In Krisenzeiten wie dem aktuellen weltweiten Corona Lockdown ersetzt der Forecast das Budget. Die Kombination der beiden Technologien data1.io (dezentrale Datensammlung) und Power BI (Dashboarding) liefert ein sehr flexibles, effizientes und in wenigen Tagen zu implementierendes Instrument zur Steuerung des Unternehmens in sehr volatilen Zeiten. Es ermöglicht Unternehmen täglich, wöchentlich und monatlich ihre Pläne zu aktualisieren, um überlegt und daten-basiert weitreichende Entscheidungen treffen zu können.
Im ersten Teil diese Blogserie haben wir gezeigt, wie mit unserem Cloud Service data1.io die dezentralen Informationen aus den Tochtergesellschaften eines kleinen Konzerns systemgestützt von den dort Verantwortlichen eingesammelt werden können. Im zweiten Teil zeigen wir jetzt, wie die gesammelten Daten mittels ODATA Feed direkt an Power BI übergeben werden können und wie die Informationen dort mit Hilfe einiger Measures effektiv visualisiert werden können. Auf dieser Datenbasis werden dann laufend in den Managementmeetings die entsprechenden Maßnahmen abgeleitet.
Fertiges Dashboard (= Zielsetzung)
Ein rasch implementiertes Dashboard in Power BI könnte folgendermaßen aussehen:
Hinweis: das Power BI Dashboard ist live eingebunden, Sie können also die Reports interaktiv testen! Beachten Sie bitte, daß bei der Kennzahlenauswahl auf Ebenen mit ungültiger Aggregation keine Daten angezeigt werden (mehr dazu weiter unten).
Schritt 1: Anbindung der Daten mittels ODATA-Feed
Wie im ersten Teil gezeigt, können die mittels Collection Workflow eingesammelten Daten über mehrere Methoden weiterverwendet werden. Die wichtigste ist der sogenannte ODATA Feed. Es handelt sich dabei um eine SQL ähnliche Bereitstellung von Daten (also in Tabellenform) über eine Web API (also über eine URL). Der data1.io Cloud Service stellt dem sog. „Application Owner“ die Zugangsdaten – URL und Credentials – in der Web App zur Verfügung:
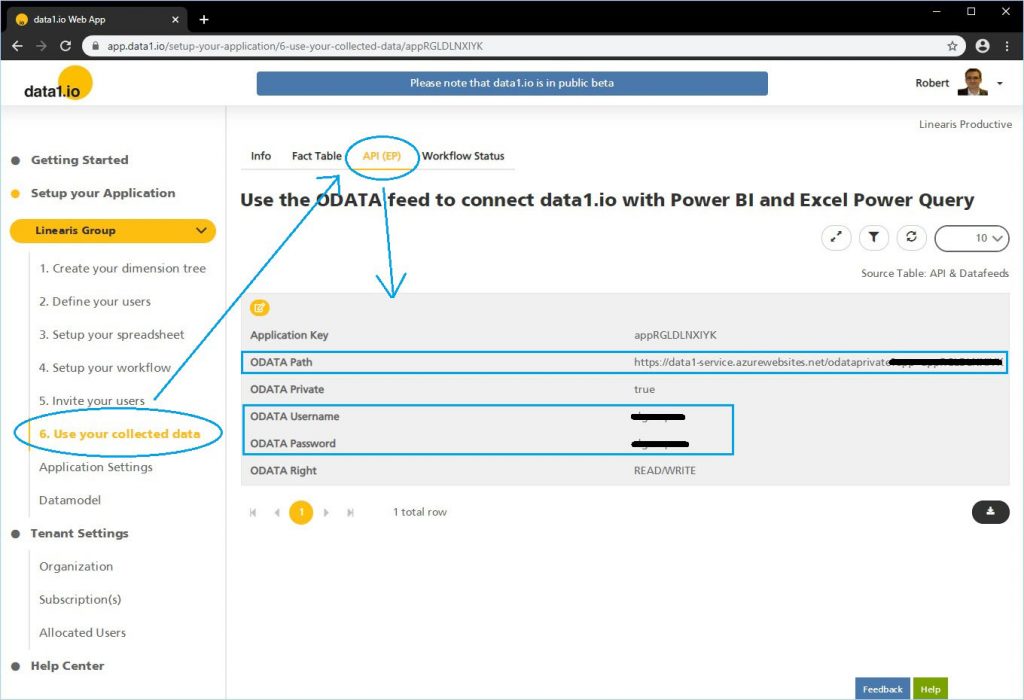
Hinweis: der ODATA Feed ist nur im Enterprise Plan und nicht im Free Plan verfügbar. Zum Testen kann aber auch der frei zugängliche ODATA Feed (https://data1-service.azurewebsites.net/odatapub) unserer Public Showcases verwendet werden (es gibt dort allerdings keine Workflow Tabellen, da diese Funktionen in den Public Showcases deaktiviert sind).
In Power BI – oder auch in Excel Power Query oder SQL Server Tabular Model – wird im ersten Schritt der ODATA Konnektor aus der Liste der verfügbaren Konnektoren ausgewählt:
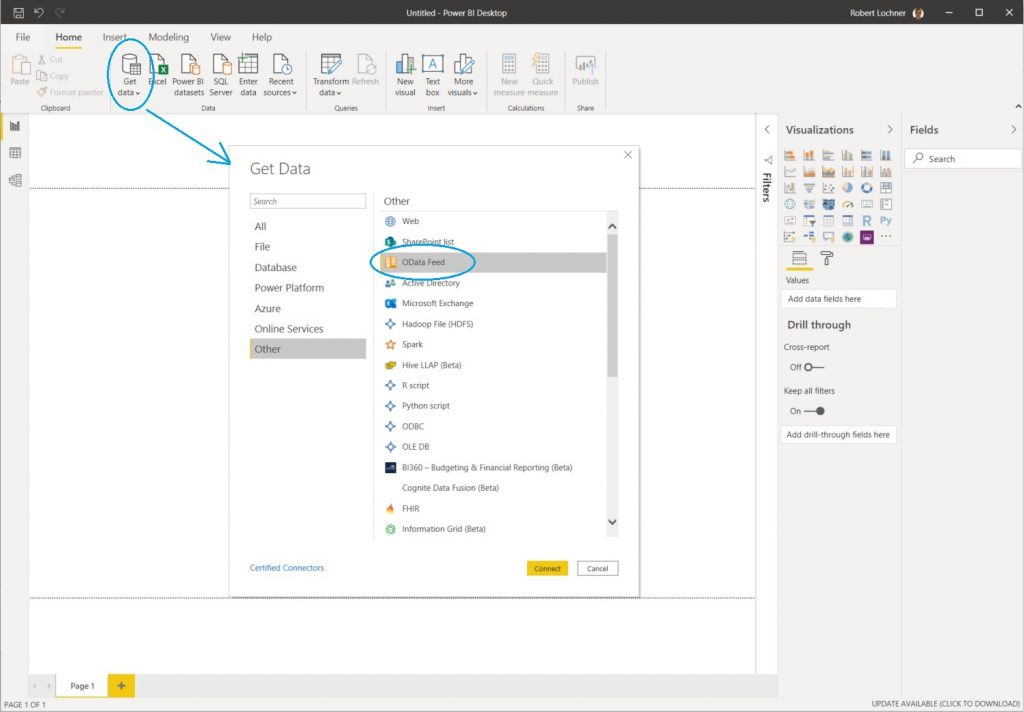
Jetzt wird die URL für den ODATA Feed einkopiert …
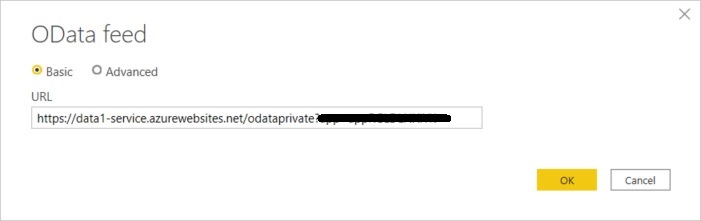
… und die bereitgestellten Credentials eingegeben:
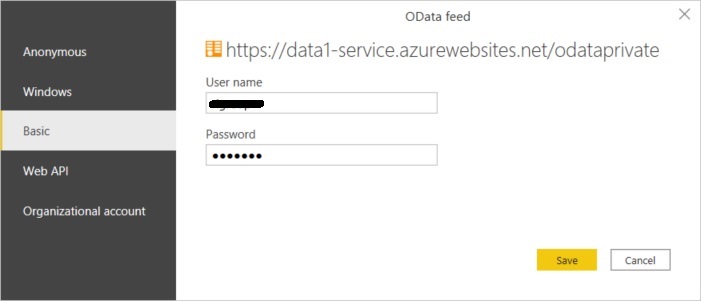
Im Navigator werden alle im ODATA Feed verfügbaren Tabellen zur Auswahl angeboten. Primär brauchen wir die Faktentabelle (APP_FACT01), ergänzend aber auch die beiden Dimensionstabellen für den Dimension Tree (APP_DIM001) sowie die im data1.io Datamodel zusätzlich definierte Metrics Dimension (APP_DIM003, mehr dazu weiter unten). Die Workflow Tabellen ermögilchen die Visualisierung des Erfassungsstatus der einzelnen Teilnehmer und auch die Auswertung der vom System automatisch versendeten Workflow e-Mails:
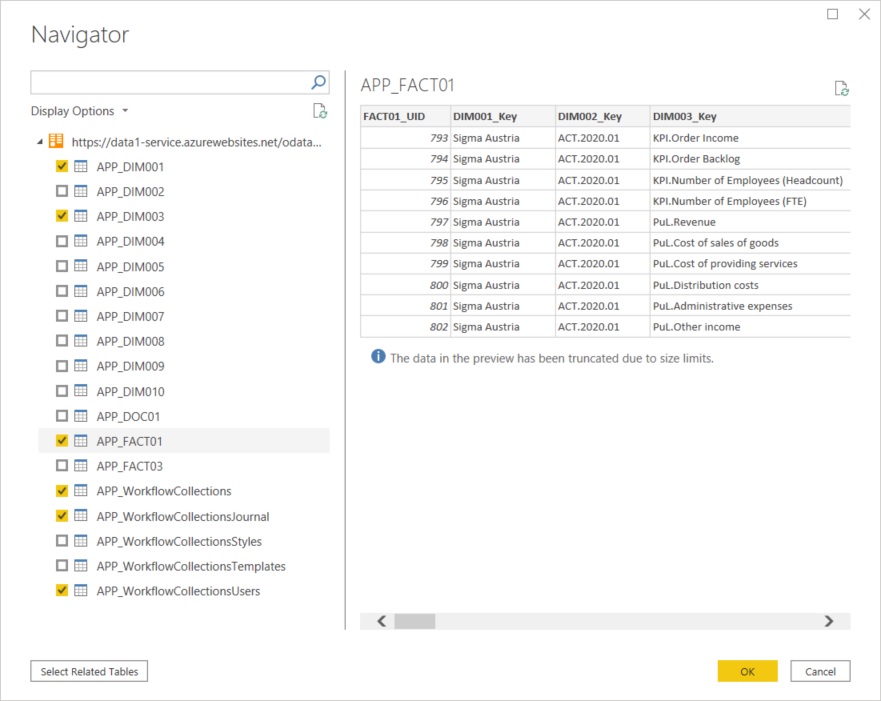
Im Power Query Editor ist jetzt etwas Arbeit notwendig, um aus den technischen Bezeichnungen der Tabellen und Felder sprechende Tabellen für das Power BI Datamodel zu gestalten:
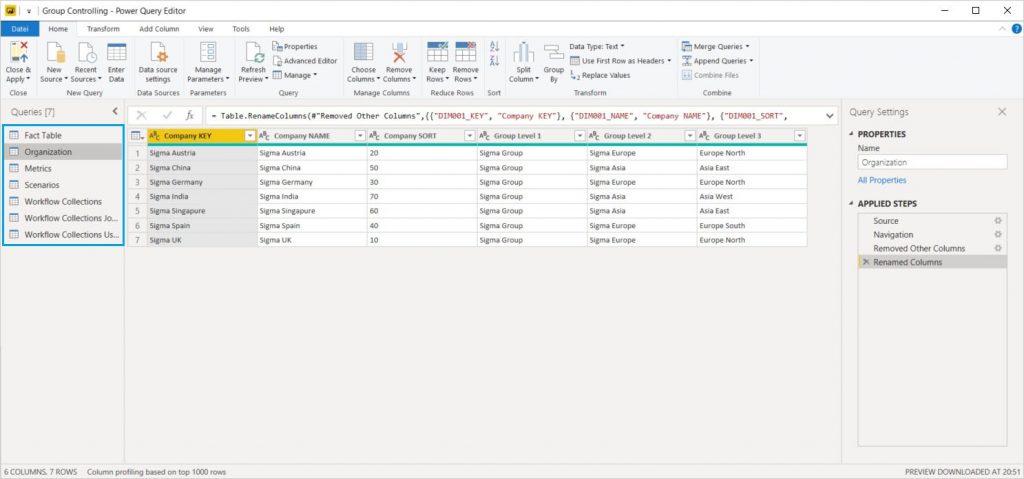
Die Faktentabelle muß zusätzlich auf die aktuell gültigen Datensätze („IsDeleted = False“) gefiltert werden, da data1.io im Standard bei jedem WRITE Prozess die bereits bestehenden Vorgängerdaten des Datenpakets nicht löscht sondern lediglich als gelöscht kennzeichnet (um ein Rückgängigmachen von Eingaben zu ermöglichen).
Die Dimensionstabelle Scenarios wird mittels Reference Query direkt aus der Faktentabelle abgeleitet (berechnete Tabelle), das erspart uns die manuelle Wartung einer weiteren Dimensionstabelle im data1.io Datamodel.
Schritt 2: Power BI Datamodel
Die importierten Fakten- und Dimensionstabellen werden im Power BI Datamodel zu einem klassischen Star Schema verknüpft und die Tabellenfelder werden semantisch angereichert (Formatierungen, Default Summarization, Data Categories, Sort-by-Column, usw.):
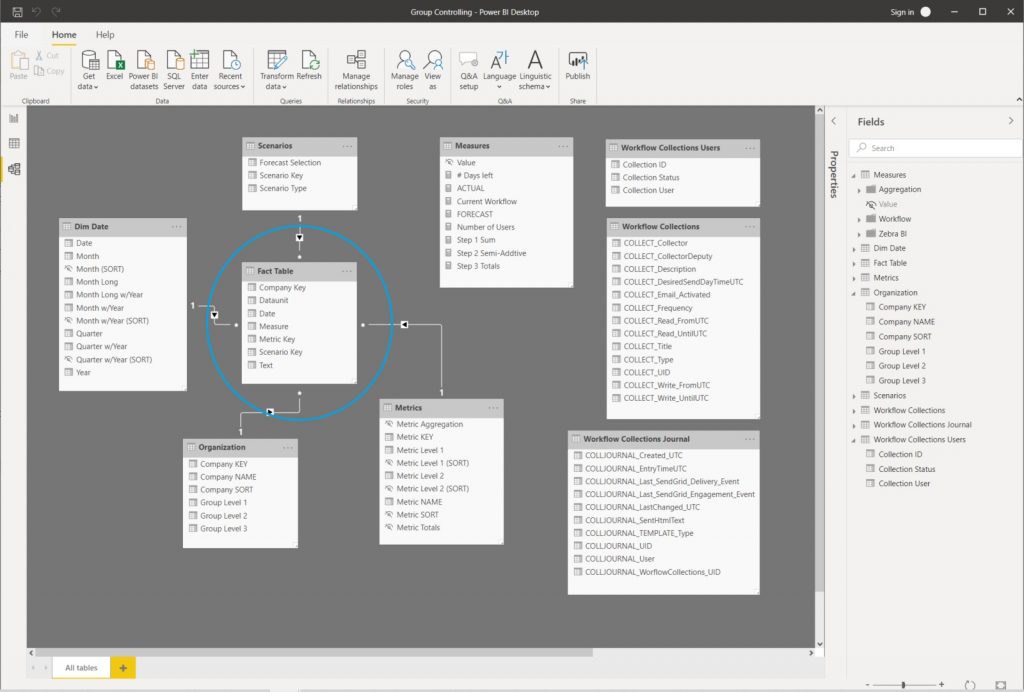
Die Dimensionstabelle Dim Date wird als Calculated Table mittels DAX-Statement erzeugt (hätte aber ebenso als dynamische Query implementiert werden können) und anschließend als Date Table deklariert (auch wenn vorerst noch keine Time Intelligence Berechnungen benötigt werden):
Dim Date =
ADDCOLUMNS (
CALENDAR(
DATE( YEAR( MIN('Fact Table'[Date]) );1 ;1 );
DATE( YEAR( MAX('Fact Table'[Date]) );12; 31 )
);
"Year"; YEAR( [Date]) ;
"Quarter"; "Q" & QUARTER( [Date] );
"Quarter w/Year"; "Q" & QUARTER( [Date] ) & " " & YEAR( [Date] );
"Quarter w/Year (SORT)"; YEAR( [Date] )*100 + QUARTER( [Date] );
"Month"; FORMAT( [Date];"MMM") ;
"Month Long"; FORMAT( [Date];"MMMM" );
"Month (SORT)"; MONTH( [Date] );
"Month w/Year"; FORMAT( [Date];"MMM" ) & " " & YEAR( [Date] );
"Month Long w/Year"; FORMAT( [Date];"MMMM" ) & " " & YEAR( [Date] );
"Month w/Year (SORT)"; YEAR( [Date] )*100 + MONTH( [Date] )
)Die Workflow Tabellen stehen unverbunden als Disconnected Tables im Datenmodell und liefern ergänzende Informationen zu den gesammelten Daten. Die Measures werden in einem leeren (und natürlich unverknüpftem) Measure Table angesiedelt, der ebenfalls als Calculated Table mittels DAX-Statement erzeugt wird:
[ Measures] = {Blank()}Dazu diese ersten 3 Measures:
TOTAL = SUM('Fact Table'[Measure])ACTUAL = CALCULATE(
[TOTAL];
Scenarios[Scenario Type] = "ACT"
)FORECAST = CALCULATE(
[TOTAL];
Scenarios[Scenario Type] = "FC"
)Schritt 3: Visualisierung einzelner Kennzahlen aus der Metric Dimension
Die Visualisierung der gesammelten Informationen kann natürlich auf viele verschiedene Arten erfolgen, hier ein möglicher Aufbau eines Dashboards:
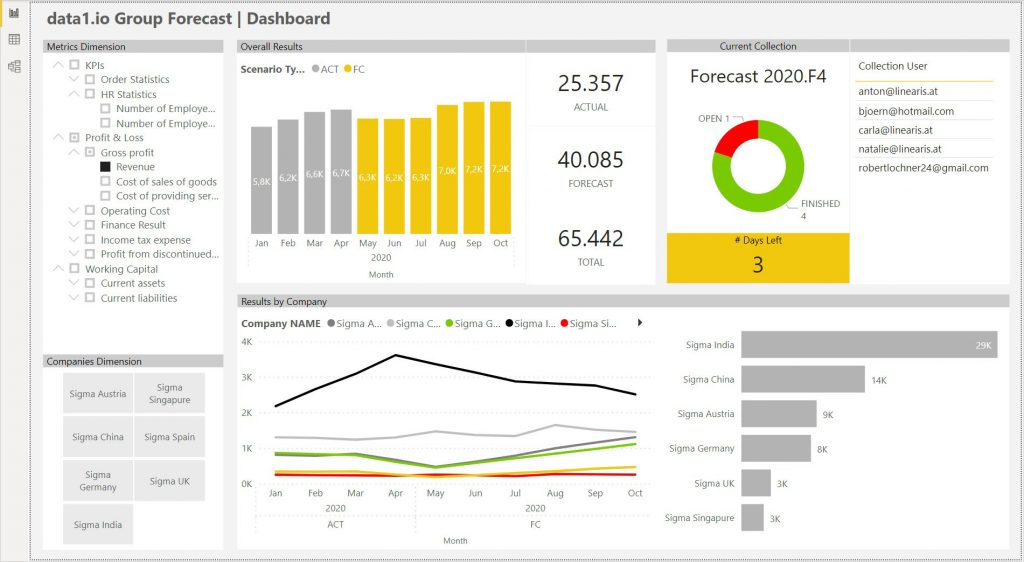
Beachten Sie bitte, daß die Visuals zur Current Collection (rechts oben) nicht mit den anderen Visuals interagieren, da es im Datamodel keine Beziehung gibt unnd auch nicht über die verwendeten Measures eine Beziehung hergestellt wurde.
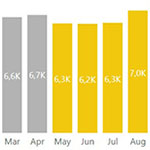
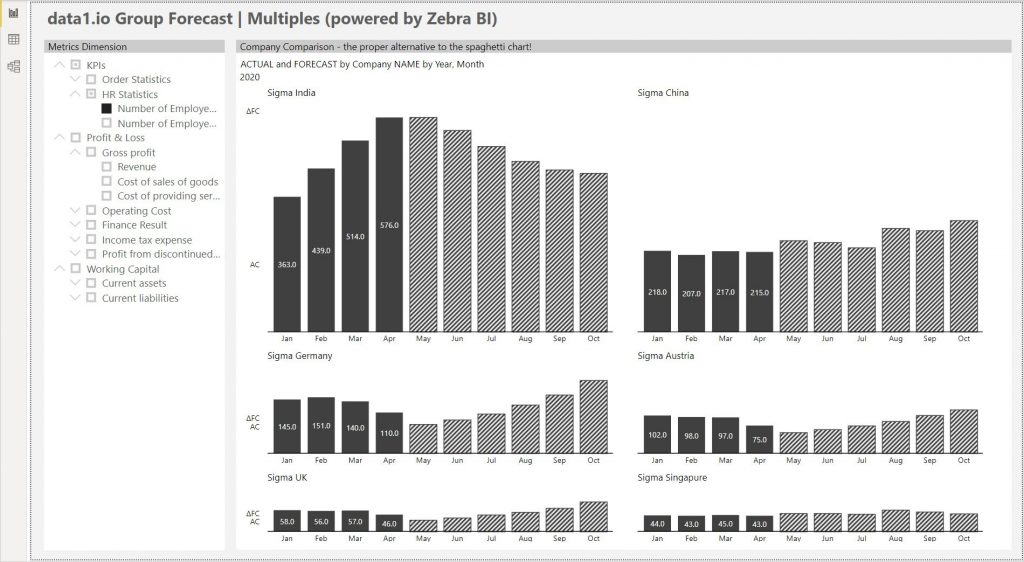
Das „Spaghetti Chart“ (Mitte unten) ist zwar weit verbreitet, viel Information lässt sich daraus aber nicht ablesen (insbesondere wenn noch mehr Gesellschaften auszuwerten sind). Hier empfehlen wir den gezielten Einsatz von Custom Visuals wie dem Zebra BI Power Charts Visual, da die Visualisierung als sogenanntes Multiple – das ist eine Gruppe gleichartiger Charts mit einheitlicher Achsenskalierung – enorm viel mehr Einblicke ermöglicht als im „Spaghetti“:
Schritt 4: Lösung für die Aggregationsthematik
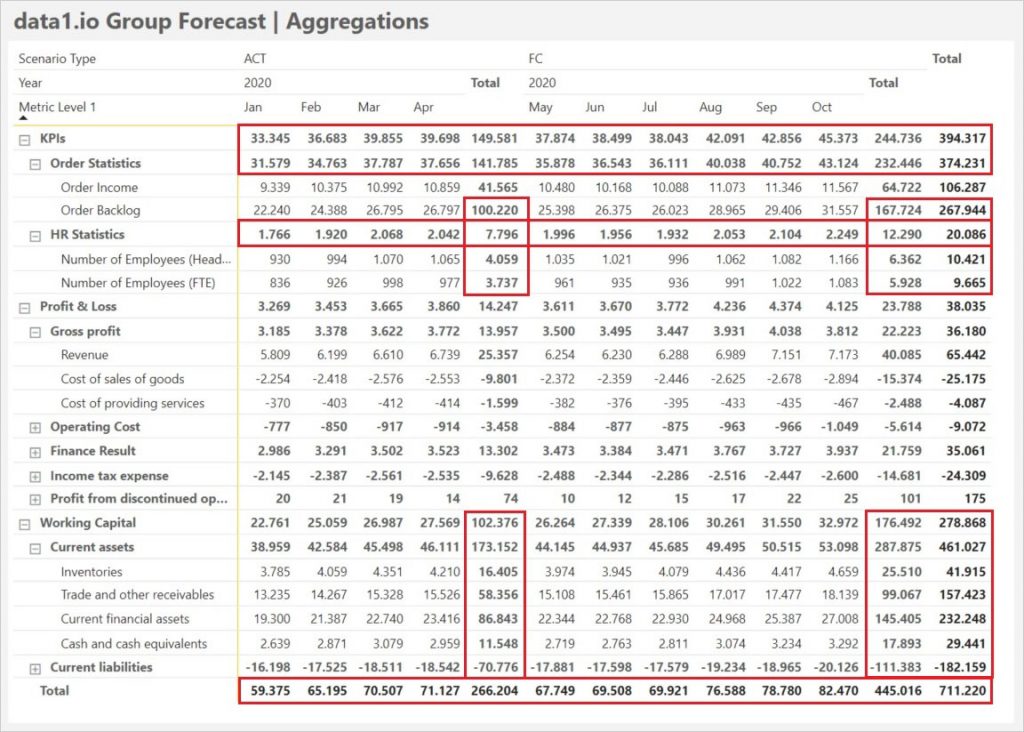
Solange im Metric Dimension Slicer nur 1 Kennzahl bzw. nur 1 Gruppe mit sinnvoller Aggregation ausgewählt wird und solange die Daten auf Monatsbasis ohne Gesamtsumme dargestellt werden, reicht das einfache Summen Measure zur Auswertung. Die Aggregationsthematik des „bunten Kennzahlengemisches“ wird aber sofort sichtbar, wenn ein Matrix Visual mit allen Zwischen- und Gesamtsummen erstellt wird:
- Es sind auch Bestandskennzahlen enthalten: hier dürfen nicht die Monatswerte summiert werden sondern es muß auf der übergeordneten Periode der Wert der letzten verfügbaren Periode angezeigt werden („semi-additives Measure“)
- Nicht alle Gruppensummen ergeben Sinn („Äpfel & Birnen“): es muß hier eine Ebenenlogik angewendet werden
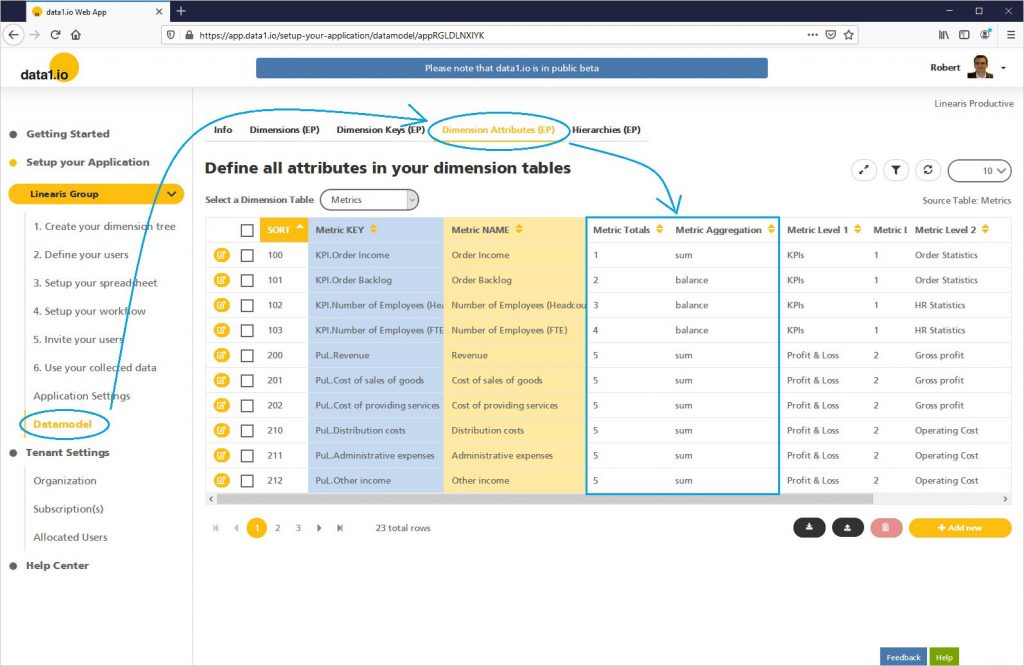
Um die dafür notwendigen Measures nicht hard-codieren zu müssen, errweitern wir die Stammdaten der Metrics Dimension im data1.io Datamodel um die folgenden beiden Felder:
- Metric Aggregation: hier werden die Codewörter „sum“ und „balance“ eingesetzt um darauf später im Measure die Bestandslogik aufbauen
- Metric Totals: hier werden mittels (beliebiger) Zifferen Aggregationsgruppen definiert -> alle Kennzahlen mit der gleichen Ziffer werden summiert, Kennzahlen mit unterschiedlicher Ziffer werden nicht summiert (daher wird auch keiine Gesamtsumme mehr über alle Kennzahlen gebildet werden)
Jetzt wird in Power BI das Measure angelegt, das mittels CALCULATE() und DATESBETWEEN()-Funktion für die semi-additive Aggregation der als „balance“ deklarierten Kennzahlen sorgt:
Step 2 Semi-Addtive =
VAR var_Aktueller_Stichtag =
CALCULATE(
MAX('Fact Table'[Date]);
ALL('Metrics')
)
RETURN
IF(
ISBLANK(var_Aktueller_Stichtag);
BLANK();
// Diese Bedingung ist notwendig, weil in den leeren Perioden ein Blank() für den aktuellen Stichtag ermittelt wird
// und das im DATESBETWEEN zu einer Gesamtsummenabfrage führen würde (also ein Wert ermittelt wird)
IF(
SELECTEDVALUE(Metrics[Metric Aggregation])="balance";
CALCULATE(
[Step 1 Sum];
DATESBETWEEN(
'Dim Date'[Date];var_Aktueller_Stichtag;var_Aktueller_Stichtag
)
);
SUM('Fact Table'[Measure])
)
)Der positive Effekt auf die Aggregation in der Datumsdimension ist hier im mittleren Matrix Visual zu sehen:
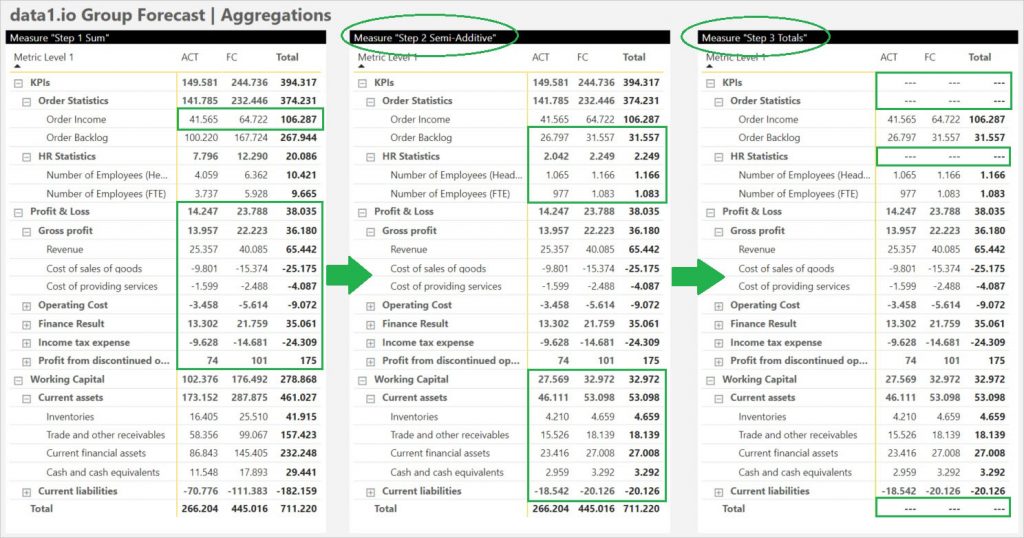
Das dritte und abschließende Measure sorgt für die Ebenenlogik: nur auf Ebenen, auf denen das Totals-Kennzeichen aus den Stammdaten eindeutig ist – die HASONEVALUE()-Funktion ist Syntax Sugar für ein „DISTINCTCOUNT()=1“ – wird das Step-2 Measure ausgeführt. Falls nicht, wird der Platzhaltertext „—“ angezeigt (in den Charts führt dieser Text zu einem leeren Chart und zu keiner Fehlermeldung):
Step 3 Totals =
IF(
AND(
NOT(HASONEVALUE(Metrics[Metric Totals]));
NOT(ISBLANK(SUM('Fact Table'[Measure])))
// die zweite Bedingung ist notwendig, damit nicht auch bspw. in leeren Perioden bzw. auf unbebuchten Elementen das "---" aufgespannt wird
);
"---";
[Step 2 Semi-Addtive]
)Das Measure wurde zur leichteren Nachvollziehbarkeit in 3 Steps aufgeteilt, in der produktiven Lösung reicht natürlich 1 einziges Measure mit der gesamten Logik. Zum Abschluß werden die 3 Reporting Measures ACTUAL, FORECAST und TOTAL auf das Step 3 Measure referenziert, damit die Aggregationslogik auch in diesen Measures wirkt.
Hier nochmals die eingebettet Anwendung zum Testen der Aggregations- und Ebenenlogik:
Ausblick
In dieser Anwendung noch ungelöst ist die Thematik der Auswahl des gewünschten Forecasts. Da in der Demoanwendung aktuell nur 4 IST-Monate und ein einziger Forecast (über 6 Monate) enthalten ist, können die Szenarien und Perioden einfach summiert werden. Ab dem zweiten Forecast („2020.F5“) braucht es aber einen Filter. Weiters sollte in diesem Kontext auch gleich eine automatische Ermittlung des höchsten verfügbaren Forecasts implementiert werden, der nur bei Bedarf durch den User übersteuert werden kann.
Großes Potential besteht beim Ausbau der Visualisierungen – hier sind Ideen herzlich willkommen. Die PBIX-Anwendung können Sie hier downloaden und uns Ihre Visualisierungsvorschläge per Mail zuschicken. Beachten Sie bitte, daß Sie in dieser Anwendung die Daten aus dem ODATA-Feed ohne Passwort nicht aktualisieren können und daher auch die Queries nicht bearbeiten können.