkennung). Ein Prozess im Process Mining ist eine zeitlich geordnete Reihe einzelner Aktivitäten („activities“), die eine bestimmter Fall („case“) durchläuft.
Hier ein einfaches Beispiel:

Case #1 hat einen trace von 4 activities: f -> a -> c -> d
Case #2 hat einen trace von 3 activities: a -> b -> c
Case #3 hat wieder einen trace von 4 activities, aber f kommt doppelt vor
Für das Process Mining müssen folgende Anforderungen erfüllt sein:
- Die case ID muss eindeutig einen realen Fall abbilden
- Die activity ID muss anhand eines timestamps entsprechend dem tatsächlichen Ablauf eindeutig geordnet werden können
2. Das R-Package bupaR
R ist eine Programmiersprache für statistische Datenanalyse, die bereits 1992 entwickelt wurde. R erlebt in den letzten Jahren ein Revival, da es für viele moderne Data Science Aufgaben Lösungen liefert und in zahlreichen Tools wie Power BI integriert wird.
R ist ein Open Source Tool (unter der GNU Lizenz) und wird von der User Community (meist in akademischen Kreisen) in Form von Packages laufend weiterentwickelt. Derzeit existieren mehr als 15.000 Packages, auch für Process-Mining gibt es eines: bupaR. Die Dokumentation zu bupaR ist hier und hier zu finden.

Kurz zusammengefaßt benötigt das Package einen einfachen Datensatz mit lediglich 3 Spalten:
- case_id
- activity_id
- timestamp
3. R-Integration in Power BI
R kann in Power BI im sogenannten „R-Script Visual“ zur Berechnung und Visualisierung verwendet werden. Vereinfacht dargestellt funktioniert das so: Power BI übergibt (dynamisch aus dem sogenannten Filterkontext) Daten sowie ein R-Script und R liefert dafür eine Ergebnisgrafik zurück, die dann im R-Visual in Power BI dargestellt wird.
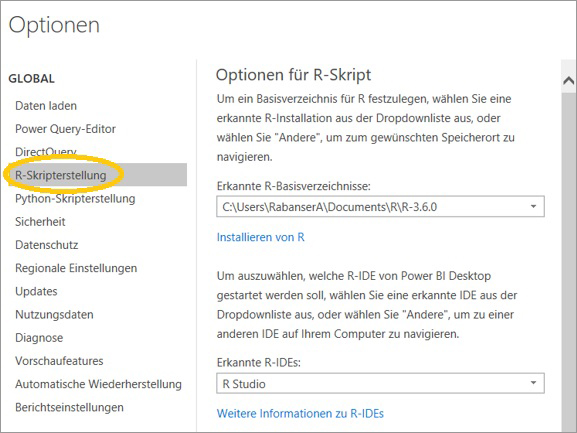
In Power BI Desktop funktioniert das R Visual nur, wenn eine lokale Installation von R vorhanden ist und diese auch von PBI Desktop erkannt wird:
Im Power BI Service ist R standardmäßig installiert, jedoch sind dort nicht alle erdenklichen Packages verfügbar und können nicht individuell hinzugefügt werden (mehr dazu hier).
Hinweis: R kann in Power BI auch in der Power Query Komponente zur Datenaufbereitung eingesetzt werden, diese Methode kommt aber für den vorliegenden Anwendungsfall nicht zur Anwendung.
4. Konkreter Use Case: Auswertung eines Logs
4.1 Ausgangsdaten
Analysiert wird ein Auszug der Log-Datensätze des Cloud Services data1.io. Zur einfachen Nachvollziehbarkeit in diesem Blogbeitrag wird der sehr einfache Prozesstyp 4. LOAD ausgewertet und der Filter so gesetzt, daß nur 47 Prozesse („Cases“) zu analysieren sind. Diese 47 Prozesse bestehen aus 1 bis 3 Log-Datensätzen („Activities“):
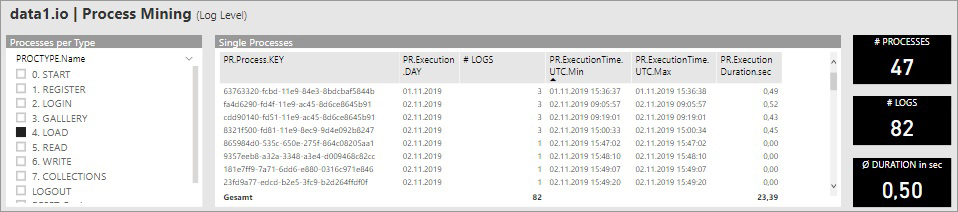
Der Case ist durch den PR.Process.KEY eindeutig gekennzeichnet, die einzelnen Activities heißen hier PROCSTEP.NAME. Der Timestamp gibt die Reihenfolge der einzelnen Schritte eines Case wieder, aus Modellierungsgründen ist dieser auf eine Datums- und eine Uhrzeitspalte (mit Millisekunden) aufgeteilt:

4.2 R-Script Visual erstellen
Zuerst wird über den Visualizations Bereich ein neues R-Script Visual in den bestehenden Report hinzugefügt, es erscheint auch gleich der Script-Eingabebereich sowie die Aufforderung zur Belegung mit den relevanten Feldern aus der Power BI Feldliste:

Als nächsten sind die relevanten Felder aus dem Power BI Datenmodell dem Visual zuzordnen:

4.3 R-Script erstellen
Diese Felder werden im R-Script als data.frame unter dem Namen dataset übergeben:

Bevor wir die Werte verarbeiten können, sind im Script alle R-Packages angeführt, die installiert sein müssen:
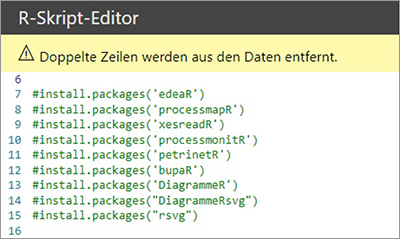
Obwohl üblicherweise mit install.packages („bupaR“) auch alle dependencies berücksichtigt werden, war es hier dennoch nötig, die anderen angeführten packages auch zu installieren. Weiters war es notwendig, den Library Pfad zusätzlich zum Pfad in den Power BI Settings (siehe oben) über einen Befehl im Script nochmals zu setzen. Nach diesen Vorbereitungen können die Libraries im Script geladen werden:

Nun werden die Daten aus Power BI in das Script geladen und das data.frame weiter an die Variable inputDaten übergeben:

Es folgen anwendungsspezifische Datentransformationen zum timestamp, weiters werden die Daten aus dem data.frame inputDaten an eigens benannte Vektoren übergeben, die dann im package bupaR verwendet werden. Das package bupaR verwendet eine eigene Datenstruktur, die mit der function eventlog() aus dem data.frame erzeugt werden kann:
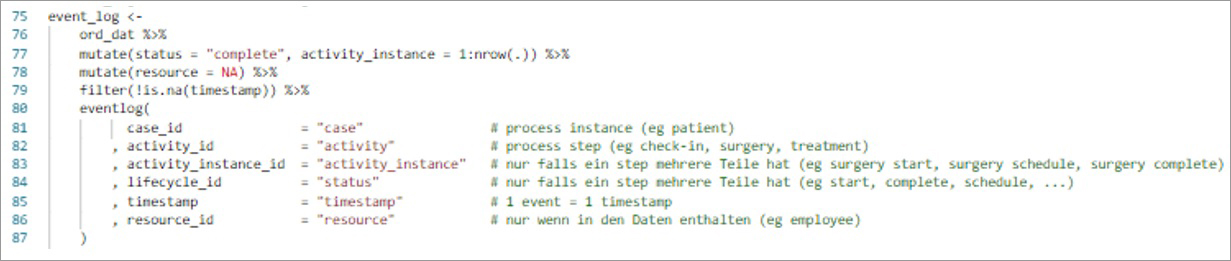
4.4 Ergebnisgrafik process_map
Nun ist alles getan, um die erste Ergebnisgrafik zur Ausgabe im Power BI Visual zu erstellen:

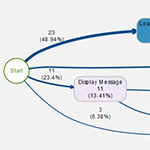
Mit der function process_map wird ein Ablaufdiagramm der Prozesse erstellt, in dem absolute und relative Häufigkeiten angeführt sind:
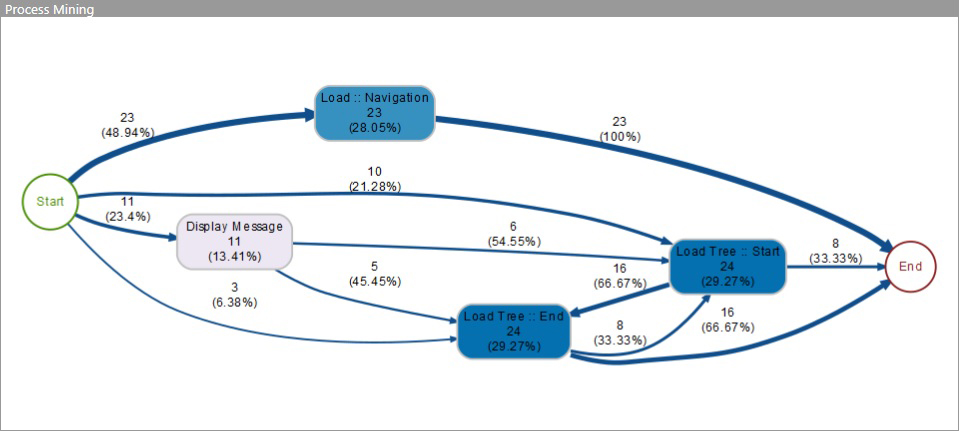
Die Grafik dient dazu, einen Überblick über die existierenden Prozesspfade („traces“) zu bekommen und deren Relevanz einzuschätzen:
- Boxen sind Prozesschritte („activities“): je öfter ein Prozessschritt durchlaufen wurde, desto dunkler wird die Box dargestellt. Werte in den Boxen = wie oft wird der Prozessschritt ausgeführt
- Die Pfeile veranschaulichen die Prozesspfade („traces“), in denen die einzelnen Prozessschritte durchlaufen werden: je öfter, desto dicker sind die Pfeile dargestellt. Werte bei den Pfeilen = wie oft wird der Weg zwischen den Schritten durchlaufen
Die relativen Häufigkeiten beziehen sich dabei auf die Anzahl der Prozessschritte (Boxen) oder die Anzahl an durchlaufenen Pfaden (Pfeile).
- Bsp. Box Load :: Navigation
Diese activity wurde 23 mal ausgeführt, das sind 28,05% aller activities - Bsp. Pfeil Start -> Load :: Navigation
Dieser trace wurde 23 mal durchlaufen, das sind 48,94% aller Pfade vom Start weg
4.5 Ergebniskarte Anzahl Cases + Anzahl Traces
Mit demselben script lassen sich jetzt zahlreiche weitere Visuals erstellen. Geändert wird im script nur der letzte Codeblock, der die Grafik erstellt. Mit der folgenden Script Variation wird einfach die Anzahl der ermittelten Cases und vor allem die Anzahl der vorkommenden Traces ausgegeben:


Die Darstellung erfolgt ganz simpel als Text, die 5 verschiedenen Traces können auch in der process_map oben identifiziert werden (bei komplexeren Auswertungen wäre aber die Anzahl der Traces nur mit viel Aufwand in der Grafik manuell abzählbar).
4.6 Ergebnisgrafik trace_explorer
Hier etwa die function trace_explorer: mit ihr werden die einzelnen Abfolgen an Prozessschritten der Häufigkeit nach geordnet angeführt:

Beispielsweise 48,94% der traces besteht nur aus dem Prozessschritt Load :: Navigation, 21.28% der traces dagegen bestehen aus den beiden Schritten Load :: Start und Load :: End, usw. Die Anzahl der Traces wird hier durch die Anzahl der Balken auf der Y-Achse abgebildet. Die Darstellung als trace_explorer ist zwar weniger spektakulär als als process_map, in der Praxis aber vermutlich in vielen Fällen besser geeignet.
4.7 Ergebnisgrafik activity_precence
Die function activity_precence bringt den Fokus auf die Häufigkeit der einzelnen Prozesschritte: hier wird die Häufigkeit jeder activity angeführt, relativ zur Gesamtanzahl an cases.

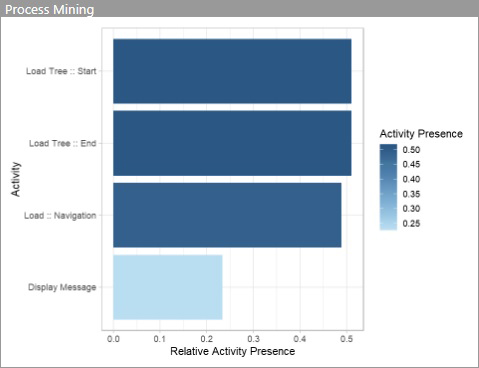
Bespielsweise kommen Load :: Start und Load :: End je in rund 50% der cases vor.
5. Grenzen der Anwendung
Nach dem bisherigen Erkenntnisstand zum bupaR Package sind folgende Grenzen der Anwendung zu beachten:
- Alle Timestamps müssen unterschiedlich sein
Das ist eine sehr zentrale Voraussetzung, die gar nicht so leicht zu erfüllen ist. So darf es keine ex-aequo im Timestamp geben, es kann leider nicht einfach eine zusätzliche Sortierspalte als „Vorrangregel“ angegeben werden. Die Behandlung dieser Thematik im R-Skript ist tendenziell sehr langsam und sollte daher jedenfalls bereits bei der Datenaufbereitung beim Laden der Daten nach Power BI (oder in der Datenquelle) gelöst werden.
- Ergebnisgrafiken skalieren häufig sehr schlecht und sind tw. nicht lesbar
Die vorgestellte process_map beinhaltet sehr viel und nützliche Information, wird allerdings bei größeren Mengen an activities und traces sehr unübersichtlich, wie folgendes Beispiel zeigt:
Die Ergebnisgrafik kann leider nicht gezoomt werden, daher sind solche unleserlichen Ergebnisse nicht weiter auswertbar und es muß zu den anderen vorgestellten Grafiken gewechselt werden.
- Ergebnisgrafiken werden teilweise gar nicht oder sogar als fehlerhaft dargestellt
Bei der Card für die „Anzahl Cases + Anzahl Traces“ kommt es häufig zu einer falschen Skalierung des Textes und das Ergebnis kann daher bspw. erst beim Wechsel in den Focus Mode des Visuals gelesen werden.
Fallweise wird sogar eine kryptische Fehlermeldung angezeigt, obwohl es sich lediglich um eine Auflösungproblem handelt und das Script unverändert ist:
- Nicht alle Packages im Cloud Service verfügbar
In der hier vorgestellten Anwendung kann die zuletzt gezeigte Ergebnisgrafik aus der function activity_precence im Power BI Cloud Service nicht ermittelt werden, da das zugrundeliegende Package dort nicht verfügbar ist (siehe weiterführend hier).
Weiterführend
https://docs.microsoft.com/en-us/power-bi/desktop-r-visuals
https://docs.microsoft.com/en-us/power-bi/service-r-packages-support