Das Datenmodell in Power BI (einschließlich der DAX Formelsprache) ist eine analytische Datenbank, die sehr vielfältige Modellierungsvarianten zulässt und auch unterstützt. Manche Datenmodelle sind sehr effizient („Standard-Modelle„), andere hingegen sind es nicht („Anti-Modelle„).
Im folgenden Teil 1 zeigen wir den häufigen Praxisfall, in dem eine variable Anzahl von Kennzahlen in den Spalten der Quelltabelle abgebildet ist. Die 1:1 Übernahme ins Power BI Datenmodell ist naheliegend, aber bei näherer Betrachtung sehr ineffizient und damit eindeutig ein Anti-Modell. Die Anwendung der recht simplen Unpivot-Funktion in der Power Query Komponente von Power BI ändert das Datenmodell grundlegend und macht die Handhabung effizient – und damit zum Standard-Modell. Aus Visualisierungssicht stellt sich auch die bereits in früheren Blogbeiträgen (hier und hier) diskutierte Column vs. Measure Thematik.
Im folgenden Teil 2 wird gezeigt, wie dieses Datenmodell auf mehrere Faktentabellen erweitert wird und dabei die Abbildung als sogenanntes Multi-Fakten Schema wiederum naheliegend aber noch nicht optimal ist. Im abschließenden Teil 3 zeigen wir, wie die Faktentabellen zu einer einzigen integriert werden können und dabei ein simples Star Schema mit zahlreichen Vorteilen erreicht wird, in dem aber auch einige Herausforderungen zu lösen sind.
1. Ausgangsdaten
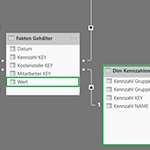
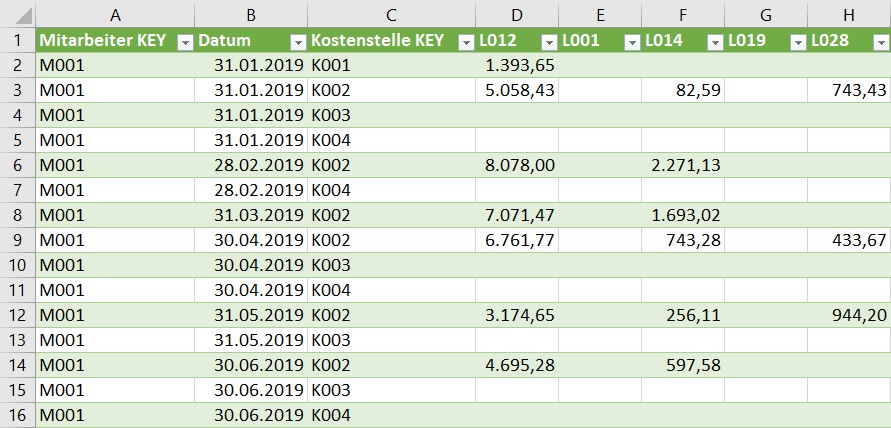
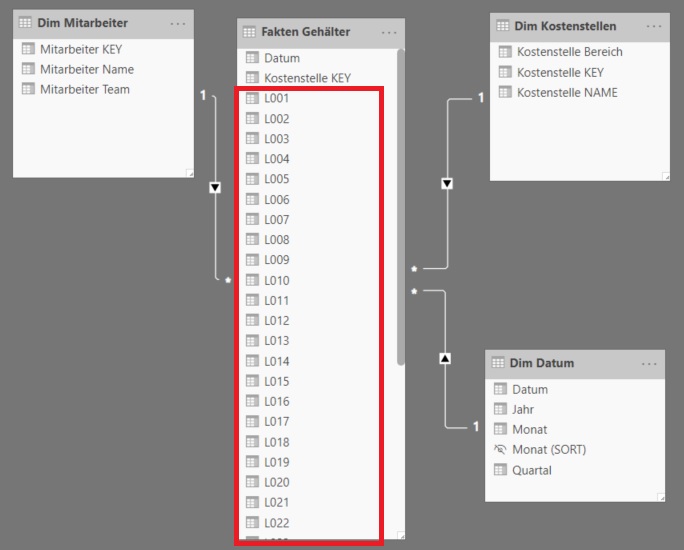
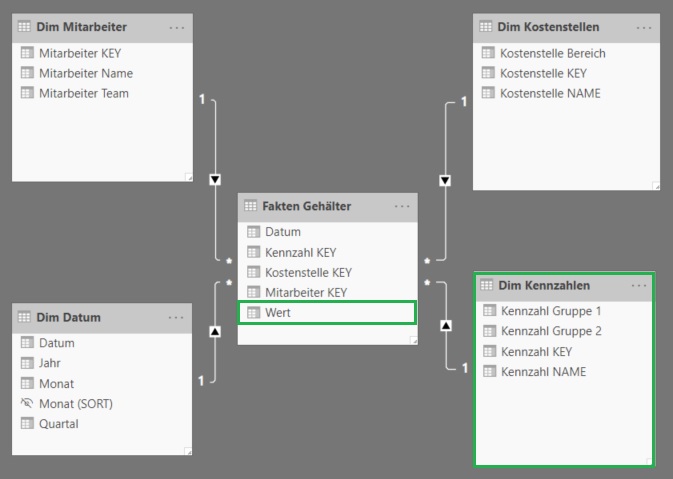
Es soll eine Analyse der Gehaltsdaten eines Unternehmens im Rahmen einer HR Dashboard Anwendung aufgebaut werden. Die Tabelle mit den Gehaltsdaten („Faktentabelle„) ist so aufgebaut, daß die Lohnarten (L001, L002, usw.) als Wertspalten abgebildet sind und auch im Zeitablauf variieren werden, d.h. neue Lohnarten werden hinzukommen, bestehende werden ggfs. später nicht mehr verwendet werden:
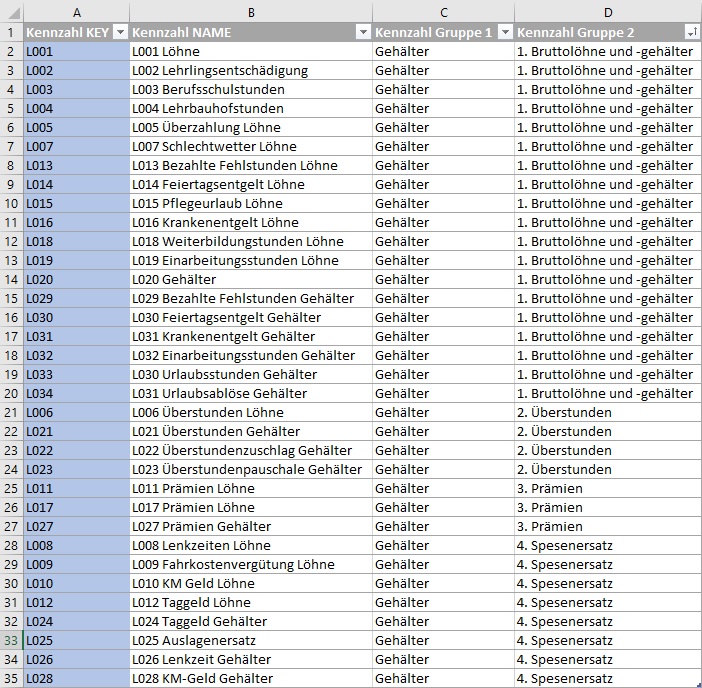
Zu den Lohnarten (= Spaltenüberschriften) ist folgende Definitionstabelle verfügbar, die zeigt, welche Lohnart welche Bezeichnung trägt und in welche übergeordneten Kennzahlen eine Lohnart aggregiert:
2. Lösungsansatz „Kennzahlen in den Spalten“ (Anti-Modell)
Wird die eingangs gezeigte Faktentabelle 1:1 in das Datenmodell von Power BI geladen und dort mit den Dimensionstabellen verknüpft, so erhalten wir ein grundsätzlich erstrebenswertes Star Schema. Jedoch ist die Spaltenstruktur der Faktentabelle – wie in weiterer Folge gezeigt – ineffizient:
Die Aggregation zu Kennzahlen kann in diesem Datenmodell nur über ein Set an einzeln (und manuell) zu definierenden Measures erreicht werden, die beim Hinzukommen neuer Lohnarten (= Wertspalten) manuell gewartet werden müssen:
1. Bruttogehälter =
SUM('Fakten Gehälter'[L001]) + SUM('Fakten Gehälter'[L002]) + SUM('Fakten Gehälter'[L003]) + SUM('Fakten Gehälter'[L004]) + SUM('Fakten Gehälter'[L005]) + SUM('Fakten Gehälter'[L007]) + SUM('Fakten Gehälter'[L013]) + SUM('Fakten Gehälter'[L014]) + SUM('Fakten Gehälter'[L015]) + SUM('Fakten Gehälter'[L016]) + SUM('Fakten Gehälter'[L018]) + SUM('Fakten Gehälter'[L019]) + SUM('Fakten Gehälter'[L020]) + SUM('Fakten Gehälter'[L029]) + SUM('Fakten Gehälter'[L030]) + SUM('Fakten Gehälter'[L031]) + SUM('Fakten Gehälter'[L032]) + SUM('Fakten Gehälter'[L033]) + SUM('Fakten Gehälter'[L034])2. Überstunden =
SUM('Fakten Gehälter'[L006]) + SUM('Fakten Gehälter'[L021]) + SUM('Fakten Gehälter'[L022]) + SUM('Fakten Gehälter'[L023])3. Prämien =
SUM('Fakten Gehälter'[L011]) + SUM('Fakten Gehälter'[L017]) + SUM('Fakten Gehälter'[L027])4. Spesenersatz =
SUM('Fakten Gehälter'[L008]) + SUM('Fakten Gehälter'[L009]) + SUM('Fakten Gehälter'[L010]) + SUM('Fakten Gehälter'[L012]) + SUM('Fakten Gehälter'[L024]) + SUM('Fakten Gehälter'[L025]) + SUM('Fakten Gehälter'[L026]) + SUM('Fakten Gehälter'[L028])Gehälter =
[1. Bruttogehälter] + [2. Überstunden] + [3. Prämien] + [4. Spesenersatz]Zur Visualisierung müssen die einzelnen Measures (wiederum manuell) zum gewünschten Visual hinzufügt werden:
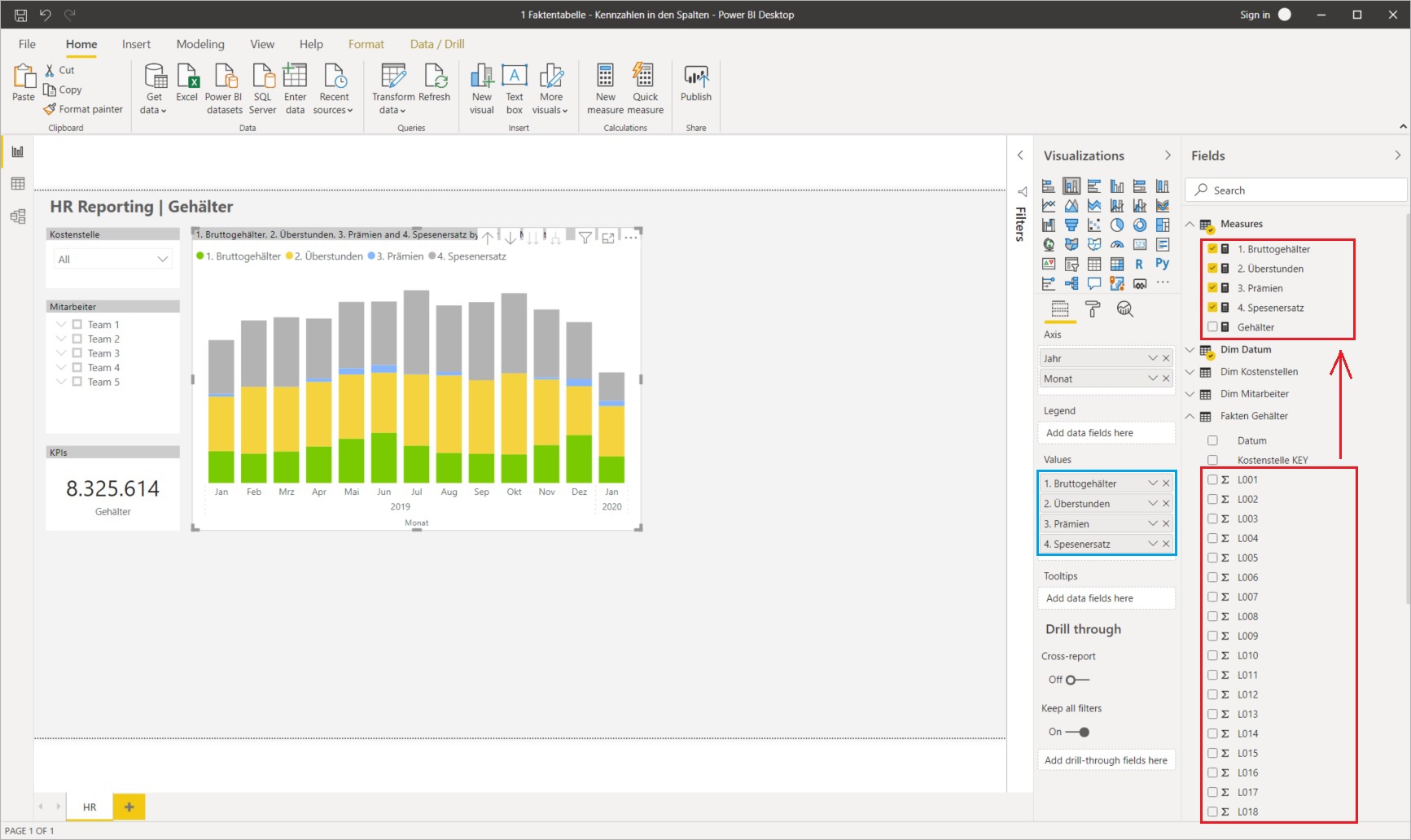
Neben der Erstellung und Wartung der (vielleicht auch viel zahlreicheren) Measures ist auch die Wartung der Visualisierungen ineffizient: sobald neue Kennzahlen (= Measures) hinzukommen, müssen diese den bestehenden Visuals manuell hinzugefügt werden. Die Auswertung bis auf Lohnartenebene ist in vielen Fällen zu aufwendig, da jede einzelne Wertspalte (= implizite Measures) manuell einem (bspw. Table) Visual hinzugefügt werden müssen. Hierarchische Darstellungen der Kennzahlen sind gar nicht möglich. In der Column vs. Measure Thematik (siehe hier und hier) befinden wir uns mit diesem Datenmodell also auf der „Measures Seite“ und müssen die damit verbundenen Einschränkungen in Kauf nehmen.
3. Lösungsansatz „Kennzahlendimension“ (Standard-Modell)
Die Einschränkungen des „Anti-Modells“ können sehr leicht mit der sogenannten Unpivot Funktion der Power Query Komponente aufgelöst werden und ein für die Visualisierung mit Power BI optimales Datenmodell erzeugt werden. Konkret wird in diesem Fall die Funktion Unpivot Other Columns angewendet: dabei werden die Key-Spalten markiert und dann der genannte Befehl angewendet. Diese Vorgehensweise hat den Vorteil, daß bei zukünftig neu hinzukommenden Lohnarten (= Wertspalten) diese ebenfalls von der Unpivot Funktion erfasst werden:
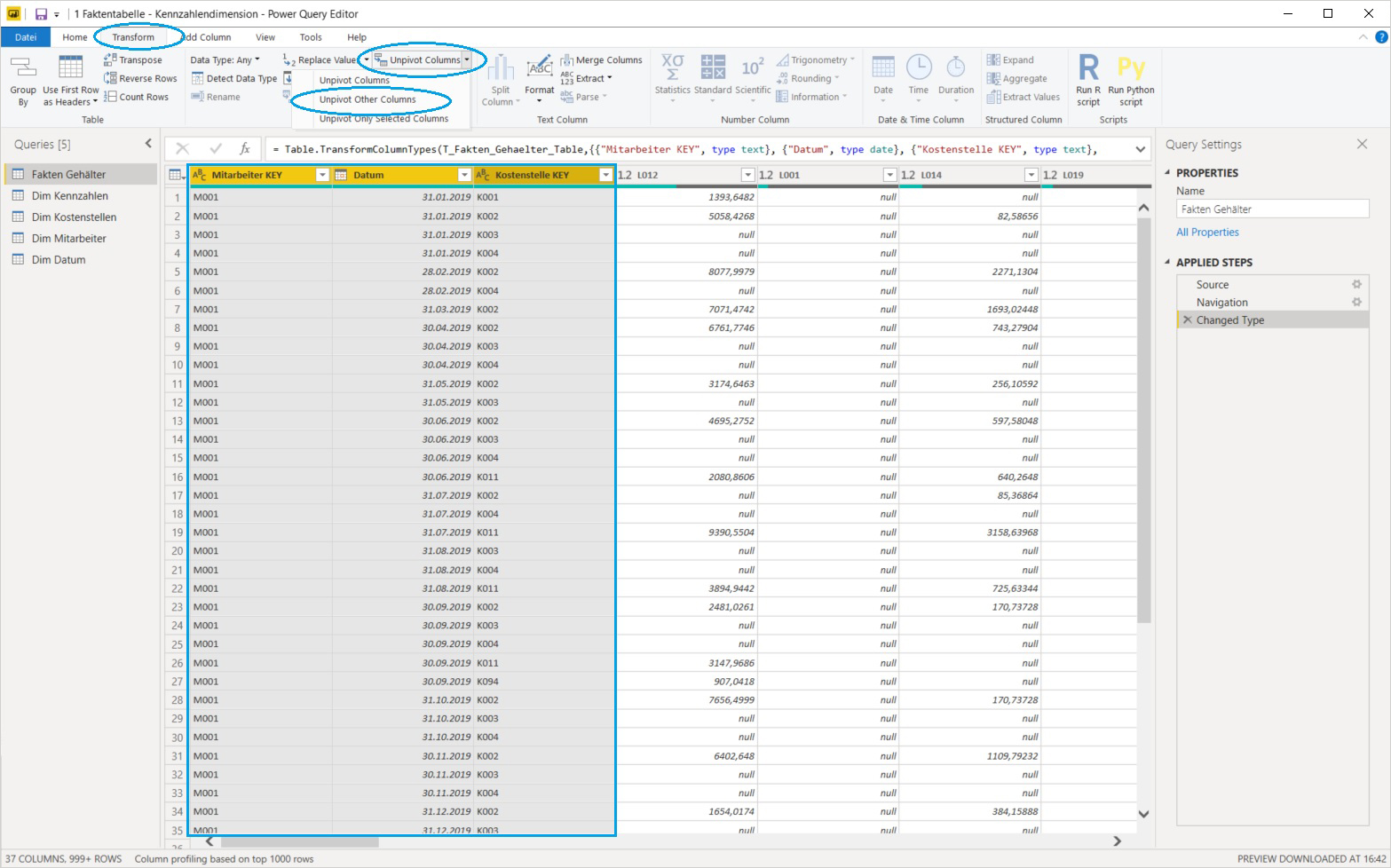
Die Wertspalten werden durch diese Funktion in Datensätze transponiert, aus den zahlreichen Wertspalten wird eine sogenannte Attributspalte (= mit den ursprünglichen Spaltennamen als Einträge) sowie eine einzige Wertspalte. Erstere wird in Kennzahl KEY umbenannt, zweitere in Wert:
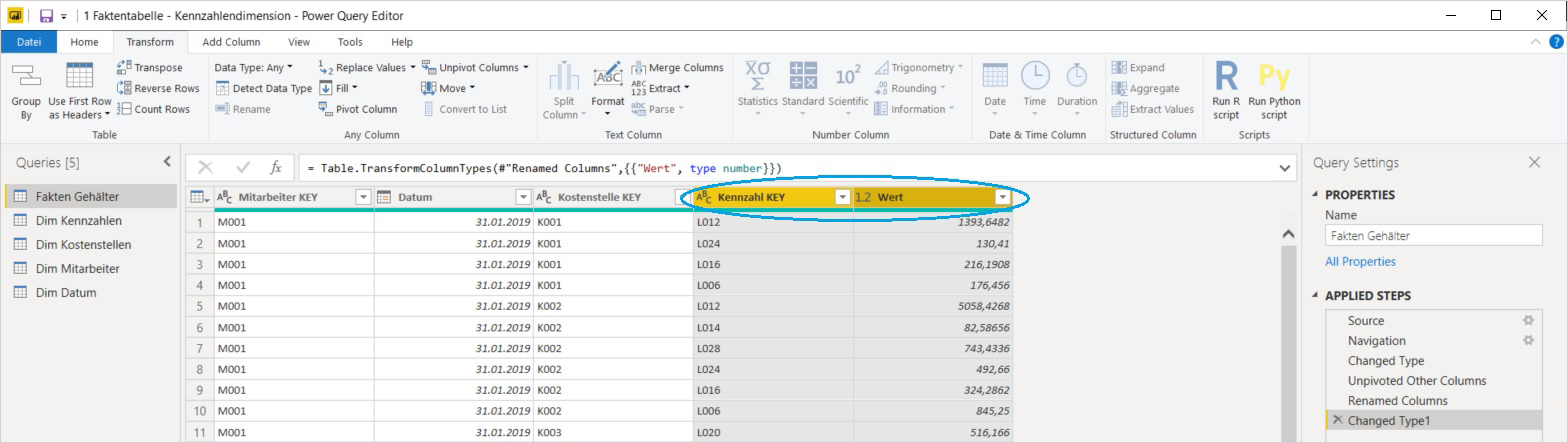
Das resultierende Datenmodell ist wiederum ein Star Schema, jedoch mit einer sehr effizienten (und im Zeitablauf absolut robusten) Spaltenstruktur in der Faktentabelle. Die eingangs gezeigte Definitionstabelle für die Lohnarten wird als Kennzahlendimension in das Datenmodell geladen und dient zur Differenzierung der Einträge in der Spalte Wert nach Lohnarten und zur Aggregation auf übergeordnete Kennzahlen:
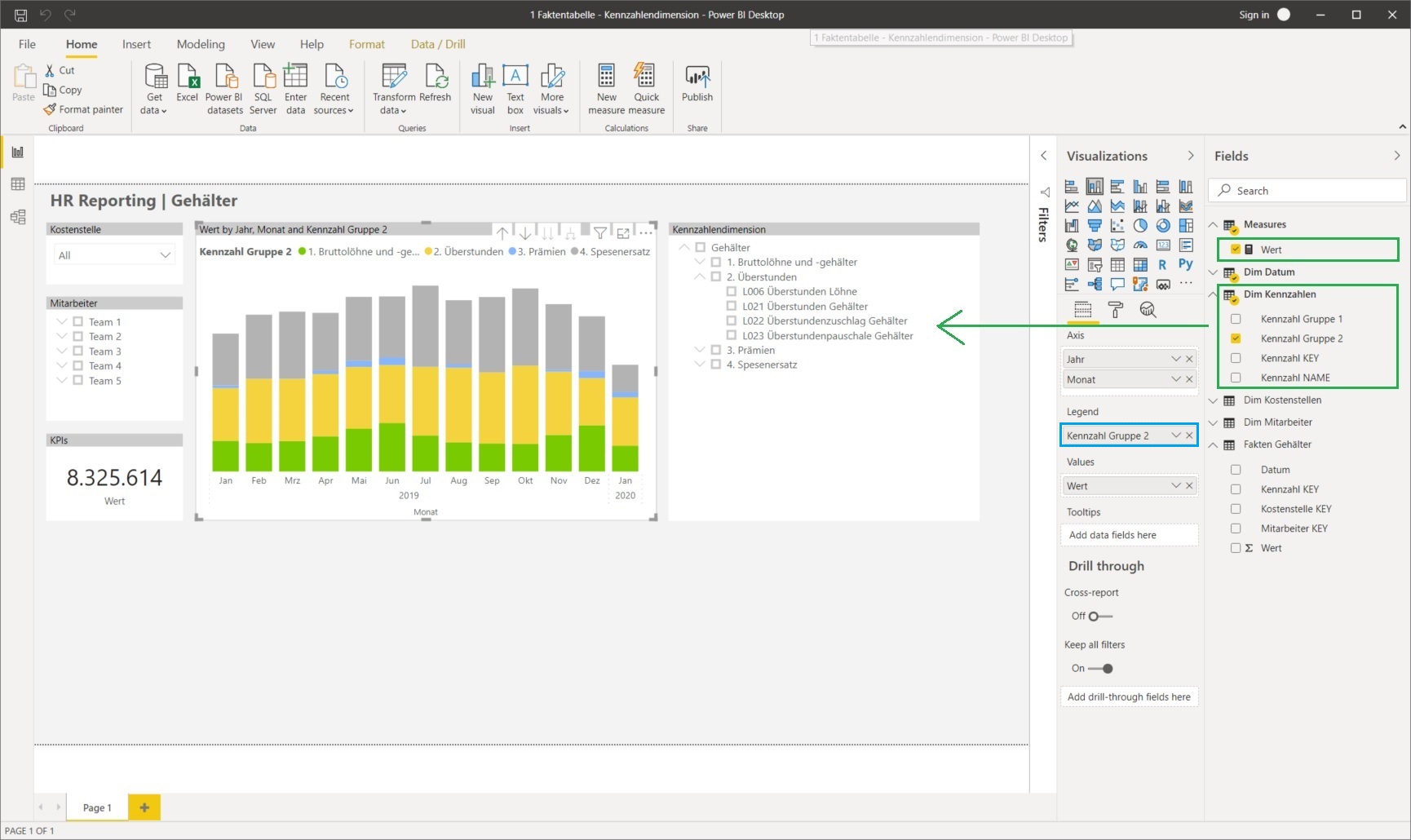
Wir benötigen jetzt nur 1 einziges Measure zu definieren, das sehr simpel und vor allem wartungsfrei auch beim Hinzukommen neuer Lohnarten ist:
Wert =
SUM('Fakten Gehälter'[Wert])Die Visualisierung ist jetzt ebenfalls effizient und wartungsfrei: es braucht nur 1 Measure sowie das Feld Kennzahl Gruppe 2 als Legende hinzugefügt werden. Das Säulendiagramm erzeugt daher automatisch so viele Kategorien, wie es verschiedene Einträge in diesem Feld gibt (es benötigt also keine manuelle Wartung, um neue Kennzahlen hinzuzufügen). Weiters ist es jetzt sehr einfach, die Auswertung bis auf die einzelne Lohnart selektieren zu können, entweder als Slicer …
… oder als hierarchische Tabelle in einem Matrix Visual:

4. Evaluierung
Die 1:1 Übernahme einer Faktentabelle mit dem Aufbau „Kennzahlen in den Spalten“ in das Datenmodell kann in folgenden Fällen sinnvoll sein:
- geringe Anzahl von Wertspalten (= Kennzahlen)
- keine Variabilität (d.h. es kommen sicher keine neuen Wertspalten später hinzu)
- notwendige Berechnungen zwischen den Wertfeldern am einzelnen Datensatz (die durch die Transformation deutlich schwieriger umzusetzen wären)
In allen anderen Fällen ist die Transformation zu einer Kennzahlendimension effizienter und daher empfehlenswert:
- Effiziente Auswertung vom Aggregat bis zur einzelnen Kennzahl (hier: Lohnart)
-> Slicer zur Selektion anstatt Drag & Drop von einzelnen Measures - Hierarchische Darstellung der Kennzahlenstrukturen
-> Abbildung eines vollständigen Kennzahlenkatalogs ist möglich - Einfache Measure Formeln und deutlich geringere Anzahl von Measures
-> bei der Definition von zusätzlichen Year-to-Date, Year-over-Year, usw. Measures multipliziert sich die Anzahl der Measures mit jeder Berechnungsart - Visualisierungen mit Columns sind leistungsfähiger als mit einem Set von Measures
-> es stehen alle Visualisierungsvarianten in Power BI zur Verfügung (siehe hier und hier) - Wartungsfreie Measures und Visualisierungen
-> das Datenmodell ist wachstumsfähig
Wichtig ist auch die Betrachtung der Datenmengen und Modellgröße:
- Modell 1 „Kennzahlen in den Spalten“: 2.681 Datensätze in der Faktentabelle
- Modell 2 „Kennzahlendimension“: 6.550 Datensätze in der Faktentabelle (offenbar gab es viele leere Zellen in der Matrix, da sich die Anzahl der Datensätze nicht ver-30-facht sondern nur etwa ver-3-facht hat)
Interessanterweise / zum Glück ist im Power BI Datenmodell nicht die Anzahl der Datensätze ausschlaggebend sondern die Anzahl der Spalten und die Granularität der Einträge in den einzelnen Spalten. Hier die Auswertung mit dem Tool Vertipaq Analyzer, das in das Tool DAX Studio (als Preview) integriert ist und sehr einfach zur technischen Analyse der Datenmodelle genutzt werden kann:


Der Speicherbedarf der transponierten Faktentabelle ist geringer als der Speicherbedarf der Originaltabelle! Das liegt am Komprimierungsmechanismus der Vertipaq Engine im Power BI Datenmodell, dieser wirkt – salopp ausgedrückt – bei „schmalen und langen“ Tabellen stärker als bei „kurzen und breiten“ Tabellen. Dazu kommt noch die Granularität der Einträge, diese verändert sich durch das Transponieren aber nur unwesentlich (es kommt zwar die neue Attributspalte hinzu, dafür steigt die Wahrscheinlichkeit von gleichen Einträgen in der transponierten Wertspalte).
Natürlich benötigt auch die Kennzahlendimension Speicherplatz, bei steigenden Datenmengen ist dieser aber verschwindend gering gegenüber dem Komprimierungseffekt in der Faktentabelle. Warum der Speicherbedarf der Datumsdimension im transponierten Modell gestiegen ist, ist mir derzeit noch unklar, kann aber nach meinem Verständnis nichts mit dem geänderten Datenmodell zu tun haben (sondern eher mit einem unbeabsichtigt veränderten Setting).
Den Test zur Measure Performance in den beiden Modellierungsvarianten haben wir nicht gemacht, aber Rob Collie hat einen gemacht:
https://powerpivotpro.com/2011/08/less-columns-more-rows-more-speed
Im Teil 2 dieser Blogserie wird gezeigt, wie dieses Datenmodell auf mehrere Faktentabellen erweitert wird und dabei die Abbildung als sogenanntes Multi-Fakten Schema wiederum naheliegend aber noch nicht optimal ist. Im Teil 3 zeigen wir dann, wie die Faktentabellen zu einer einzigen integriert werden können und dabei ein simples Star Schema mit zahlreichen Vorteilen erreicht wird, in dem aber auch einige Herausforderungen zu lösen sind.