Das Datenmodell in Power BI (einschließlich der DAX Formelsprache) ist eine analytische Datenbank, die sehr vielfältige Modellierungsvarianten zulässt und auch unterstützt. Manche Datenmodelle sind sehr effizient („Standard-Modelle„), andere hingegen sind es nicht („Anti-Modelle„).
In Teil 1 dieser Blogserie haben wir gezeigt, daß die 1:1 Abbildung einer Faktentabelle mit einer variablen Anzahl von Kennzahlen in den Spalten absolut ineffizient ist („Anti Modell“) und wie das Datenmodell mit der Unpivot-Funktion optimiert wird und damit sowohl die Visualisierungen als auch das Datenmodell wartungsfrei werden. In Teil 2 haben wir dann gezeigt, wie dieses Datenmodell auf mehrere Faktentabellen erweitert werden kann und dabei die Abbildung als sogenanntes Multi-Fakten Schema naheliegend aber noch nicht optimal ist.
Im abschließenden Teil 3 zeigen wir, wie mehrere Faktentabellen unter bestimmten – und nach unserer Erfahrung recht häufig vorkommenden – Voraussetzungen zu einer einzigen Faktentabelle integriert werden können und dabei ein simples Star Schema mit zahlreichen Vorteilen erreicht wird. Durch diese Zusammenführung heterogener Kennzahlen sind aber auch einige Herausforderungen zu lösen.
1. Ausgangssituation
Unser Ausgangspunkt ist das Multi-Fakten Schema aus Teil 2 dieser Blogserie, dabei sind 3 Faktentabellen mit 4 Dimensionstabellen über insgesamt 11 Beziehungen verbunden (es sind 11 und nicht 12 weil eine Faktentabelle keine Kostenstellen-Information enthält):

2. Integration zum „Star Schema“
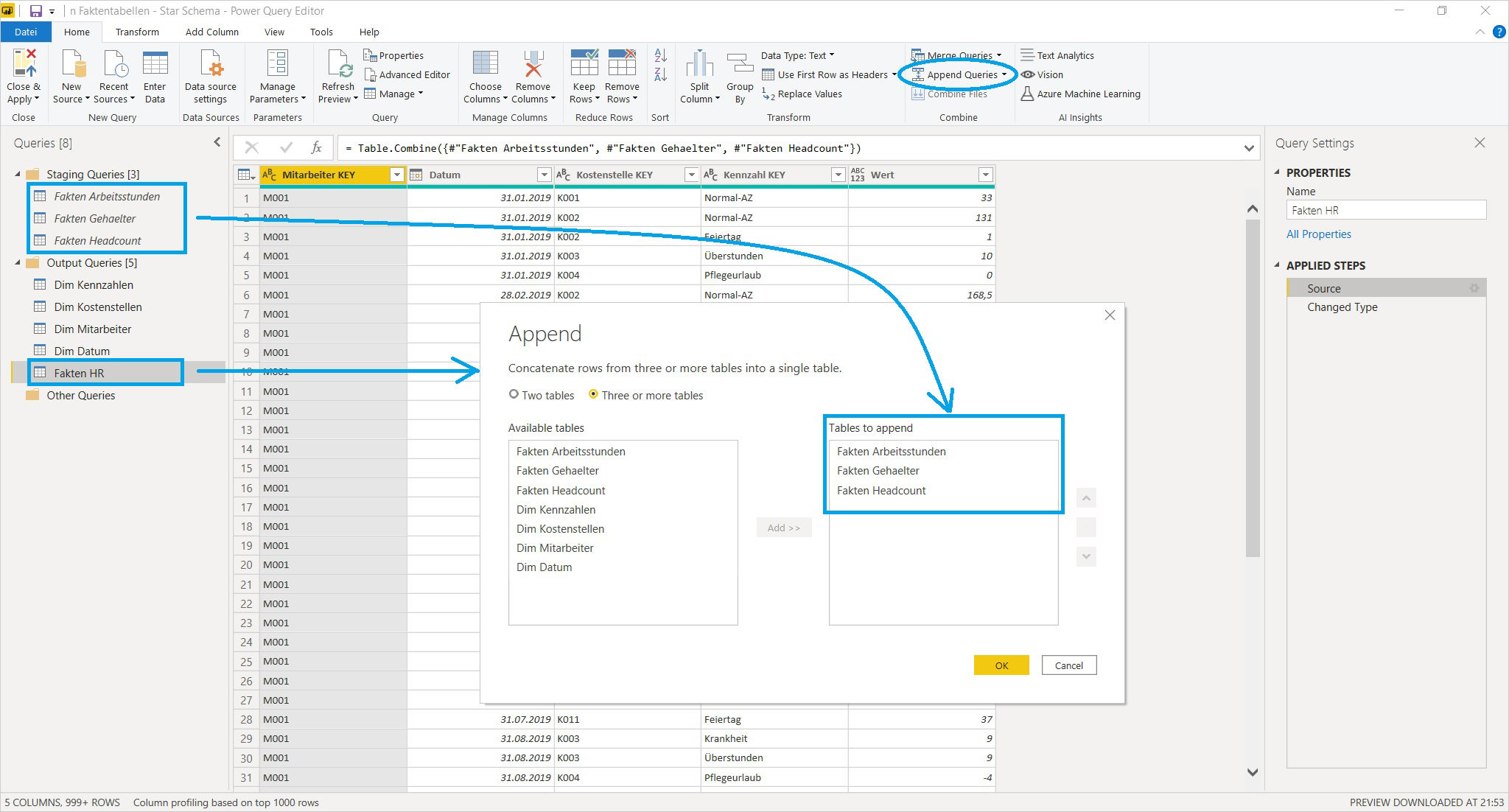
Die Lösung für die Umgestaltung des Datenmodells liegt wieder – wie auch schon im Teil 1 – in der Power Query Komponente von Power BI. Die Queries für die 3 Faktentabellen können mit der Append Queries Funktion „untereinander“ zu einer einzigen Tabelle Fakten HR kombiniert werden. Voraussetzung dafür ist, daß die einzelnen Input-Queries möglichst viele gleichlautende Spalten aufweisen, da die Inhalte aus Spalten mit der gleichen Bezeichnung in die selbe Zielspalte gelangen. In unserem Fall war das bereits von Anfang an gegeben (was diesen Fall recht einfach macht):
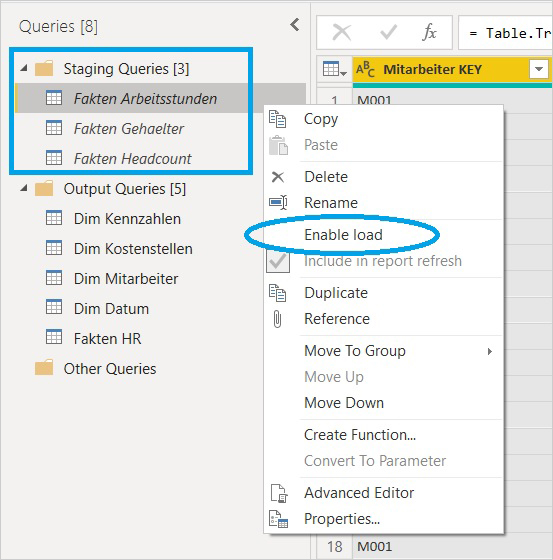
Für die Queries der einzelnen Faktentabellen wird das Setting Enable load jetzt deaktiviert, damit dieses Queries nicht weiterhin ins Datenmodell (zusätzlich zur neuen Tabelle Fakten HR) geladen werden. Sie werden dadurch zu sogenannten Staging Queries, diese Eigenschaft wird hier durch Eingliederung in einen entsprechend benannten Ordner noch unterstrichen (wäre aber auch an der kursiven Schrift des Querynamens zu erkennen):
Jetzt geht es um die Behandlung der Unvollständigkeiten in der integrierten Faktentabelle. Da eine der Quelltabellen keine Kostenstellen-Information beinhaltet, ersetzen wir die entstehenden null Werte durch den sprechenderen Fülltext (ohne) …
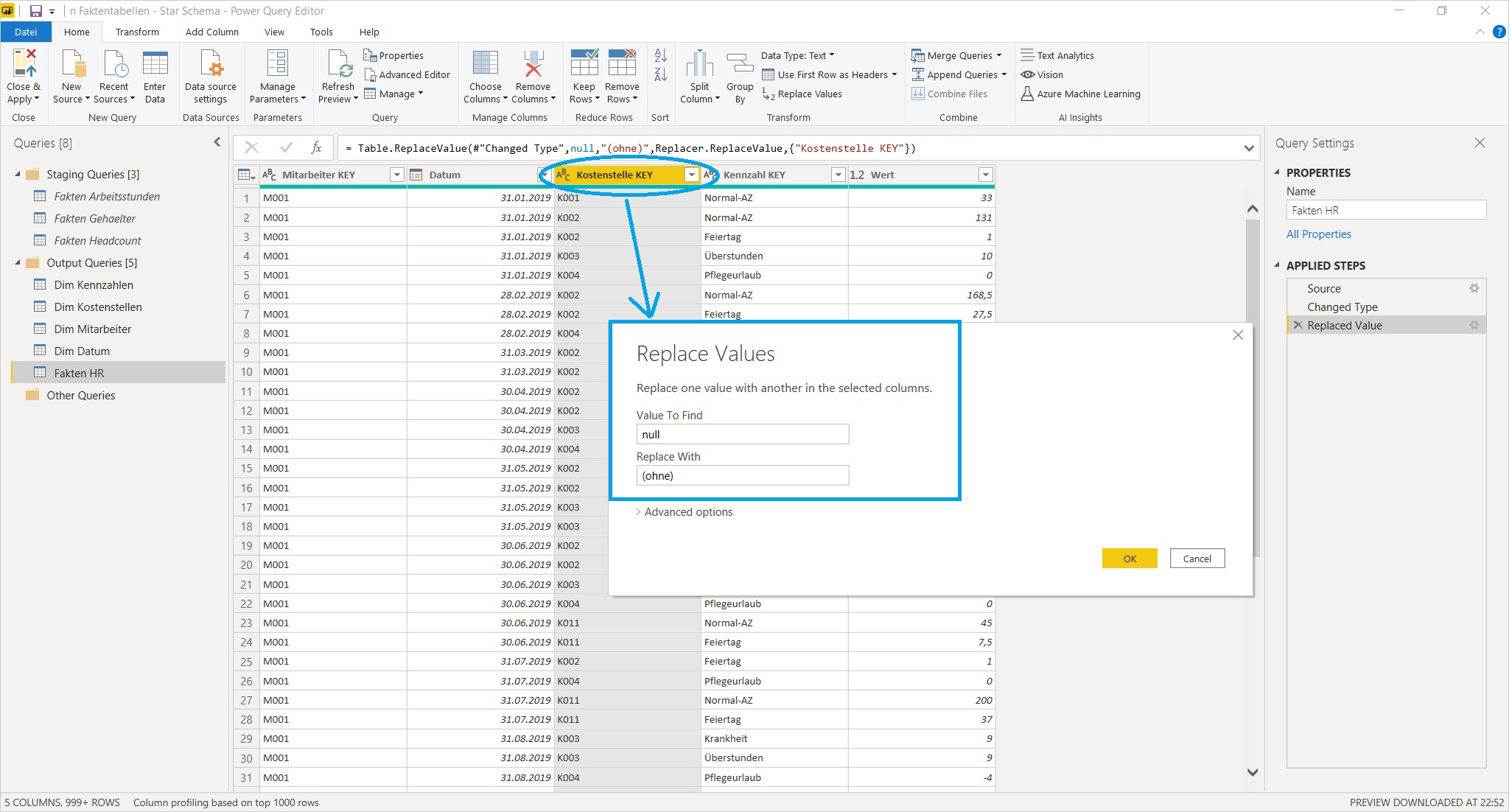
… und ergänzen auch die Kostenstellen-Dimension um einen entsprechenden (ohne)-Definitionsdatensatz (damit in der Dimension keine Blank Row erzeugt wird):

Voalá! Das Datenmodell ist jetzt ein sehr simples Star Schema mit einer einzigen integrierten Faktentabelle im Zentrum und einer sehr übersichtlichen und unkomplizierten Beziehungsstruktur:
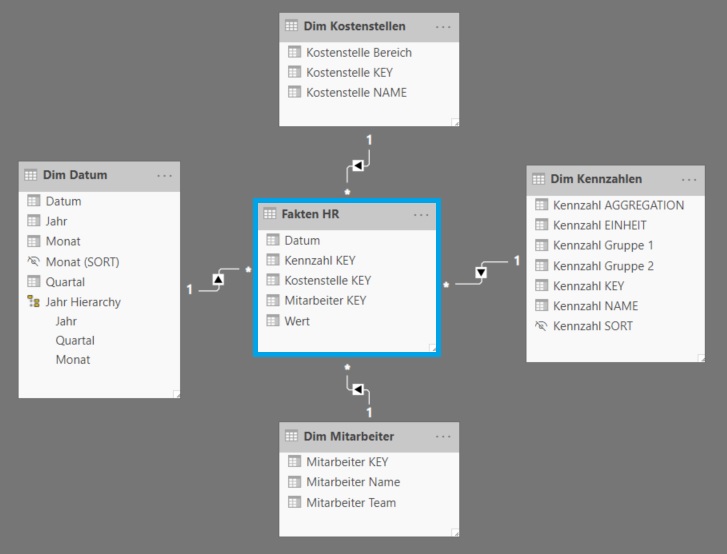
3. Measures und notwendige Aggregationslogik
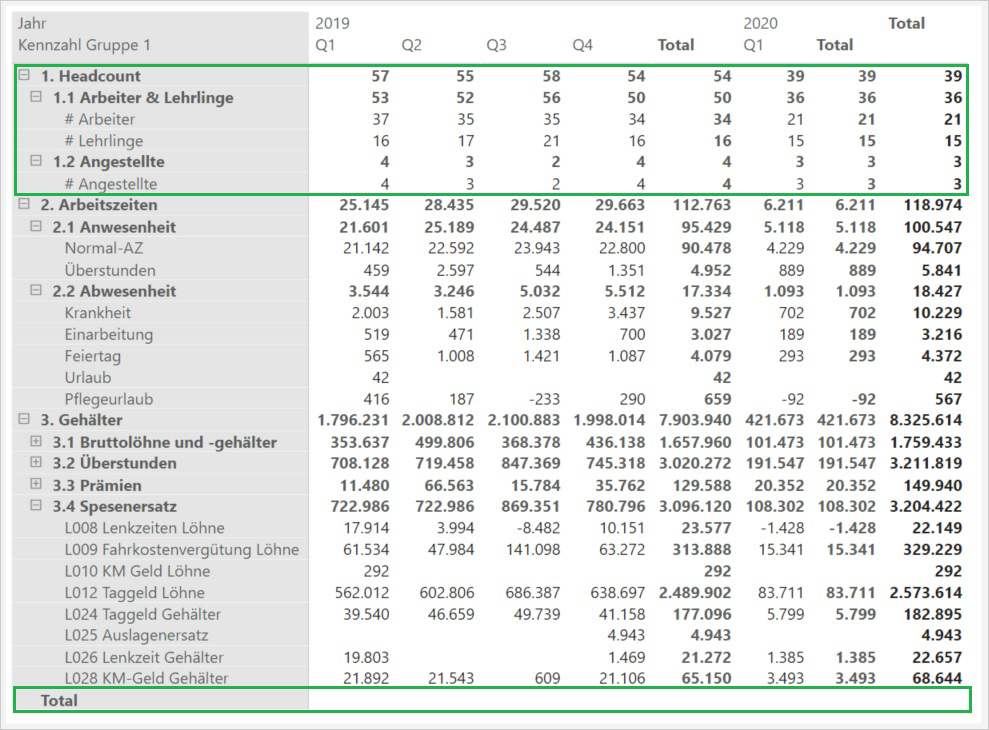
Die Auswertung der Wertspalte der integrierten Faktentabelle mit einem einfachen Summen-Measure ist aber nicht ausreichend:
Wert (sum) =
SUM('Fakten HR'[Wert])Die Summierung der Headcounts auf der Zeitsachse sowie die Ermittlung einer Gesamtsumme aller Kennzahlen muß unterbunden werden:
Daher wird die Kennzahlendimension um ein Feld für die Einheit und ein Feld für den Aggregationsmodus erweitert:
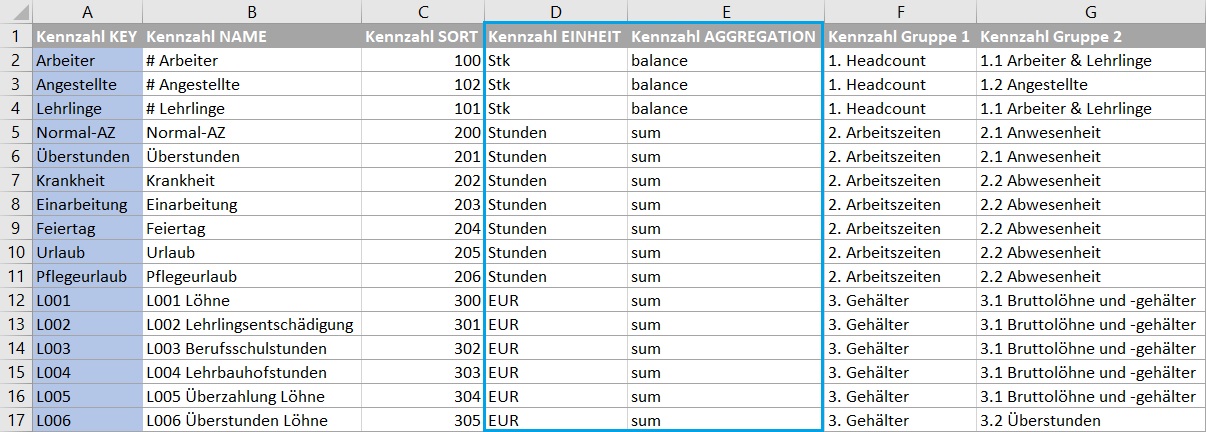
Wie bereits aus Teil 2 bekannt, wird die semi-addtive Bestandslogik durch dieses Measure erreicht, ergänzt wird lediglich die Bedingung für den Aggregationsmodus = balance in der CALCULATE() Funktion:
Wert (balance) =
VAR var_Aktueller_Stichtag =
CALCULATE(
MAX('Fakten HR'[Datum]);
ALL('Dim Kennzahlen');
ALL('Dim Kostenstellen');
ALL('Dim Mitarbeiter')
)
RETURN
IF(
ISBLANK(var_Aktueller_Stichtag);
BLANK();
CALCULATE(
SUM('Fakten HR'[Wert]);
'Dim Kennzahlen'[Kennzahl AGGREGATION]="balance";
DATESBETWEEN('Dim Datum'[Datum];var_Aktueller_Stichtag;var_Aktueller_Stichtag)
)
)Jetzt werden die Teile zusammengefügt: die äußere HASONEVALUE() Bedingung sorgt dafür, daß nur innerhalb der selben Kennzahl EINHEIT aggregiert wird. Die innere SWITCH() Bedingung sorgt dafür, daß für alle Kennzahlen mit dem Aggregationskennzeichen balance das semi-additive Measure und auf alle anderen das Summen-Measure angewendet wird:
Wert (Aggregationslogik) =
IF(
HASONEVALUE('Dim Kennzahlen'[Kennzahl EINHEIT]);
SWITCH(
SELECTEDVALUE('Dim Kennzahlen'[Kennzahl AGGREGATION]);
"balance";[Wert (balance)];
"sum";[Wert (sum)]
);
BLANK()
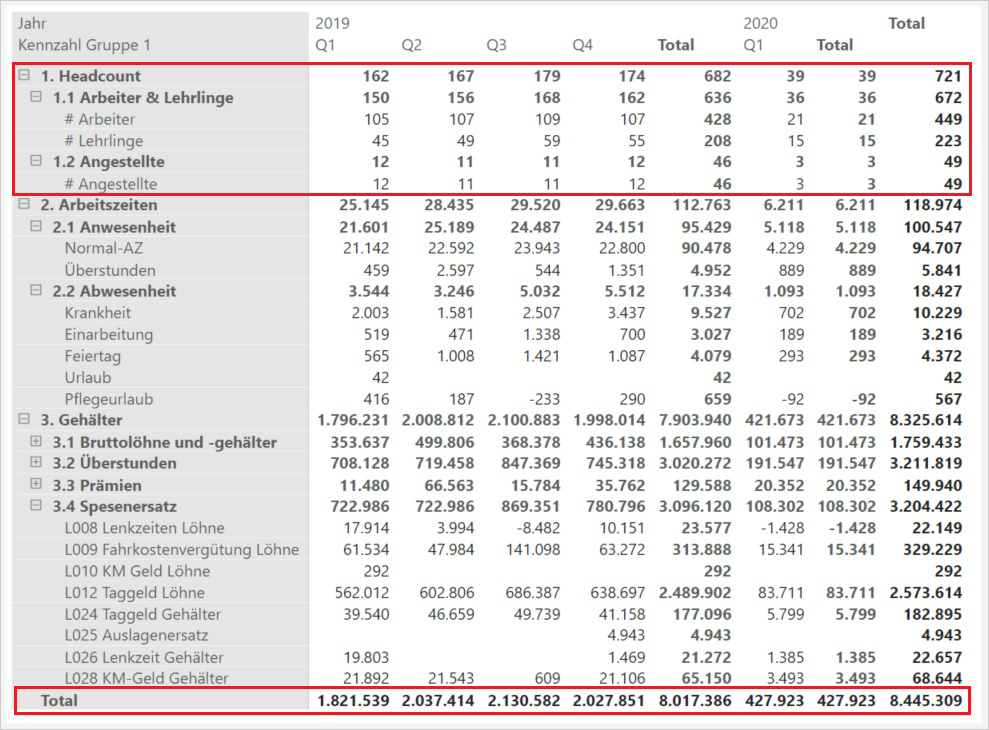
)Jetzt liefert die Aggregation des Kennzahlenkatalogs in allen 3 Abschnitten korrekte Ergebnisse und es wird auch keine Gesamtsumme mehr gebildet:
Eine Grafik kann jetzt beispielsweise durch simple Selektion mit einem Kennzahlen-Slicer frei mit der gewünschten Kennzahl „befüllt“ werden:
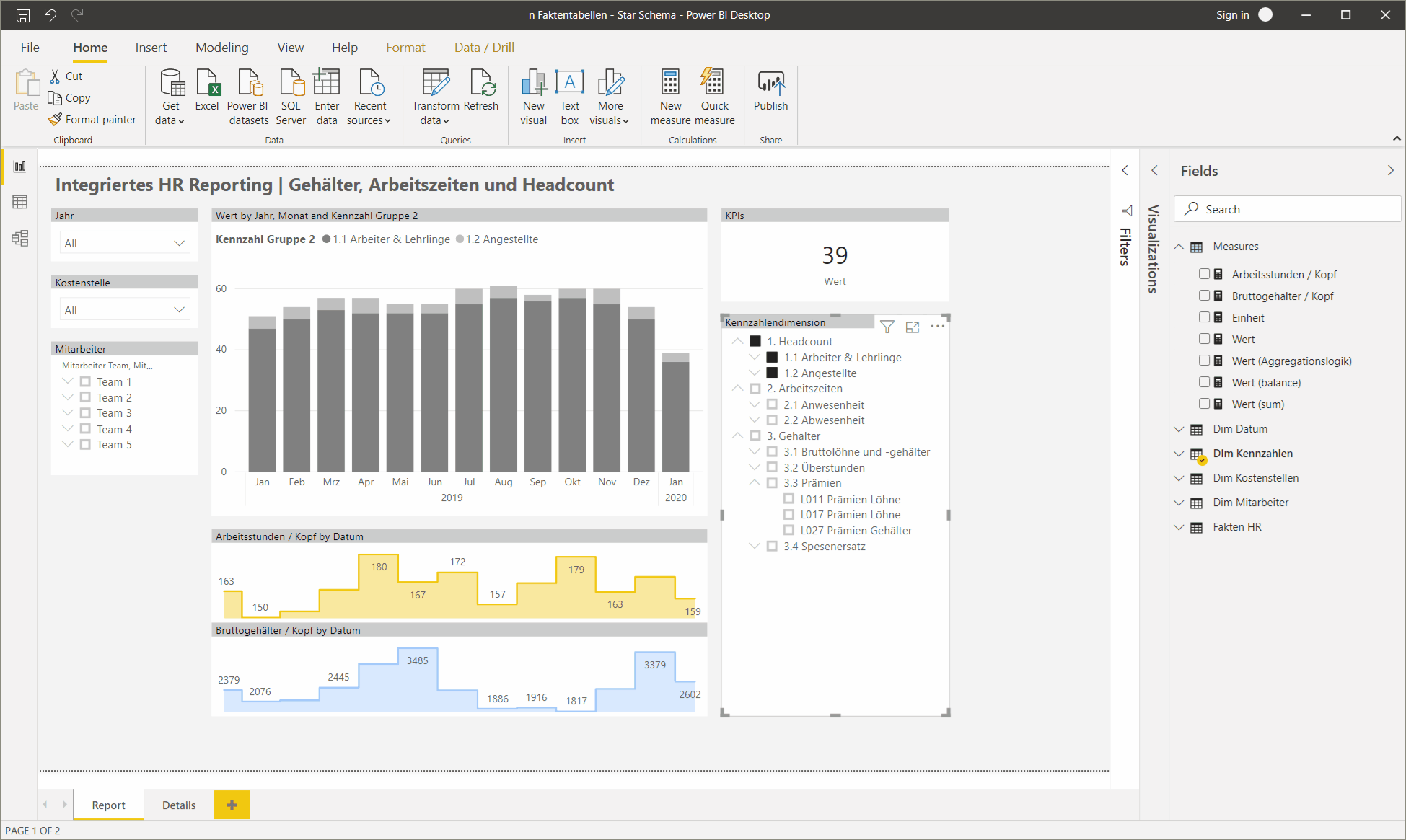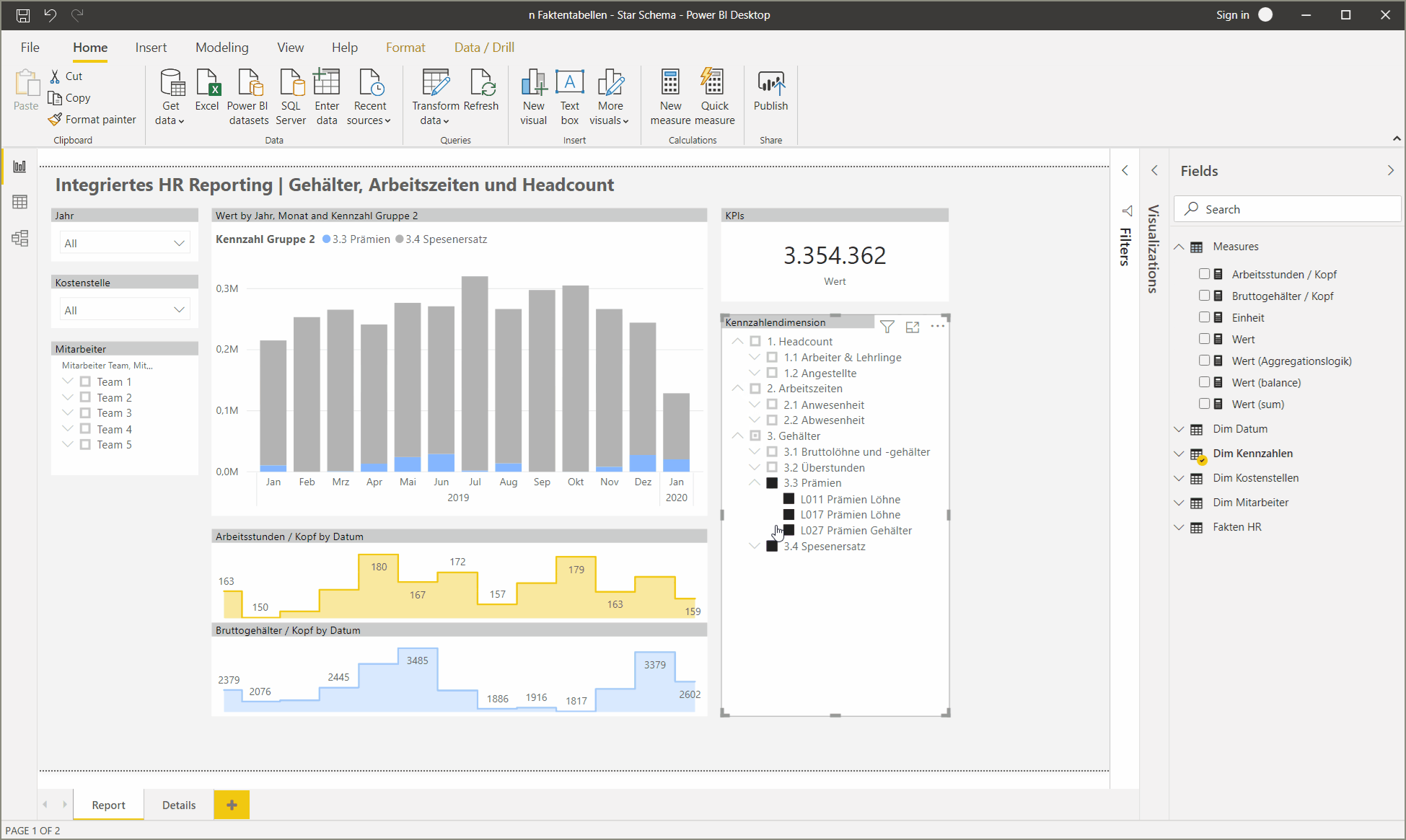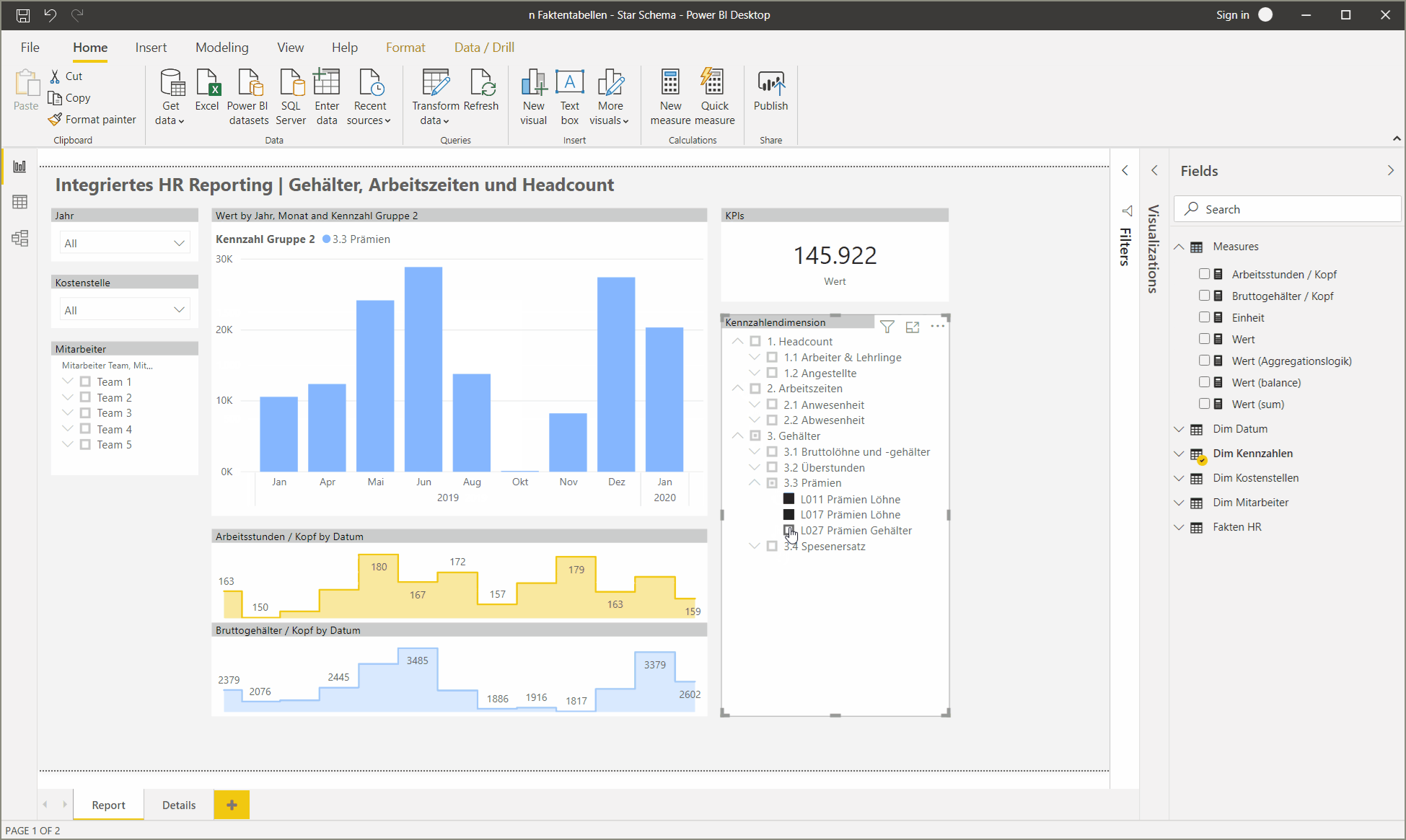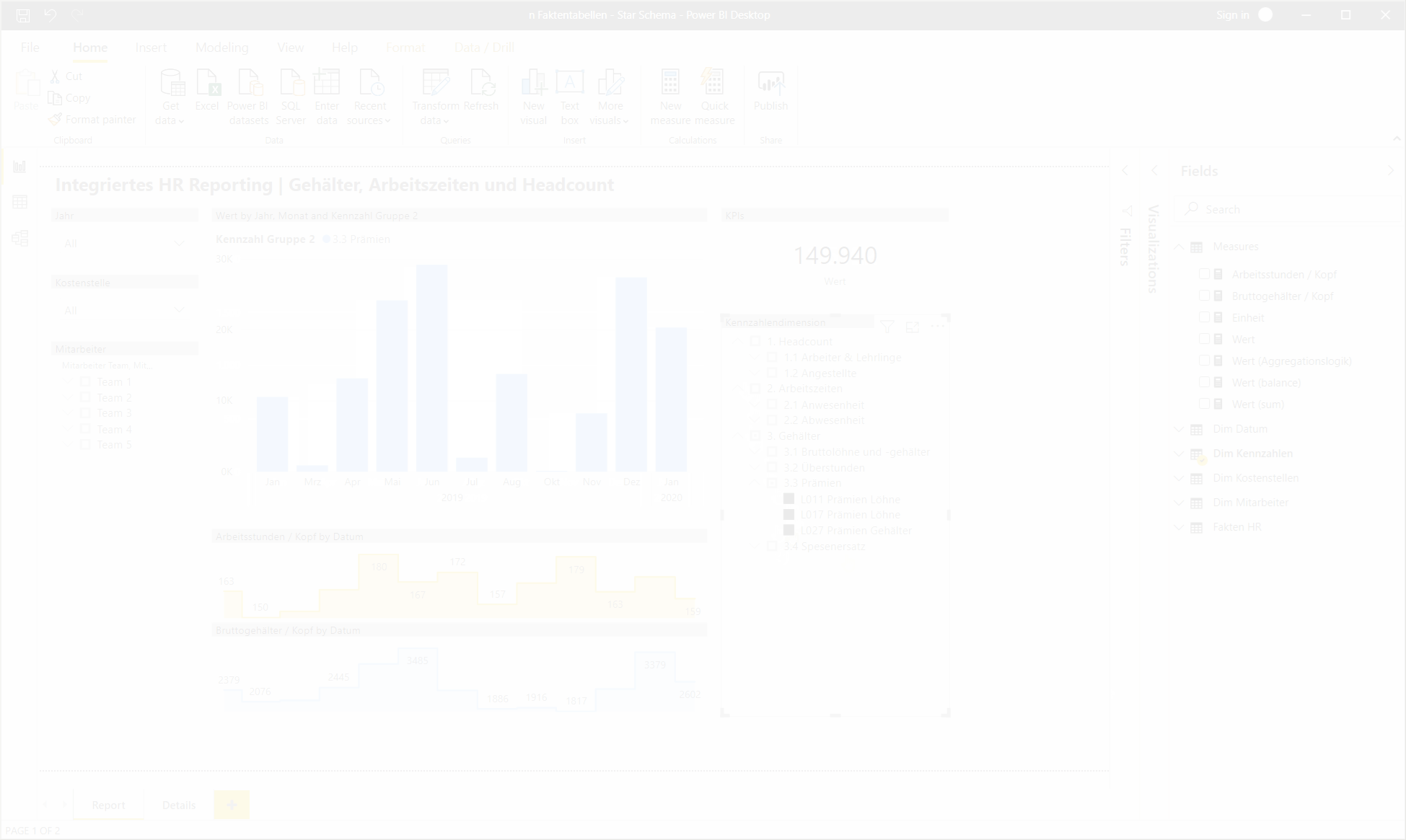
4. Erweiterung der Kennzahlendimension um berechnete Kennzahlen
Im Report oben sind zwei zusätzliche Kennzahlen visualisiert:
Arbeitsstunden / Kopf =
VAR
var_Arbeitsstunden = CALCULATE(
SUM('Fakten HR'[Wert]);
FILTER(
ALL('Dim Kennzahlen');
'Dim Kennzahlen'[Kennzahl Gruppe 1]="2. Arbeitszeiten"
)
)
VAR
var_Kopf = CALCULATE(
SUM('Fakten HR'[Wert]);
FILTER(
ALL('Dim Kennzahlen');
'Dim Kennzahlen'[Kennzahl Gruppe 1]="1. Headcount"
)
)
RETURN
DIVIDE(var_Arbeitsstunden;var_Kopf)Bruttogehälter / Kopf =
VAR
var_Bruttogehaelter = CALCULATE(
SUM('Fakten HR'[Wert]);
FILTER(
ALL('Dim Kennzahlen');
'Dim Kennzahlen'[Kennzahl Gruppe 2]="3.1 Bruttolöhne und -gehälter"
)
)
VAR
var_Kopf = CALCULATE(
SUM('Fakten HR'[Wert]);
FILTER(
ALL('Dim Kennzahlen');
'Dim Kennzahlen'[Kennzahl Gruppe 1]="1. Headcount"
)
)
RETURN
DIVIDE(var_Bruttogehaelter;var_Kopf)Diese beiden Kennzahlen können der Kennzahlendimension als „Calculated Elements“ mit folgendem Trick hinzugefügt werden (da es im Power BI Datenmodell eine solche Funktion bisher nicht gibt): in der Kennzahlendimension werden zwei Hilfszeilen für die beiden Kennzahlen angelegt, die Keys CALC1 und CALC2 können dabei beliebig festgelegt werden, sie müssen lediglich eindeutig sein:

Jetzt wird ein neues Measure Wert angelegt und über eine SWITCH() Bedingung für die beiden CALC-Elemente das jeweilige spezielle Measure und für alle anderen Einträge der Kennzahlendimension das normale Measure mit der Aggregationslogik zugewiesen:
Wert =
VAR var_Zeitraum_Bebucht =
CALCULATE(
MAX('Fakten HR'[Datum]);
ALL('Dim Kennzahlen');
ALL('Dim Mitarbeiter');
ALL('Dim Kostenstellen')
)
RETURN
IF(
ISBLANK(var_Zeitraum_Bebucht);
BLANK();
SWITCH(
SELECTEDVALUE('Dim Kennzahlen'[Kennzahl KEY]);
"CALC1";[Arbeitsstunden / Kopf];
"CALC2";[Bruttogehälter / Kopf];
[Wert (Aggregationslogik)]
)
)Jetzt können die beiden berechneten Kennzahlen ebenfalls über den Kennzahlen-Slicer selektiert und in der Hauptgrafik ausgewertet werden:
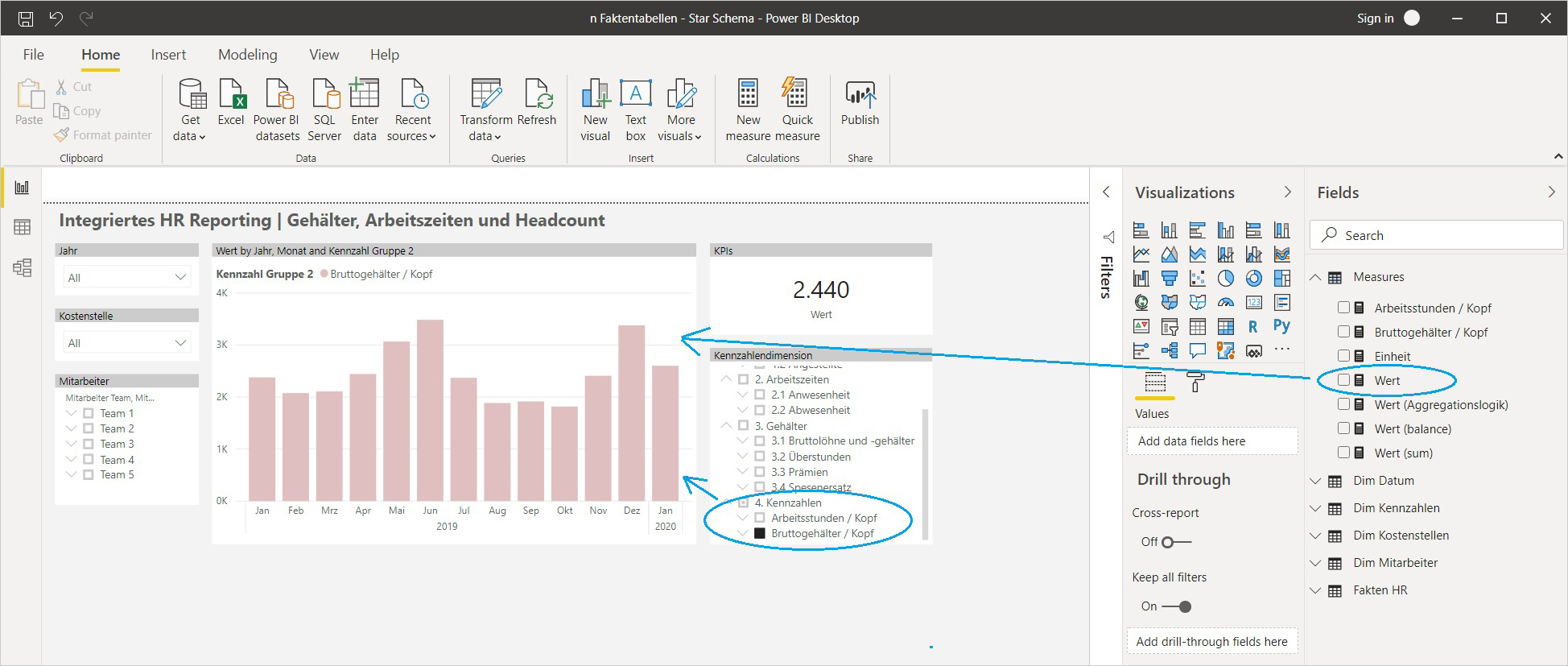
Evaluierung
Die Transformation zum Star Schema mit einer integrierten Faktentabelle löst wesentliche Einschränkungen / Problemzonen des Multi-Fakten Schemas:
1. Vermeidung von Fehlassoziationen bei den Berichtsnutzern durch fehlende Beziehungen
Die Filterung auf eine Kostenstelle in Verbindung mit der unverknüpften Kennzahl Headcount hier zur Anzeige keiner Werte während im Multi-Fakten Schema (wie im Teil 2 gezeigt) die ungefilterten Werte gezeigt werden.

2. Vermeidung des komplexen Beziehungsgeflechts
Die (häufig unterschätzte) Komplexität des Multi-Fakten Schemas fällt weg, bidirektionale Beziehungen können unproblematischer eingesetzt werden und es bleibt Potential für ev. noch kommende komplexe Erweiterungen des Datenmodells für neue Inhalte (bspw. eine Row-Level-Security).
3. Einfachere Skalierbarkeit für weitere hinzufügende Datenbestände
Die Erweiterung um neue Faktentabellen erfordert keine neuen Beziehungen und auch keine neuen Measures, sondern ggfs. nur die Verfeinerung der Ermittlungsregeln in den bestehenden Measures.
Das Modell hat aber auch Schwächen, die ggfs. durch weiterführende Überlegungen oder ggfs. auch durch neue Funktionen in Power BI gelöst werden können:
1. Die tendenziell notwendige unterschiedliche Formatierung von Kennzahlen
Das „Einheits Measure“ kann einheitlich formatiert werden, schöner wäre es aber, wenn auch die Formatierung der Zahlen je nach selektierter Kennzahl differenziert wäre. Beispielsweise snd Stunden mit einem “ h“ nach der Zahl sehr viel sprechender, ebenso Prozentzahlen mit einem “ %“ nach der Zahl. Dies kann grundsätzlich auch mit der FORMAT()-Funktion (und einer weiteren Steuerungsspalte aus der Kennzahlendimension) elegant gelöst werden. Die ungelöste Problematik dabei ist aber, daß die FORMAT()-Funktion einen Text generiert und dieser dann in einem Table, Matrix und Card Visual problemlos dargestellt werden kann, die Visualisierung in einem Chart oder mit einem Conditional Formatting ist dann aber nicht mehr möglich. Eine Lösung liegt in der Anlage von doppelten Measures, optimal ist das aber nicht.
2. Die Selektion von 2 (oder mehr) nicht summierbaren Kennzahlengruppen im Report unterbindet nicht die Visualisierung im gruppierten Säulendiagramm
Das liegt daran, daß in diesem Visual nach Kennzahlengruppe gruppiert wird und daher im Filter Context jedes einzelnen Wertes die HASONEVALUE()-Bedingung für die Abfrage der Einheit gegeben ist, in Summe ergibt das Visual aber bei dieser Selektion keinen Sinn mehr. Eine Lösung mit einem ALLSELECTED() bringt nach unserer Einschätzung hier auch keine Abhilfe. Eine Lösung besteht darin, daß die Gruppierung in einem Chart nicht für die Kennzahlendimension verwendet werden darf.
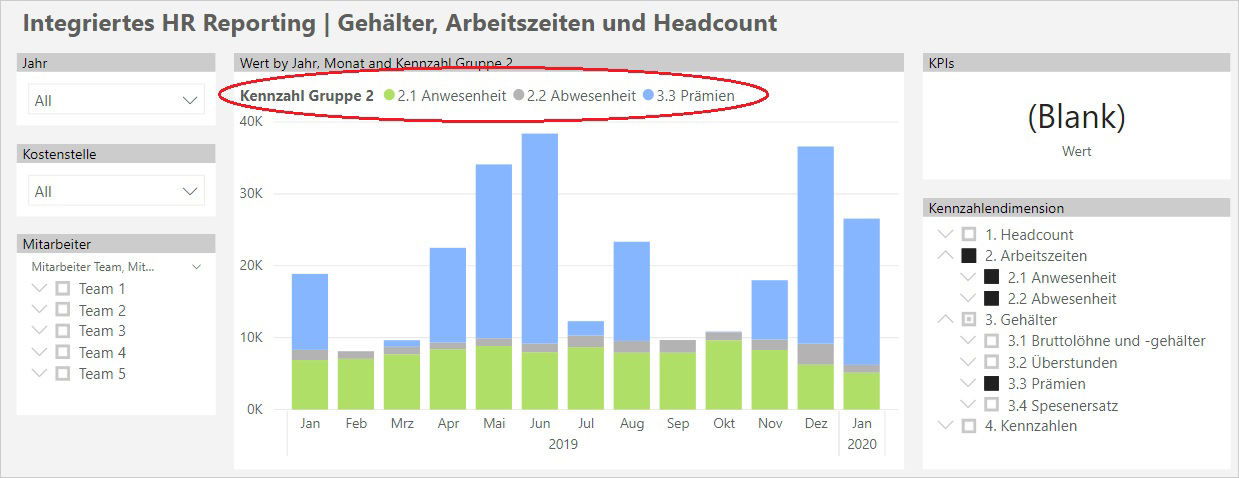
Weiters muß angemerkt werden, daß der Prozess der Zusammenführung von heterogeneren Faktentabellen, die nicht wie im hier gezeigten Fall bereits beinahe identen Spaltenaufbau haben, umfangreiche konzeptionelle Vorarbeiten zum Herauskristallisieren des Sets an gemeinsamen Spalten notwendig machen kann. Auch ist die Benennung der proprietären Faktenattribute nicht trivial, da Felder für 1 oder mehrere (aber eben nicht alle) Faktentabellen Relevanz haben können. Weiters müssen die entstehenden Leerfelder aufgrund fehlender Beziehungen (wie oben gezeigt) mit möglichst sprechenden Füllwörtern belegt werden.
Für die Praxis haben wir folgende Entscheidungshilfe: Haben die Faktentabellen nur die Zeitdimension gemeinsam, dann sollte besser ein Multi-Fakten Schema realisiert werden. Je mehr gemeinsame Dimensionen die Faktentabellen haben und je wichtiger die gemeinsame Auswertung in einer Kennzahlendimension ist, desto eher kann und sollte der hier vorgestellte Modellierungsansatz eingesetzt werden. Das Ergebnis ist nach unserer bereits jahrelangen Praxiserfahrung mit diesem Modellierungsansatz den Einsatz immer wert.