Das Datenmodell in Power BI (einschließlich der DAX Formelsprache) ist eine analytische Datenbank, die sehr vielfältige Modellierungsvarianten zulässt und auch unterstützt. Manche Datenmodelle sind sehr effizient („Standard-Modelle„), andere hingegen sind es nicht („Anti-Modelle„).
In Teil 1 haben wir gezeigt, daß die 1:1 Abbildung einer Faktentabelle mit einer variablen Anzahl von Kennzahlen in den Spalten absolut ineffizient ist („Anti Modell“) und wie das Datenmodell mit der Unpivot-Funktion optimiert wird und damit sowohl die Visualisierungen als auch das Datenmodell wartungsfrei werden.
Im folgenden Teil 2 zeigen wir, wie dieses Datenmodell auf mehrere Faktentabellen erweitert wird und dabei die Abbildung als sogenanntes Multi-Fakten Schema wiederum naheliegend und wieder nicht optimal ist. Im abschließenden Teil 3 zeigen wir, wie die Faktentabellen im vorliegenden – und nach unserer Erfahrung sehr häufigen – Fall zu einer einzigen integriert werden können und dabei ein simples Star Schema mit zahlreichen Vorteilen aber auch mit einigen zu lösenden Besonderheiten erreicht wird.
1. Ausgangssituation
Zusätzlich zur Quelltabelle für die Gehälter (die bereits aus Teil 1 bekannt ist) …
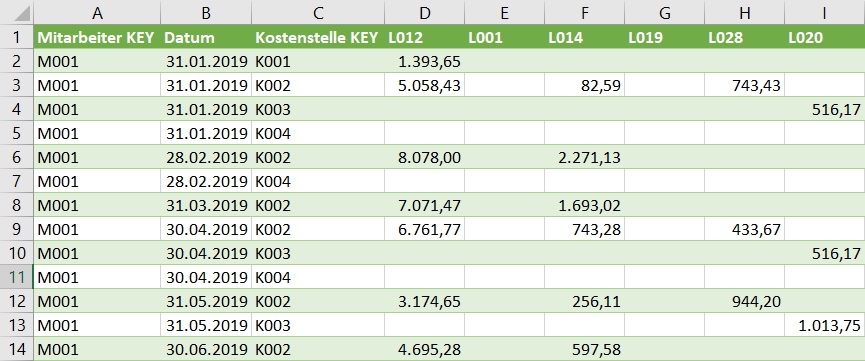
… liegt auch eine Faktentabelle mit den Arbeitszeiten (in Stunden) …
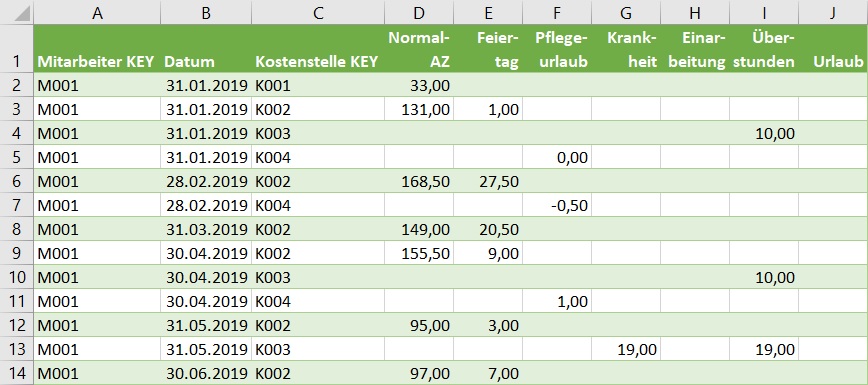
… und eine weitere Faktentabelle mit dem Headcout (in Personen) vor:

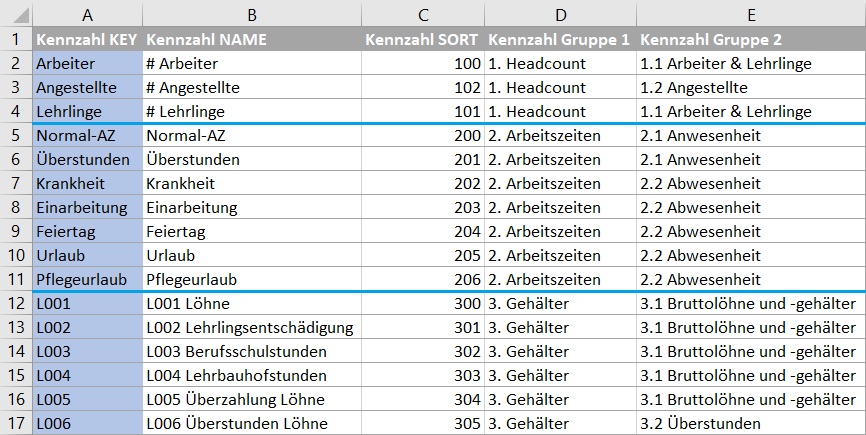
Dazu liegt uns die Definitionstabelle für die Kennzahlen vor, die jetzt alle 3 Datenbestände umfasst und eine zusätzliche Sortierspalte enthält, mit der der erweiterte Kennzahlenkatalog in die gewünschte Reihenfolge gebracht wird:
2. Abbildung im Datenmodell als Multi-Fakten Schema
In der Power Query Komponente von Power BI werden die 3 Faktentabellen mit der Unpivot Funktion – wie bereits in Teil 1 detailliert beschrieben – so transformiert, daß die variable Anzahl von Wertspalten in eine Kennzahl Key und eine Wert Spalte transponiert wird:

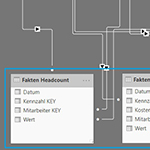
Die 3 Faktentabellen werden in das Datenmodell geladen und damit ein Multi-Fakten Schema mit gemeinsamen Dimensionen realisiert. Jede Faktentabelle wird über die Key-Felder mit der korrespondierenden Dimensionstabelle verknüpft, sodaß sich bereits bei der relativ geringen Anzahl von Tabellen ein zumindest optisch unübersichtliches Beziehungsgeflecht ergibt:
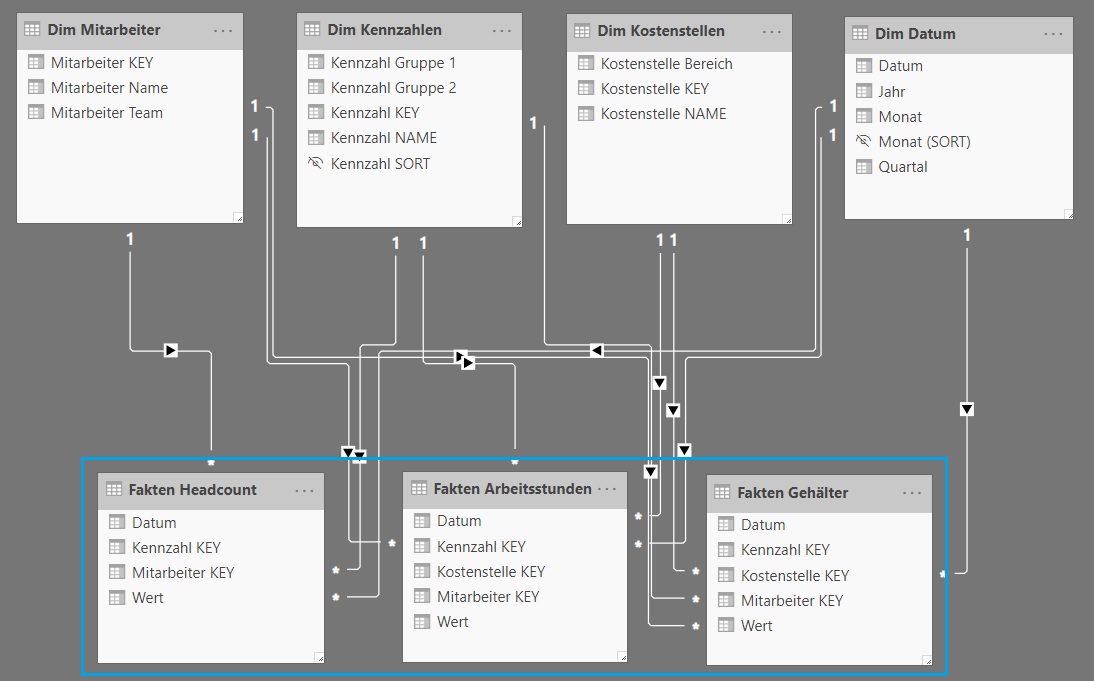
Insgesamt sind es 11 Beziehungen zwischen den 3 Fakten- und den 4 Dimensionstabellen. Die Tabelle Fakten Headcount hat übrigens keine Kostenstelleninformation, daher sind es nicht 12 sondern 11 Beziehungen:
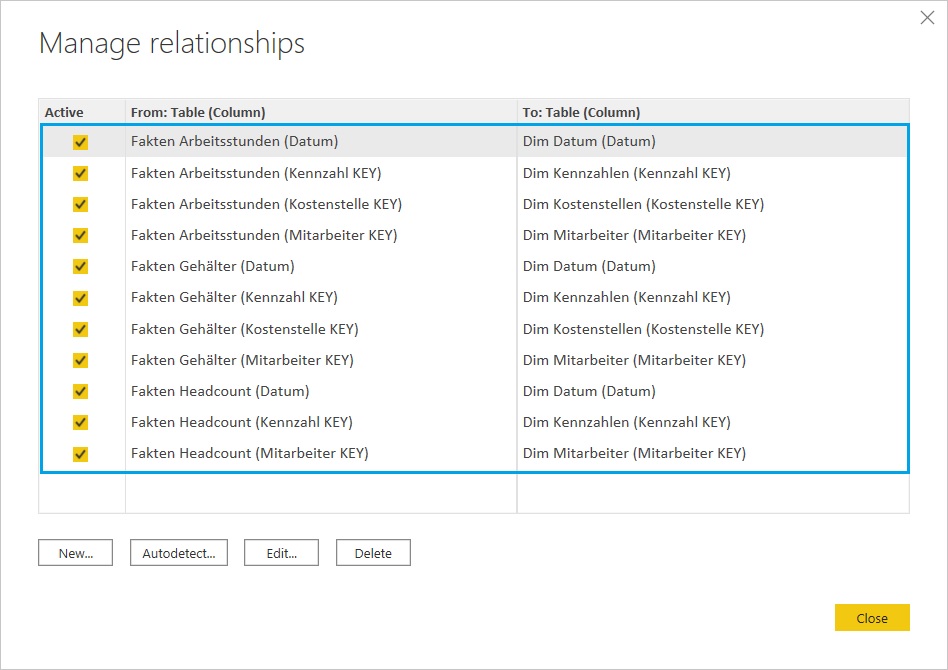
Querverweis: wir nennen dieses Datenmodell in unserer Systematik „Multi-Fakten Schema Typ 2„, da die Verbindung zwischen den Faktentabellen – anders als beim Typ 1 – nicht über ein kausales Verbindungsfeld (bspw. Order ID) sondern über gemeinsame Auswertungsdimensionen erfolgt. Diese Unterscheidung ist deshalb wichtig, weil die folgenden Ausführungen und auch die diskutierten Vor-/Nachteile sich lediglich auf Typ 2 Modelle beziehen.
3. Measures und Visualisierungen im Multi-Fakten Schema
Zur Auswertung des Datenmodells wird pro Faktentabelle je 1 simples Summen-Measure für die Kennzahlen Gehälter und Arbeitszeit erstellt:
Gehälter (in EUR) =
SUM('Fakten Gehälter'[Wert])Arbeitszeit (in h) =
SUM('Fakten Arbeitsstunden'[Wert])Lediglich das Measure für die Kennzahl Headcount ist etwas aufwendiger …
Headcount (in P) =
VAR var_Aktueller_Stichtag =
CALCULATE(
MAX('Fakten Headcount'[Datum]);
ALL('Dim Kennzahlen');
ALL('Dim Kostenstellen');
ALL('Dim Mitarbeiter')
)
RETURN
IF(
ISBLANK(var_Aktueller_Stichtag);
BLANK();
CALCULATE(
SUM('Fakten Headcount'[Wert]);
DATESBETWEEN(
'Dim Datum'[Datum];
var_Aktueller_Stichtag;
var_Aktueller_Stichtag
)
)
)… da hier es sich hier um eine semi-additive Kennzahl handelt und die Werte auf der Zeitachse nicht summiert werden dürfen sondern der jeweils letzte Stand einer Periode gezeigt werden muß („Bestandslogik“):

Die Auswertung der 3 Measures kann in Verbindung mit der Kennzahlendimension hierarchisch erfolgen und dabei bereits eine hohe Informationsdichte erreicht werden:

Das fertige Dashboard mit allen 3 Teildatenbeständen kann beispielsweise folgendermaßen aussehen, die Filterung der Measures im Report erfolgt dabei über die gemeinsamen Dimensionen Datum, Kostenstellen und Mitarbeiter:

Evaluierung
Die Abbildung der 3 Faktentabellen als Multi-Fakten Schema ist im vorliegenden Fall (noch) kein (eindeutiges) Anti-Modell, es birgt aber bereits Risken:
1. Die Wachstumsfähigkeit des Modells ist eingeschränkt
Sobald weitere Faktentabellen hinzukommen, muß das Datenmodell bearbeitet werden und neue Beziehungen und neue Measures erstellt werden. Darüber hinaus müssen ggfs. auch bestehende Reports überarbeitet werden.
2. Die steigende Anzahl der Beziehungen steigert die Komplexität der Anwendung für den Power User
Beim Erstellen von DAX-Statements besteht das Risiko, daß Filterbeziehungen nicht richtig eingeschätzt werden und daß das Berechnungsergebnis erst mal „unerklärlich“ ist. Weiters führt die Verwendung von bidirektionalen Beziehungen rasch zu „Beziehungsstopps“ (d.h. eine zusätzliche Beziehung an einer bestimmten Stelle kann nicht mehr angelegt werden) oder zur „Model Ambiguity“ (d.h. die Auflösung eines Filterpfades ist für den User idR nicht mehr nachvollziehbar). Im Multi-Fakten Schema gibt es daher aufgrund der unübersichtlichen Beziehungen eine Komplexitätsgrenze, die bei wachsenden Anwendungen früher oder später überschritten wird.
3. Fehlende Beziehungen zu Teildatenbeständen führen leicht zu Fehlassoziationen bei den Berichtsnutzern
Hier am Beispiel der Kostenstellendimension: diese steht nicht mit der Faktentabelle Headcount in Verbindung, wer nicht genau hinsieht, bemerkt möglicherweise nicht, daß die Selektion einer Kostenstelle die Auswertung des Headcounts gar nicht gefiltert hat:
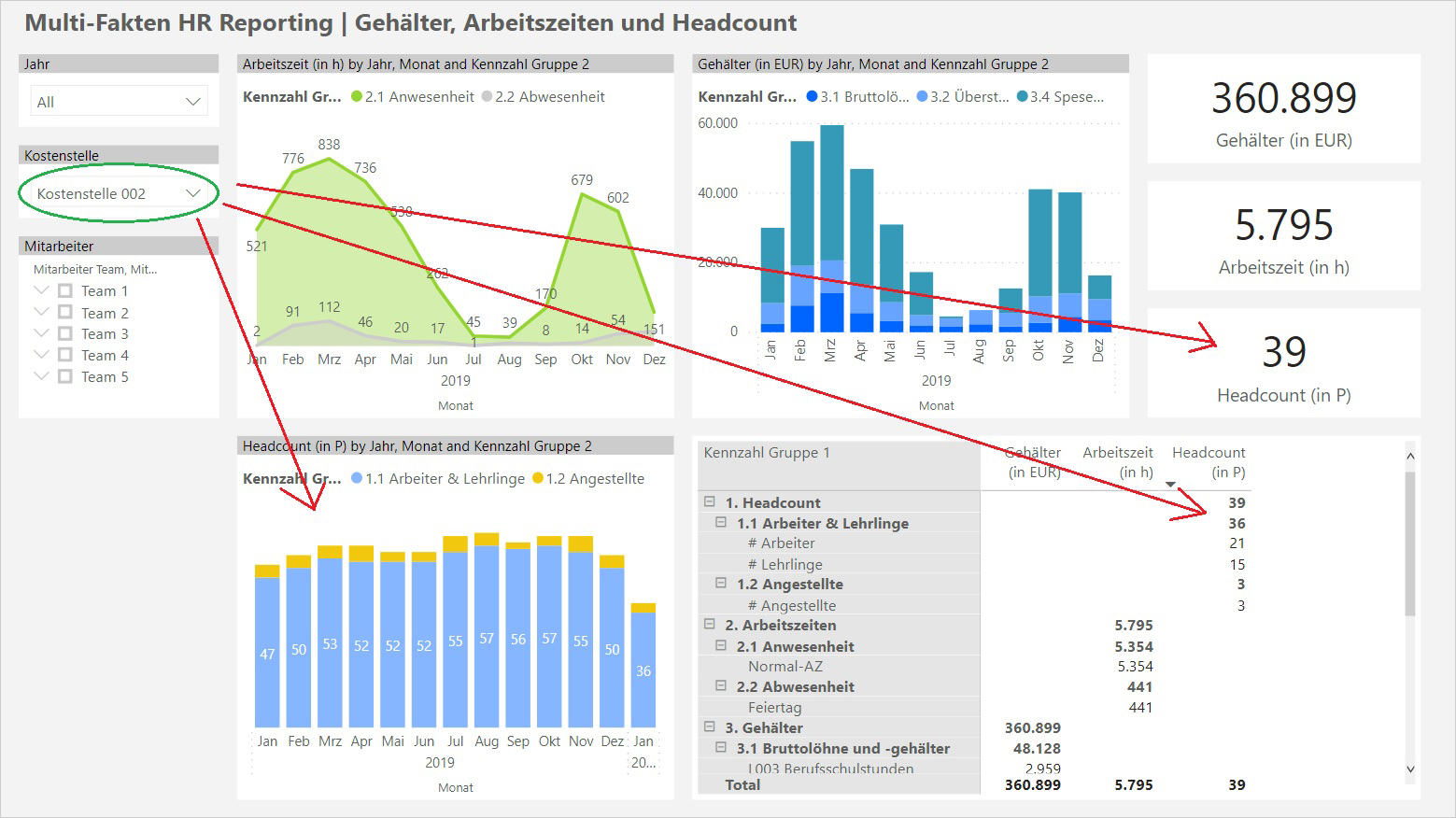
Gibt es in einem Multi-Fakten Schema ausschließlich gemeinsame Dimensionen, die mit allen Faktentabellen verbunden sind, tritt dieses Problem nicht auf. Sobald es aber proprietäre Dimensionen oder proprietäre Faktenattribute in einzelnen Faktentabellen gibt, steigt das Risiko solcher „Scheinfilterungen“. Es dürfen in diesem Fall keine Report Pages erstellt werden, in dem eine Scheinfilterung eintreten könnte (auch nicht bei Anwendung eines Crossfilters).
4. Die Ursache der Blank Row in den Dimensionstabellen ist schwerer festzustellen
Die Blank Row ist ein Mechanismus im Datenmodell von Power BI zur Abbildung der nicht definierten Keys in einer Beziehung. Im Multi-Fakten Schema muß zusätzlich festgestellt werden, aus welcher konkreten Beziehung zu einer Faktentabelle die undefinierten Keys stammen.
Es gilt der Grundsatz: das Multi-Fakten Schema gehört zu den anspruchsvollen Datenmodellen in Power BI – auch wenn es insbesondere anfangs häufig nicht besonders anspruchsvoll aussieht. Es sollte daher nur angewendet werden, wenn es keine brauchbaren Alternativen gibt.
Im abschließenden Teil 3 zeigen wir deshalb, wie die Faktentabellen im vorliegenden – und nach unserer Erfahrung sehr häufigen – Fall zu einer einzigen integriert werden können und dabei ein simples Star Schema mit zahlreichen Vorteilen aber auch mit einigen zu lösenden Besonderheiten erreicht wird.