Der Incremental Refresh ermöglicht es, große Datenanwendungen im Power BI Cloud Service „wachsen“ zu lassen mit dennoch kurzen (bspw. täglichen) Aktualisierungsvorgängen. Neben der kurzen Aktualisierungszeit spielt aber auch die Schonung von (Cloud-)Ressourcen an der Datenquelle ein Rolle, da beim (täglichen oder mehrfach täglichen) Full Load massiv Ressourcen verschwendet werden.
Im Teil 1 dieser Blogserie habe ich die die Aktivierung und die Funktionsweise des Incremental Refresh vorgestellt, in diesem Teil 2 geht es um die folgenden Fragestellungen aus der täglichen Praxis:
- Aktivierung des XMLA Endpoints für READ/WRITE
- Refresh I: Aussetzer beim Refresh
- Refresh II: manueller Refresh der historischen Partitionen
- Refresh III: Timeout beim initialen Load
- Development Lifecycle I: Download der PBIX-Datei nicht mehr möglich
- Development Lifecycle II: Vorsicht beim Upload einer neuen PBIX
- Development Lifecycle III: Update mit dem ALM Toolkit
- Wartung: (De-)Fragmentierung der Partitionen
Aktivierung des XMLA Endpoints für READ/WRITE
Im Teil 1 wurde bereits der XMLA Endpoint vorgestellt. Dabei handelt es sich aktuell um ein Power BI Premium Feature, das zwar keine Voraussetzung für die Nutzung des Incremental Refresh darstellt, aber einige Bearbeitungsoptionen eröffnet. Der XMLA Endpoint sollte für READ/WRITE aktiviert werden (Default = READ only):

Refresh I: Aussetzer beim Refresh
Eine praktische Frage tut sich auf, wenn der automatische Refresh bspw. kurz vor Monatsende ausfällt (hier: 29.11.2022) und der nächste Refresh erst wieder nach dem Monatswechsel (hier: 02.12.2022) stattfindet. Wird dann das vorangegangenge – unfertige – Monat nochmals aktualisiert oder wird die Aktualisierungsregel stur ausgeführt und nur das laufende Monat (hier: Dezember) importiert?

Glücklicherweise müssen wir uns in diesem Fall nicht um den Refresh des unfertigen Vormonats kümmern, da Power BI automatisch auch die Vormonats-Partition aktualisiert:

Hier zur Einstimmung auf den nächsten Punkt auch die Sicht auf die Tabellenpartitionen im SQL Server Management Studio (SSMS) über den XMLA Endpoint (siehe dazu auch Teil 1):

Refresh II: Manueller Refresh der historischen Partitionen
Interessant ist auch die Frage, wie eine bereits abgeschlossene Partition bei Bedarf doch nochmals aktualisiert werden kann, weil bspw. im Quellsystem ein Fehler in den Daten korrigiert wurde. Nach unserem Wissensstand ist derzeit die gezielte Aktualisierung einzelner Partitionen nur über den XMLA Endpoint im SQL Server Management Studio möglich.
Im Teil 1 wurde bereits gezeigt, wie der Zugriff auf die Partitionen einer Power BI Tabelle erfolgt:

Dort wird die gewünschte Partition selektiert und mit dem Process Button …

… wird der Process Partition(s) Dialog gestartet. Der Verarbeitungsmodus sollte unbedingt auf Process Full geändert werden, um einen Full Load der Partition zu erzwingen und damit kein Risiko einer unvollständigen Datenaktualisierung einzugehen:
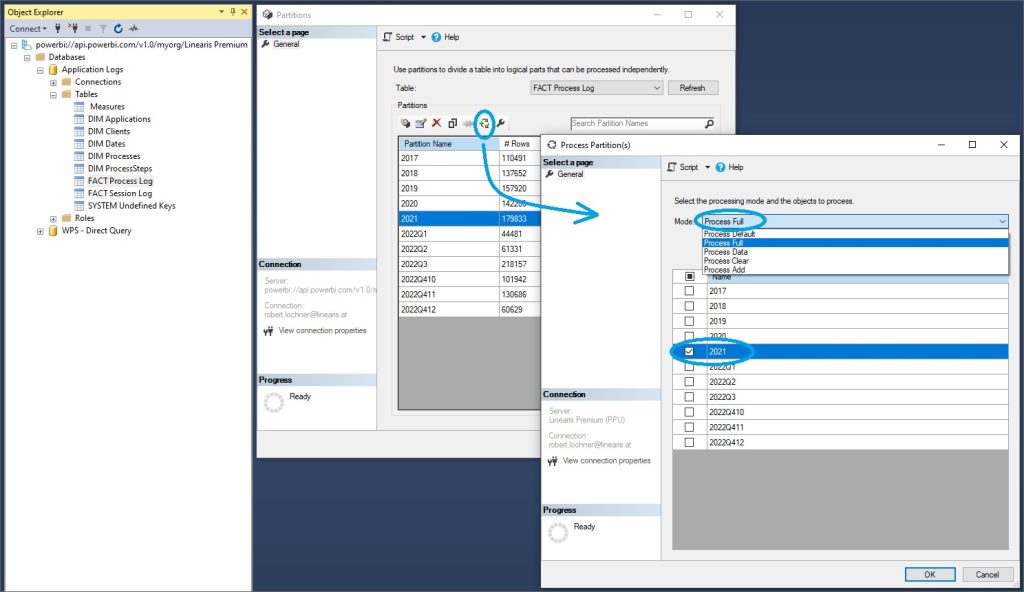
Leider hat dieser Vorgang – trotz zahlreicher Versuche – bei uns bisher aufgrund der folgenden Fehlermeldung nicht funktioniert:

Genau zu dieser Fehlermeldung wird in diesem Video von Guy in a Cube ein Lösungsweg gezeigt, der aus folgenden Schritten besteht:
Zuerst sollte der Cache des SSMS gelöscht werden. Vielleicht liegt hier mein Fehler, da die Cache Datei zwar gelöscht werden kann, aber von Windows nach kurzer Zeit wiederhergestellt wird.
Danach erfolgt die Verbindung ohne dem Dataset-Namen, der Abschnitt Initial Catalog wird aus dem XMLA Endpoint URL entfernt:

Im Anmeldedialog wird unter Options sichergestellt, daß als Datenbank „<default>“ ausgewählt ist:

Wie gesagt, hat dieser Lösungsweg bei mir leider nicht zum Erfolg funktioniert. :(
Falls jemand die Lösung kennt, bitte unten in den Kommentar posten!
Weiterführend:
Refresh III: Timeout beim initialen Load
Falls der initiale Load länger als 2 Stunden (Pro Lizenz) oder länger als 5 Stunden (Premium Lizenz) dauert, dann bricht dieser Ladevorgang mit einem Timeout ab.
„Guy in a Cube“ stellen folgende Lösung für diese Themati vor:
- Setzen eines Filters in Power Query oder im SQL Quellview, sodaß keine Daten zurückgegeben werden
- Upload der PBIX und Ausführung des initialen Loads (= keine Datensätze in der Anwendung, aber alle Partitionen sind jetzt angelegt)
- Entfernen des Filters im Quellview bzw. in Power Query mittels Metadata-Update mit dem ALM-Toolkit
- Processing der einzelnen Partitionen im SQL Server Management Studio (mittels XMLA-Endpoint -> nur in PBI Premium verfügbar) mit der Option „Process Data“
- Processing der Anwendung mit der Option „Process Recalc“
- Start des (bspw. täglichen) inkrementellen Loads
Avoid the full refresh with Incremental Refresh in Power BI (Premium)
Development Lifecycle I: Download der PBIX-Datei nicht mehr möglich
Sehr wichtig ist die Erkenntnis, daß von einer Anwendung mit aktivem Incremental Refresh …

… aus dem Power BI Cloud Service nur noch die Report-Anwendung heruntergeladen werden kann, nicht aber die Dataset-Anwendung:

Das hat zur Folge, daß die originale PBIX-Entwicklungsdatei keinesfalls verloren gehen darf, da sonst die Dataset-Anwendung (= Queries + Datamodel) nicht mehr weiterentwickelt werden könnte.
Development Lifecycle II: Vorsicht beim Upload einer neuen PBIX
Wird die originale PBIX-Entwicklungsdatei weiterentwickelt und „ganz normal“ über die Publish Funktion in den Cloud Service hochgeladen, dann wird der gewachsene Datenstand im Power BI Cloud Service gelöscht mit dem (stark) beschränkten Datenstand aus Power BI Desktop überschrieben:

Beim initialen Refresh im Power BI Cloud Service werden dann – wie bereits in Teil 1 dargestellt – wieder alle Daten geladen. Bei großen Anwendung kann dieser initiale Refresh aber viel Zeit in Anspruch nehmen und die Anwendung für mehrere Stunden außer Betrieb setzen. Weiters ist es möglich, daß aufgrund der Beschränkung bei der Refresh Zeit im Power BI Cloud Service nicht mehr das ursprüngliche (= gewachsene) Datenvolumen errreicht werden kann!
Development Lifecycle III: Update mit dem ALM Toolkit
Das ALM Toolkit (ALM = Application Lifecycle Management) ist ein kostenloses Community Tool, mit dem genau diese Entwicklungsthematik gelöst wird. Die Änderungen in der lokalen PBIX-Entwicklungsdatei (= Source) werden mit dem ALM Tookit auf die produktive Anwendung im Power BI Cloud Service (= Target) als Metadaten aufgeschalten, ohne die Daten aus der PBIX-Datei mit hochzuladen.
Das ALM Toolkit kann am einfachsten über das External Tools Menü aufgerufen werden, eine Anleitung zur Aktivierung in Power BI Desktop habe ich hier beschrieben.

Beim Aufruf wird automatisch die aktuell in Power BI Desktop aktive Anwendung als Source eingetragen. Als Target wird die XMLA Endpoint URL (ohne „Initial Catalog“) eingesetzt und die produktive Zielanwendung ausgewählt:
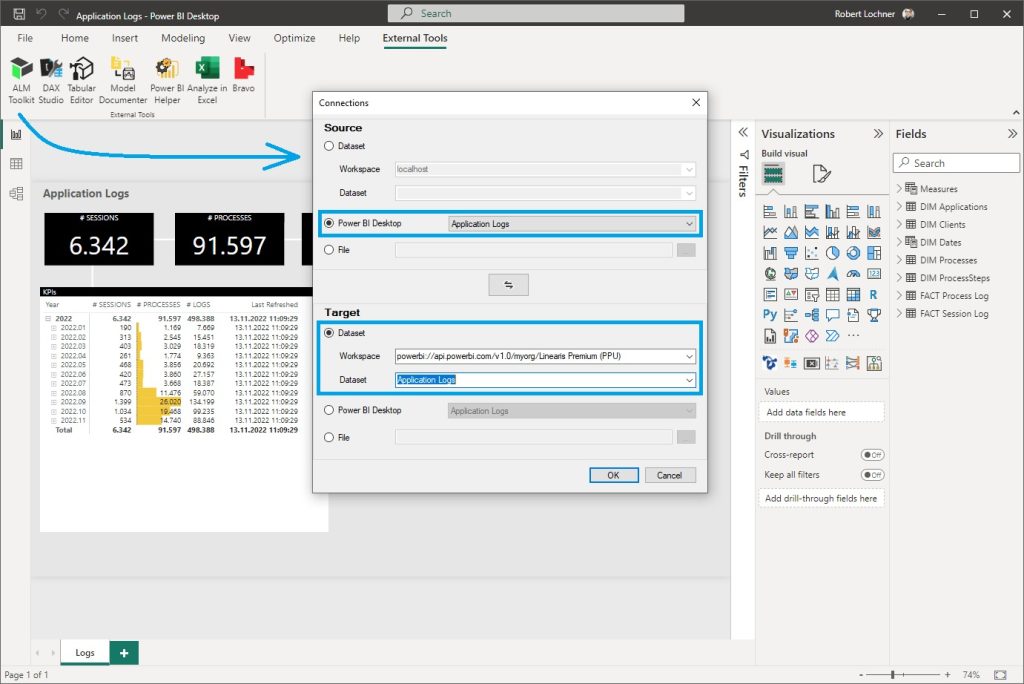
Mit der Funktion Compare wird ein Abgleich der Metadaten der beiden Anwendungen vorgenommen, hier gibt es noch keine Unterschiede und daher auch keine Actions.

Jetzt müssen zuerst die Options angepaßt werden, damit beim Update der Datenstand im Target Dataset nicht verändert wird. Besonders wichtig ist dabei die Processing Option Do Not Process:

Zum Test wird jetzt ein Measures in der PBIX-Entwicklerdatei verändert, nach der neuerlichen Ausführung des Compare wird der Unterschied in der Measure Definition erkannt und als Action ein Update vorgeschlagen:

Jetzt muß ein Validate Selection ausgeführt werden, damit der Update Button aktiv wird und betätigt werden kann:

Nach dem Start des Updates mit OK werden die geänderten Metadaten aus der Source Anwendung auf die Target Anwendung aufgeschalten:

Die neuerliche Ausführung des Compare zeigt jetzt, daß nach dem Update die beiden Measures ident sind, das Update hat also tatsächlich funktioniert:

Weiterführend:
Wartung: (De-)Fragmentierung der Partitionen
Chris Webb zeigt in diesem sehr interessanten Blogbeitrag, daß die Größe von Datasets mit aktivem Incremental Refresh überproportional anwachsen kann. Daher sollte in (großen) Datasets mit Incremental Refresh regelmäßig
{
"refresh": {
"type": "defragment",
"objects": [
{
"database": "Datasetname",
"table": "Tabellename"
}
]
}
}Praktisch wird im SQL Management Studio (SSMS) eine XMLA Query erstellt, das XMLA Statement eingefügt und an die Namen der konkreten Anwendung angepaßt:

Jetzt wird die XMLA Query mit dem Befehl Execute ausgeführt, die Ausführung dauert hier 21 Sekunden:

Weiterführend:
Fazit
Der Incremental Refresh ist unter der Haube ein komplexes Feature, das aber dank Power BI recht einfach genutzt werden kann. Im praktischen Betrieb einer solchen Anwendung ergeben sich einige Themen, die uns jedenfalls bewußt sein müssen, für die es aber recht gute Lösungen gibt. Eine Power BI Premium Lizenz ist zwar keine zwingende Voraussetzung, kann aber bei größeren Anwendungen aufgrund der Verfügbarkeit des XMLA Endpoints ein schwer verzichtbares Feature darstellen.